大数据文摘编辑组出品
今天凌晨,OpenAI通过官方博客宣布了其在Dota对抗上的新进展——由五个神经网络组成的团战AI团队,在5v5中击败了业余人类玩家,并表示,将有望挑战顶级专业团队。
打Dota乍一听可能没什么了不起的,但这可以被视作AlphaGo的延续:构建可以在看似简单的游戏中击败人类的机器。
OpenAI干了这么一件事:组织了5个神经网络构成团队,在5v5游戏中击败了Dota 2的人类业余选手。他们的目标是在8月份击败国际顶级专业团队(仅限一组英雄的条件下)。
OpenAI也给了这个能力x5的AI一个简单易懂的名字——OpenAI Five!
OpenAI是Elon Musk联合创立的非盈利AI研究机构,旨在提高人们对AI技术现在所处的位置的认识,以及促进科技的安全进步。这不是OpenAI首次公开试玩Dota 2,去年,OpenAI在Dota2 1v1比赛中战胜了人类选手Dendi。
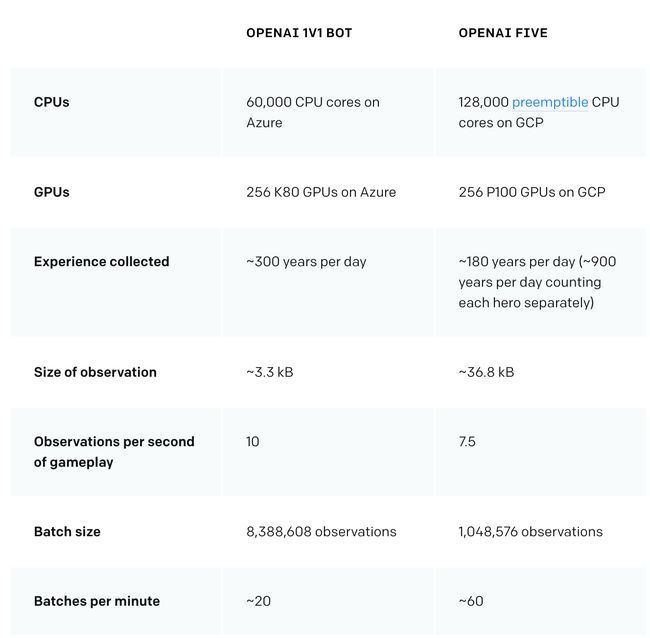
OpenAI Five的训练量级非常大,每天都会玩相当于180年时长的游戏,通过自我对决来学习。它使用在256个GPU和128,000个CPU内核上运行的扩展版近端策略优化进行训练,这是OpenAI去年发布的1v1 Dota AI的更大规模版本【超链接 https://mp.weixin.qq.com/s/5Vg9RFvyNv6T7QkIfPm1aQ】。对每个英雄使用单独的LSTM并且不使用人类数据,由此学习可识别的策略。
从Deep Blue到AlphaGo,再到现在的Dota2,将人工智能与人类之间进行较量,一直是计算机科学领域的有趣传统。
与围棋和国际象棋等回合制的游戏模式不同,Dota2更需要大量的实时决策以及队友之间的默契合作。还记得AlphaGo与柯洁那场围棋之战么,人工智能在运筹帷幄的时候总有几分钟的思考时间。但是如果你在Dota2中静止深思,那么你可能会被对手gank。OpenAI表示,游戏的平均运行时间为每秒30帧,也就是说,在平均45分钟的游戏中会产生大约80000帧,而AI大约分析了其中的四分之一。
OpenAI技术细节

问题描述
在星际争霸或者Dota这样复杂的视频游戏中超越人类的能力,是人工智能发展的里程碑。相对于之前的AI在国际象棋或围棋上的里程碑式进步,复杂的视频游戏更能够效仿现实世界的混乱和连续性。具有很高的通用性,在游戏之外也有可用之处。
Dota 2是一款实时战略游戏,由两名玩家组成,每个玩家控制一个称为“英雄”的角色。玩Dota的AI必须掌握以下几点:
1.长时间。Dota游戏以每秒30帧的速度运行,平均时间为45分钟,每场游戏产生80,000帧。大多数行为(例如命令英雄移动到某个位置)单独产生较小的影响,但回城等一些个别行为可能会在战略上影响游戏。一些策略可能贯穿游戏全程。OpenAI Five每四帧观察一次,产生20,000次移动。国际象棋通常在40次移动之前结束,围棋在150次移动之前结束,几乎每一次移动都是战略性的。
2.不完整信息。单位和建筑物只能看到他们周围的区域。地图的其他部分隐藏在雾中,隐藏了敌人和他们的战略。AI需要根据不完整的数据进行推断,并且需要对对手行为建模。象棋和围棋都是全信息游戏。
