Named Data Networking: ndnsim (四):ChronoSync同步协议
Zhenkai Zhu and Alexander Afanasyev
University of California, Los Angeles
{zhenkai, afanasev}@cs.ucla.edu
**翻译自http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.711.2288&rep=rep1&type=pdf
**
版权归原作者所有,翻译仅供学术参考,严禁进行任何形式传播或转载
The copyright belongs to the original author, the translation is for academic reference only, and any form of dissemination or reprint is strictly prohibited.
**
- 摘要
**
在支持许多分布式应用程序(如群组文本消息传递,文件共享和联合编辑)时,基本要求是对数据集的知识(如文本消息,对共享文件夹的更改或文档编辑)进行高效稳健的同步。 我们提出Chrono-Sync协议,该协议利用命名数据网络体系结构的特性来高效地同步分布式用户组中的数据集状态。 使用适当的命名规则,ChronoSync以浓缩的加密摘要形式总结数据集的状态并在分布的各方之间交换它。 数据集的差异可以从摘要中推断出来并有效地传播给各方。 有了数据集更改的完整和最新的知识,应用程序可以决定是否或何时获取哪些数据。我们将ChronoSync作为C ++库实现,并基于此开发了两个分布式应用程序原型。 我们通过模拟显示ChronoSync在同步数据集状态下是有效和高效的,并且可以有效抵御数据包丢失和网络划分。
**
I. 介绍
**
文件共享,群发短信和协作编辑等应用在我们的生活中扮演着越来越重要的角色。 许多此类应用程序要求多方之间的数据集(文件修订,文本消息,编辑操作等)的高效和可靠同步。 自互联网早期以来,研究界一直致力于分布式系统同步[1]并且产生了丰富的解决方案文献。 另一方面,Dropbox和Google Docs等一些流行的应用程序是基于集中式范例实现的,它通常会简化应用程序设计并带来许多其他优点,但也会导致单点故障和集中控制数据。与此同时,许多不同的点对点解决方案[2],包括最近宣布的BitTorrent Sync服务[3]表示搜索高效数据集同步解决方案的另一个方向,这需要维护复杂的对等网络覆盖结构或参与者集中的关键节点。最近提出的通信范例,命名数据网络(NDN)[4],其中数据是第一级的实体,数据的组播自然得到支持,为以有效的方式解决数据集同步问题提供了新的机会。 因此,我们提出ChronoSync,一种有效且强大的协议,用于在NDN中的多方之间同步数据集状态。 ChronoSync的核心思想是对状态进行紧凑编码将数据集转换为我们称之为状态摘要的密码摘要形式(例如,SHA256)或摘要,并在同步组中的所有参与者之间交换状态摘要。 每一方都根据他们对数据集的了解计算出各自的状态摘要的广播兴趣,并将其发送给该组中的所有其他人。 这些兴趣直接在小型网络中广播,并通过大型网络中的简单覆盖进行广播。1 如果传入兴趣中携带的状态摘要与本地维护的状态摘要相同,则表明与数据集相同的知识,则不需要收件人执行任何操作。 否则,两个动作中的一个将被触发:
- 如果状态摘要与先前的本地状态摘要中的一个相同,则可直接推断并发送数据集状态的差异作为对同步兴趣的响应
- 如果状态摘要未知(例如,从网络分区恢复时),则使用状态协调方法来确定知识的差异
行动将被触发以消除数据集状态的差异,直到来自各方的兴趣包持有相同的状态摘要
本文的其余部分安排如下。 我们首先简要介绍一下NDN架构II。 本文的主要贡献在于ChronoSync协议的设计,如章节中所示III,它利用NDN体系结构的特性来高效地同步分布式用户组中的数据集状态。 部分IV 和部分V 演示ChronoSync的实施和评估结果。 讨论和相关工作将在本节中介绍VI 和部分VII 分别。 我们在第一节中总结了这篇论文VIII.
**
II NDN结构
**
在本节中,我们简要介绍一下NDN体系结构的一些基本概念[4]对描述ChronoSync的设计至关重要。NDN体系结构具有两个基本通信单元:兴趣分组和数据分组,它们都携带分层结构的名称。 当消费者请求数据时发送兴趣数据包。 每个数据包都是加密签名的,
使接收者能够检查数据的出处和完整性,而不管数据是如何从数据源,缓存或邻居获得的。 一个数据包可以用来满足兴趣,只要在兴趣中携带的名字是数据的前缀或相同。如果有多个数据包可以满足兴趣,兴趣还可以携带选择器字段来指定偏好。
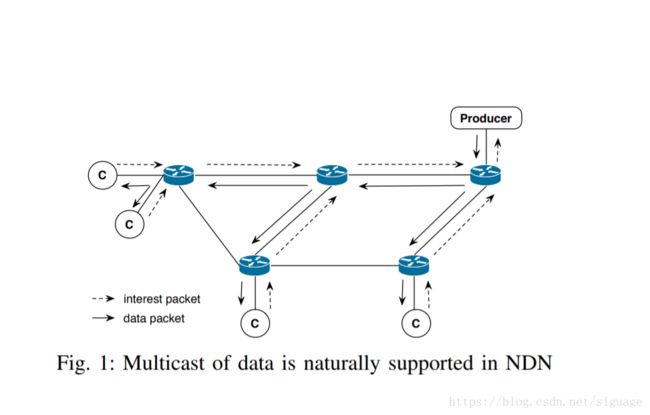
NDN中的所有通信都是接收器驱动的,这意味着数据包传输的唯一方式是消费者首先明确发出请求该数据的兴趣。当收到兴趣时,路由器为未决兴趣表(PIT)添加一个条目,记录感兴趣的接口,并使用转发策略[5]来确定转移利息的地方。 结果,返回的数据包可以简单地将反向路径追溯回请求者。 当相同数据的多个兴趣来自下游时,NDN路由器只创建一个PIT条目,记住所有感兴趣的接口,并只向上游转发一个兴趣。 如图1,这个过程基本上为每个被请求的数据项构造一个临时多播树,数据被有效地传送给所有的请求者。
**
III. CHRONOSYNC设计
**
在本节中,我们将介绍ChronoSync协议设计。 我们首先概述ChronoSync组件,然后解释部分中的命名规则III-B。部 分 III-C 展示了 ChronoSync 如 何 保 持 关 于 数 据 集 和Section的知识III-D 描述了数据集的变化如何传播给所有参与者。 部分III-E 和III-F 讨论ChronoSync如何处理同步数据生成和网络分区。
为了更好地说明ChronoSync设计的基本组件,我们在整篇论文中使用了一个组群文本聊天应用程序ChronoChat作为示例。 虽然真正的聊天应用程序包含许多重要组件,例如名
册维护,但在我们的示例中,我们只介绍与ChronoSync直接相关的元素。
**
A. 概观
**
在任何基于ChronoSync的应用程序的核心中,都有两个相互依存的组件,如图2所示:
- ChronoSync模块,用于同步数据集的状态
- 应用程序逻辑模块:对数据集的变化做出响应
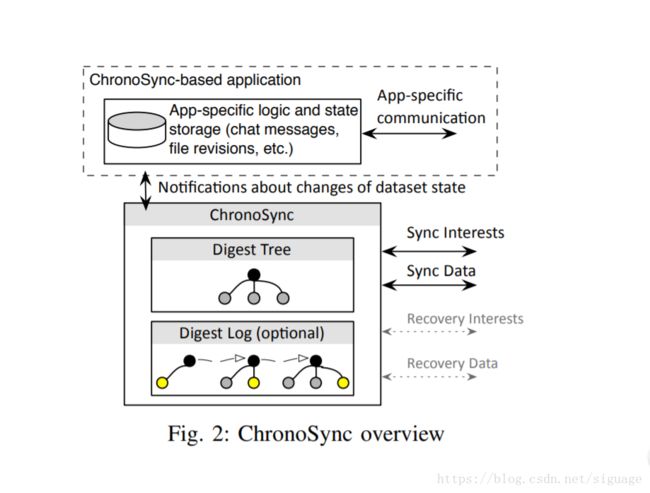
在ChronoChat中,ChronoSync模块以摘要树的形式维护当前用户对聊天室中所有消息的了解,以及以摘要日志的形式记录数据集状态更改的历史记录。在ChronoSync模块发现聊天室中有新消息后,它会通知ChronoChat逻辑模块获取并存储消息。
要发现数据集更改,每个ChronoChat实例的ChronoSync模块发出一个同步兴趣,其同名兴趣包含维护在摘要树根部的状态摘要。 通常,在摘要树和摘要日志的帮助下,ChronoSync可以直接推断数据集更改,并用包含更改的数据回复同步兴趣,我们此后将其称为同步数据。 在网络分区的情况下,ChronoSync还使用恢复兴趣和恢复数据来发现数据集状态的差异。
ChronoSync只专注于促进数据集中关于新数据项的知识的同步,并决定ChronoSync在应用程序自行决定发现状态更改后该做什么。 例如,ChronoChat中的同步数据带回了新添加到聊天室中的消息的名称,从而使用户对数据集的了解得到了更新。 但是,如果丢失消息的总数很大(例如从网络分区恢复后),则用户可以决定是获取所有丢失的消息还是仅获取最近的消息。
**
B. 命名规则