3.动作高度连续。在Dota中,每个英雄可以采取数十个动作,许多动作都是针对另一个单位或地面上的某个位置。OpenAI将每个英雄的空间分割成170,000个可能的行动(不是在每个帧都有效,比如冷却动作);不计算连续部分,每帧平均有大约1000次有效操作。国际象棋中的平均动作数为35,围棋中是250。
4.高维度、连续的观察空间。Dota包含十个英雄,数十个建筑物,几十个NPC单位以及诸如符文、树木等一大堆游戏特征,和大型连续的地图。AI通过Bot API观察游戏,被允许观察2万个数值(人类所被允许观察的所有值)。国际象棋棋盘有大约70个枚举值(一个8x8的棋盘,6种棋子类型和少量历史信息),一个围棋棋盘有约400个枚举值(一个19x19的棋盘,两种棋子类型加上“劫”)。
此外,Dota规则也非常复杂。游戏开发已经持续了十多年,游戏逻辑在数十万行代码中实现。这个逻辑需要几毫秒的时间才能执行,而国际象棋或围棋引擎则需要几纳秒。游戏也每两周更新一次,不断改变环境语义。
方法
OpenAI系统使用大规模版本的Proximal Policy Optimization进行学习。 OpenAI Five和我们早期的1v1机器人都完全从自我对抗中学习。他们从随机参数开始,不使用来自人类玩家的回放视频进行搜索或引导。
强化学习研究者通常认为,对于长时空上的建模,需要全新的算法,比如分层强化学习。但是OpenAI的结果表明,只要采取合理的方式,目前的算法在大规模资源上运行的结果还不错。
AI经过训练可以通过指数衰减因子γ进行加权,从而最大化指数衰减的未来奖励总和。在最新的OpenAI Five训练中,衰减因子γ从0.998(评估未来奖励的半衰期为46秒)增大到0.9997(评估未来奖励的半衰期为五分钟)。对比而言,PPO这篇论文上最长的推理时间是0.5秒,Rainbow论文上最长的推理时间是4.4秒,Observe and Look Further这篇论文使用的半衰期为46秒。
PPO论文:https://arxiv.org/abs/1707.06347
Rainbow论文:https://arxiv.org/abs/1710.02298
Observe and Look Further论文:https://arxiv.org/abs/1805.11593
进入公众号后台回复“Dota”获取论文~
尽管当前版本的OpenAI Five在最后一击时表现不佳,但是专业Dota评论员Blitz认为OpenAIFive的表现可以比得上一般的人类玩家。
原因是,OpenFive在游戏中对收益的取舍和顶尖的战略决策类似。例如,短期内“补兵”可以获得金钱,而准备团战推塔可能花费更多的时间。如果选择团战,就会丧失小兵收益,然而在胜利以摧毁防御塔为前提的游戏中,放弃团战可能不是明智的选择。所以,AI是朝着长期目标进行优化的。
OpenAI仍需要一些限制条件,比如,和AI比赛的人类对手必须遵守某些规则,包括不使用某些物品和策略。
OpenAI将在下个月举办一场Dota 2巡回赛,展示自己在与顶级玩家竞争时的实力。
当然,也没必要过度担心,因为这个AI虽然可以打Dota,但也只能做这一件事。
相关报道:
https://blog.openai.com/openai-five/
https://techcrunch.com/2018/06/25/openais-dota-2-neural-nets-are-defeating-human-opponents/