**
NDN中应用程序设计的一个最重要的方面是命名,因为这些名称执行了几个关键功能。 兴趣包中携带的名称由网络用于确定将其转发到哪里以及确定在到达生产者时将其传递给哪个进程。 同样适当的命名规则可以大大简化应用程序的设计。
ChronoSync中有两组命名规则:
- 第一组用于应用数据名称(application data names)
- 另一组用于同步数据名称(sync data names)

我们将应用程序数据名称设计为具有可路由的名称前缀,以便将兴趣直接转发给生产者(producer)。这些前缀可以通过在互联网提供商分配的前缀下附加一个或多个组件来构建。 例如,图 3a 部分(1)中的聊天数据名称的是这样一个前缀。包含应用程序名称和聊天室名称的第(2)部分的目的是在感兴趣信息到达数据源时对信息进行解复用:它识别负责处理此类兴趣的过程。
用户生成的数据按顺序命名。 例如,在ChronoChat中,用户加入聊天室的初始消息的序列号为零,并且无论何时生成新消息,无论是聊天消息还是新用户出现消息,序列号都会加1。 因此,用户对聊天室的可知性可以用一个名称来紧凑地表示。 假设名字如图3a 是Alice使用的最新的聊天数据名称。 我们可以从命名规则中推断Alice已经为这个聊天室产生了792条聊天数据,序列号范围从0到791。
同样,同步数据的名称(图3b)也由三部分组成。部分(1)是给定广播域的广播名称空间中的前缀。 广播前缀可确保将同步兴趣正确转发给组中的所有参与者,因为通常不可能预测谁将导致数据集状态的下一次更改。第(2)部分用于解复用(类似于应用程序数据名称),最后一部分包含感兴趣的发送者的最新状态摘要。
**
C. 维护数据集状态
**
应用程序数据集可以表示为所有生产者生成的数据子集的并集。
由于数据生产者的知识只能由其名称前缀和最新的序列号来表示,因此ChronoSync会跟踪每个生产者的最新应用程序数据名称,以便保持最新的数据集知识。 为了简单起见,我们将生产者的最新应用数据名称作为其生产者状态。
受Merkle树的想法启发[6],ChronoSync使用摘要树来快速确定性地将关于数据集的知识压缩成加密摘要,如图
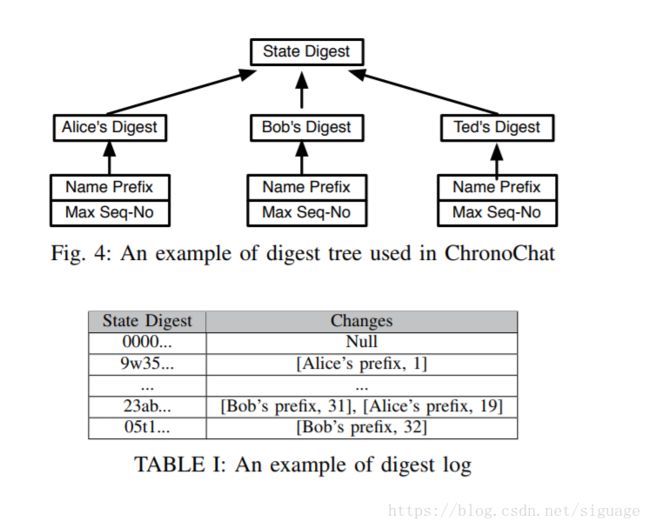
树根(root)的每个子节点保存通过在用户的生产者状态上应用例如SHA-256哈希函数而计算的加密摘要。 递归地将相同的哈希函数应用于根的所有子节点会产生代表整个数据集状态的摘要,我们称之为状态摘要。 为了确保每个参与者在观察同一组生产者状态时计算相同的状态摘要,根据其应用程序数据名称前缀将子节点保留为字典顺序(lexicographic order)。
摘要树始终保持最新,以准确反映数据集的当前状态。无论何时ChronoChat用户发送新的聊天消息或获知来自其他参与者的新消息的名称,摘要树的相应分支都会更新,并重新计算状态摘要。
作为一种优化,每一方都会保留摘要日志以及摘要树。 此日志是按时间顺序排列的键值
对列表,其中键是状态摘要,值字段包含导致状态更改的生产者状态。 表格Ⅰ中举例说明了摘要日志。 日志对于识别过时的状态摘要很有用。 例如,当用户从临时断开恢复并发出与过期状态摘要同步兴趣时,其他方如果识别出旧摘要,则可以快速推断数据集状态之间的差异并迅速回复发件人缺少的数据名称。
尽管摘要日志在许多情况下促进了状态差异发现的过程,但并不是必须确保ChronoSync设计的正确性。 根据可用资源,应用程序可以设置摘要日志大小的上限,并在必要时清除旧项目。
**
D. 传播数据集的更改
**
为了尽快检测数据集的变化,每一方都会对当前状态摘要保持已发送的(outstanding)的的同步兴趣包。当各方对数据集有相同的认知时,系统处于稳定状态,并且来自各方的同步兴趣携带相同的状态摘要,从而导致NDN路由器中的高效的兴趣包湮没(collapse)。图5a 展示了一个处于稳定状态的系统的例子,聊天室中没有正在进行的对话。

只要某方产生新数据,状态摘要就会改变,并且未完成的兴趣包会得到满足。 例如在图5b当Alice向聊天室发送文本时,她机器上的ChronoSync模块会立即发现其状态摘要较新,因此会继续使用包含文本消息名称的同步数据来满足同步兴趣。 由于NDN的通信属性,同步数据被高效地组播回聊天室中的每一方。 接收到同步数据的人将更新摘要树以反映对数据集状态的新更改,并用更新的状态摘要发出新的同步兴趣,将系统恢复到稳定状态。 同时,用户可以直接使用数据名称发送兴趣来请求Alice的文本消息。 在其他更复杂的应用程序中,同步数据可能会提示应用程序执行更复杂的操作,例如获取文件的新版本并将更改应用到本地文件系统。
通常情况下,同步兴趣包中携带的状态摘要由兴趣接收者识别:则它与接收者当前状态摘要相同或前一个状态摘要相同(如果接收者刚刚生成新数据)。 但是,即使在无损环境中,无序数据包的传递也会导致接收到包含无法识别的摘要的同步兴趣包。 例如,在图5b中,Ted对新状态摘要的同步兴趣(将Alice的同步数据并入摘要树后,图中未示出)可能在他接收Alice的同步数据之前到达Bob,这是由于传输中可能的无序传送。

为了解决这个问题,ChronoSync采用了一个随机延时器Tw,其值大约按传播延迟的顺序设置。 更具体地说,接收者在接收到未知摘要时建立延时器Tw,并延迟对相应的同步兴趣包的处理,直到延时器到期。 在上面提到的例子中,在Tw到期之前,Bob的状态摘要将与Alice的回复到达他之后的新摘要保持一致。
**
E. 处理数据的同时产生
**
在同时生成数据的情况下,多个数据生产者回复外发的的同步兴趣包。 由于一个兴趣只能带回NDN中的一段数据,因此同时进行的数据生成会将系统划分为两个或更多个组,每个组根据其收到的同步数据来维护不同的状态摘要。同时,不同组的用户将无法识别彼此的状态摘要。 这在图1中示出。6Alice和Bob同时回复同步兴趣,只有Bob的同步数据达到Ted。 因此,爱丽丝的新状态摘要与其他两个不同。
这个问题可以通过排除过滤器来解决[7],这是可以随兴趣一起发送以排除请求者不再需要的数据的选择器之一。当等待时间Tw超时时,Ted继续再次发送与先前状态摘要的同步兴趣,但这次使用包含鲍勃同步数据的散列的排除过滤器。 路由器知道Bob的同步数据尽管与同步感兴趣的同名数据名称相同,但不能用作对该兴趣的答复。 结果,这种同步兴趣从路由器C的缓存带回Alice的同步数据。同样,Alice和Bob也借助排除过滤器来检索彼此的同步数据。 在这一点上,所有三个用户都获得了关于同时生成的数据的知识并计算出相同的状态摘要。
如果在同时发生的数据生成事件中涉及更多生产者,则必须发送多次使用排除过滤器的同步兴趣。 这种兴趣中的每一个都必须排除到目前为止请求者已知的特定状态摘要的所有同步数据。

**
F. 处理网络分区
**
当网络分区发生时,用户在物理上被划分为多个组(而不是同时数据生成案例中的逻辑划分)。 尽管由于ChronoSync的分散式设计,每个组内的用户可能会继续进行通信,但当网络分区愈合时,存在一个具有挑战性的同步问题:不同组中的各方累积不同的数据子集,并且他们不可能识别彼此的状态摘要。 与同时生成数据的过程不同,多个用户通过不同的同步数据回复相同的同步兴趣,在网络分区期间,多个不同状态摘要的未知数量的同步数据可能由多方产生,导致排除过滤器无效确定数据集的差异。 因此,当带有排除过滤器的兴趣超时(这样的兴趣应该具有非常短的寿命,因为同步数据(如果有的话)应该已经被缓存在路由器中),ChronoSync推断网络分区已经发生并且测量必须采取解决分歧。 根据具体的应用需求,各种设置调节算法[8]–[10]可以用来解决这个问题。
例如,对于ChronoChat等应用程序,Chrono-Sync采用简单而有效的恢复程序,概述如下。 未知摘要的接收者发出恢复兴趣,如图3所示。7。 它与正常的同步兴趣类似,但在摘要之前有一个“恢复”组件,并且包含未知状态摘要,而不是本地摘要树根中的一个。 这种兴趣的目的是要求那些产生或识别未知状态摘要的人员丢失关于数据集的信息。 那些认识到摘要的人(例如,在摘要日志中记载)会回复所有用户的最新制片人状态,而其他人则简单地忽略了恢复兴趣。 接收到恢复答复后,收件人会将答复中包含的生产者状态与存储在本地摘要树中的生产者状态进行比较,并且只要答复中的那个更新,就更新树。该恢复程序保证系统将在几轮恢复期间恢复到稳定状态(例如,具有不同状态摘要的两个组的一轮)。
**
IV. 实施
**
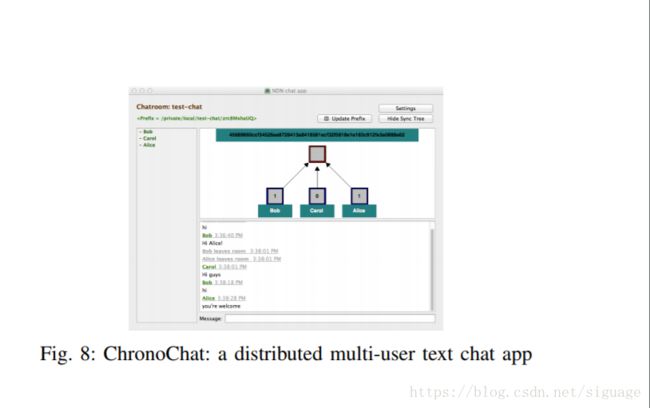
我们将ChronoSync协议以C ++库实现,并构建了概念证明ChronoChat应用程序(图8 显示演示聊天会话的屏幕截图),并在多达20位参与者的Linux和Mac OS X平台上进行测试。 聊天消息向所有参与者正确并且及时得传播。
此外,为了证明ChronoSync支持更复杂的应用程序的有效性,我们还开发并测试了ChronoShare,这是一款基于ChronoSync的分布式文件共享应用程序,提供与商业同行(如Dropbox)类似的用户体验,但充分使用了NDN的缓存和多播功能的优势。
**
V. 评估
**
为了理解ChronoSync协议的特性和权衡,我们使用NS-3与ndnSIM模块[12]对群组文本聊天服务(ChronoChat)进行了许多基于模拟的实验[11],它完全实现了NDN通信模型。 特别是,我们有兴趣确认ChronoSync即使在网络故障和数据包丢失的情况下也能快速有效地传播状态信息。为了获得对比的基准,我们还实施了集中式互联网中继聊天(IRC)服务的简单的基于TCP / IP的近似,其中服务器将来自用户的消息反映给所有其他用户。 为了简化仿真,我们没有为ChronoChat或IRC服务模拟实现心跳消息(heart beat)。 此外,模拟ChronoChat应用程序中的聊天消息与同步数据包(sync data)一起搭载。 也就是说,例如,当Alice发送新消息时,她的ChronoChat应用程序不仅会通知其他人存在新消息,还会将实际消息数据包含在同一个数据包中。
在我们的评估中,我们使用了Sprint point-of-presence topology 拓扑[13],包含52个节点和84个链接(图。9)。 每条链路都分配了根据测量推断的延迟(measurement-inferred delay),100 Mbps带宽和容量为2000个数据包的下降队列队列。 由于短信的大小通常很小,网络中没有拥塞。 拓扑中的所有节点充当一个聊天室的所有参与者。 房间内的交通模式(traffic pattern)是根据Dewes等人的多方聊天流量分析确定的。[14]作为大小为20到200字节的消息流,消息之间的间隙遵从指数分布,均值为5秒。
**
A. 状态同步延迟
**
基于ChronoSync的应用程序在同步数据集状态方面的速度是很快的。 为了定量评估这个属性,我们定义状态同步延迟(state synchronization delay)是某条信息产生和这条信息被聊天室所有参与者发现两者之间的时间间隔。我们在52个参与者的基础上进行了20次聊天室模拟运行,这些参与者在各种网络条件下共同生成了1000条消息。 每个单独的模拟运行以不同的消息集注入聊天室,不同的消息间延迟,不同的消息大小以及不同的参与者讲话顺序。 在IRC案例中,我们随机选择拓扑中的一个节点作为每次运行的中央服务器的位置。
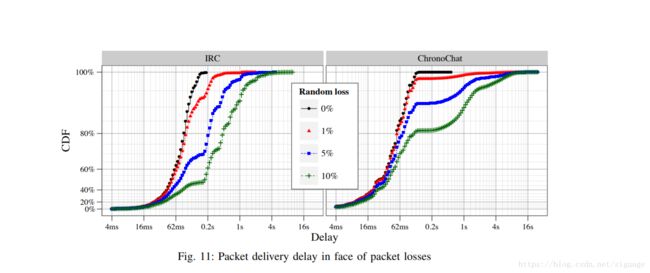
- 在正常网络条件下的性能:作为第一步,我们在正常网络条件下评估ChronoChat,此时没有发生网络故障或数据包丢失,这使我们能够了解ChronoSync协议的基准性能。由于在ChronoChat中同步数据总是遵循由出色的同步兴趣构建的最佳路径,所以与基于客户端 - 服务器的IRC实现相比,同步延迟显着更低,如图2所示。10:对于ChronoChat来说,在20次运行中发送的所有消息中,40%以上的延迟时间少于20毫秒,而相同延迟范围内的13%消息在IRC情况下发生。
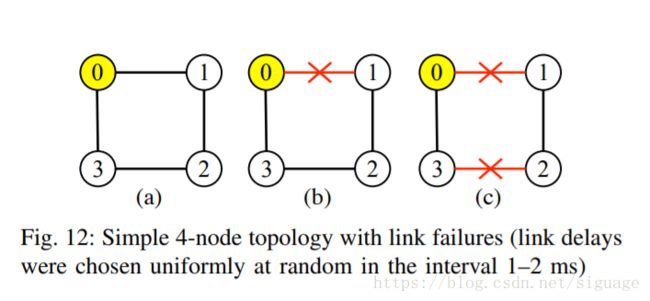
- 在有损环境中的性能:我们评估了有损网络环境中的ChronoChat,每个链路的随机数据包丢失程度不一,范围从1%到10%不等。 图。11 以ChronoChat和IRC服务的累积分布函数图的形式总结模拟结果(为了更好的视觉呈现,x轴以指数尺度呈现,而y轴呈二次尺度)。 从这些结果可以得出结论,ChronoChat的性能几乎不受影响,如果网络遭受中等水平的随机损失(1%)。 而且,即使网络条件恶化,随机丢失增加到异常高的值(5%-10%),与类IRC系统相比,ChronoChat仍然显示出明显更短的状态同步延迟。
总体而言,不管随机丢失率的值如何,ChronoChat中的更多消息与IRC中的消息相比经历了更小的延迟。 随着丢失率的增长,这种趋势更加明显:在IRC中,延迟较小的消息的百分比迅速下降,而在ChronoChat中,它的下降更加优雅。 然而,仔细的读者可能会注意到,与IRC相比,ChronoChat中的一小部分消息经历了较长的延迟。 这是因为ChronoChat使用NDN的基于拉的模型:接收者需要首先发现一个新的状态以便请求它,而不是TCP / IP,源保持(重新)发送数据包直到它被接收器。 在同步兴趣或同步数据被大量丢弃以致一些参与者不知道状态改变的情况下,它必须等到这些参与者重新表达同步兴趣或在消息可以被传播给所有用户之前发生另一状态改变。 我们认为,根据应用需求和网络条件,自适应调整同步兴趣包二次发送间隔应该能够将同步延迟保持在合理的范围内。
**
B. 对网络故障的同步恢复能力
**
ChronoSync的另一个主要特点是无服务器设计,这意味着用户只要连接就可以相互通信。 即使在网络分区的情况下,每个分区的参与者组仍然应该能够相互通信,并且当分区合并时,不同的组应该自动同步聊天室数据。
- 链路故障恢复的基本验证:为了验证这个属性,我们进行了一个小规模的4节点仿真,其中包括链路故障和网络分区(图12)。 20分钟的总模拟时间被分成5个区域:0- 200秒,没有链路故障(图2)。12a),200-400秒,节点0和节点1之间有一个故障链路。12b),在节点0,1和2,3之间具有两个失效链路的400-800秒(分区网络,12c),800-1000秒,节点2和节点3之间有一个故障链路,最后是1000-1200秒周期,没有链路故障。结果如图2所示。13,将节点0关于所有其他参与者的当前状态的知识可视化为时间的函数。 这个数字不仅证实连接网络中的各方在分区事件期间继续通信,而且确认当网络从分区恢复时,一旦兴趣包开始流经以前的失败链接,状态就会同步。
- ) 链路故障的影响:为了量化网络故障对文本聊天参与者彼此通信能力的影响,我们再次使用了我们的52节点拓扑,该拓扑现在受到不同级别的链路故障的影响。 在模拟的每一次单独运行中,我们都失败了10到50条链路(不同运行中不同的链路故障组),相当于拓扑中总链路数的10%和50%。 我们针对每个级别的链路故障执行了20次模拟运行,并计算仍能够通信的线路对的数量。 如图所示14, 我们用针对该图的小提琴图(violin plot)4来突出显示中央IRC服务中通信对的百分比分布的双峰性质:具有显着高的概率,用户几乎根本不能进行通信(注意靠近底部的小提琴图的部分) IRC的y轴)。 ChronoChat,完全分发,总是允许大量的对能够沟通。 对于任何集中式实现(如IRC),总是存在单点故障,即使链路故障级别很小,通信也可能完全中断。

**
C. 网络使用模式
**
为了理解ChronoSync中链路故障的快速状态同步和鲁棒性如何与网络利用率相关,对于同一组实验,我们收集了拓扑结构中每条链路转发的有关数据包数量的统计数据(我们称之为链接的数据包集中)。在对数据包进行计数时,我们在ChronoChat中包含兴趣和数据包,并在IRC中包含TCP数据和ACK数据包。 获得的52节点拓扑实验的数据总结如图15,其中链接按包浓度值进行排序和可视化(具有97.5%置信区间)。
结果显示在图15 表明ChronoChat或多或少地平等地利用参与者之间的所有可用网络链接。6 IRC案例中的网络利用结果显示了完全不同的模式。 靠近服务器的几条链路的数据包密集度很高,与服务器直接相邻的链路上的数据量高达90,000个数据包(占聊天室中消息总数的90倍)。许多接近客户端的链接的数据包密度较低,而某些不在客户端和服务器之间的最短路径的链接根本没有使用。
**
D. 总体开销
**
ChronoChat和IRC的网络使用模式之间的差异突出了ChronoSync协议的重要设计权衡。 由于ChronoSync的主要目标是尽可能快地以完全分布的方式同步状态,并且能够缓解网络故障,所以与IRC相比,它在拓扑中利用了更多的链路。 同时,由于ChronoSync没有三角形数据分布路径,而NDN架构可确保每条数据在链路上传输的次数不超过一次,所以ChronoChat的总体开销甚至可能低于通常的集中式解决方案被认为是有效的网络利用率。 例如,图1中所示的分组浓度的累积总和。16 表明,在我们的实验中,同步兴趣通过广播进行分配,与IRC服务相比,ChronoChat仍然具有相当低的总体开销。


请注意,ChronoSync还具有特定于应用程序的权衡,可以直接与整体开销相关。 特别是,当一个应用程序很少产生新的数据并且可以容忍某些同步延迟时,不需要总是保持一个已发送的的同步兴趣包。 相反,同步兴趣包可以用更长的时间间隔来发送,以减少整体开销。
**
参考
**
[1] L. Lamport, “Time, clocks, and the ordering of events in a distributedsystem,” Commun. ACM, 1978.
[2] S. Androutsellis-Theotokis and D. Spinellis, “A survey of peer-to-peer content distribution technologies,” ACM Comput. Surv., 2004.
[3] “BitTorrent Sync,” http://labs.bittorrent.com/experiments/sync.html.
[4] L. Zhang et al., “Named data networking (NDN) project,” PARC, Tech.Rep. NDN-0001, 2010.
[5] C. Yi, A. Afanasyev, I. Moiseenko, L. Wang, B. Zhang, and L. Zhang, “Acase for stateful forwarding plane,” Computer Communications, 2013.
[6] R. C. Merkle, “A certified digital signature,” in Proc. of Advances in Cryptology, 1989.
[7] “Ccnx techincal documentation: Ccnx interest message,”
http://www.ccnx.org/releases/latest/doc/technical/InterestMessage.html.
[8] D. Eppstein, M. Goodrich, F. Uyeda, and G. Varghese, “What’s the difference? Efficient set reconciliation without prior context,” Proc. of SIGCOMM, 2011.
[9] Y. Minsky et al., “Set reconciliation with nearly optimal communication
complexity,” IEEE Trans. Info. Theory, 2003.
[10] J. Feigenbaum et al., “l1-different algorithm for massive data streams,” SIAM Journal on Computing, 2002.
[11] “ns-3: a discrete-event network simulator for Internet systems,”
http://www.nsnam.org.
[12] A. Afanasyev, I. Moiseenko, and L. Zhang, “ndnSIM: NDN simulator for NS-3,” NDN, Technical Report NDN-0005, 2012.
[13] N. Spring, R. Mahajan, D. Wetherall, and T. Anderson, “Measuring ISP topologies with Rocketfuel,” IEEE/ACM Transactions on Networking, vol. 12, no. 1, 2004.
[14] C. Dewes, A. Wichmann, and A. Feldmann, “An analysis of Internet
chat systems,” IMC’03.
[15] S. Floyd, V. Jacobson, S. McCanne, C.-G. Liu, and L. Zhang, “A
reliable multicast framework for light-weight sessions and application
level framing,” in Proc. of SIGCOMM, 1995.
[16] L.-W. H. Lehman, S. J. Garland, and D. L. Tennenhouse, “Active reliable multicast,” in Proc. of INFOCOM, 1998.
[17] S. Paul, K. K. Sabnani, J.-H. Lin, and S. Bhattacharyya, “Reliable multicast transport protocol (RMTP),” IEEE Journal on Selected Areas in Communications, vol. 15, no. 3, pp. 407–421, 1997.
[18] ProjectCCNx, “Ccnx synchronization protocol,” http://www.ccnx.org/releases/latest/doc/technical/SynchronizationProtocol.html.
[19] Y. Zhang, A. Rajimwale, A. C. Arpaci-Dusseau, and R. H. ArpaciDusseau, “End-to-end data integrity for file systems: a ZFS case study,” in Proc. USENIX conference on File and storage technologies, 2010.
[20] G. DeCandia et al., “Dynamo: Amazon’s highly available key-value store,” in ACM SIGOPS Operating Systems Review, 2007.
[21] A. Tridgell and P. Mackerras, “The rsync algorithm,” TR-CS-96-05, 1996.
[22] S. Agarwal, D. Starobinski, and A. Trachtenberg, “On the scalability of data synchronization protocols for PDAs and mobile devices,” IEEE Network, vol. 16, no. 4, 2002.
[23] A. Muthitacharoen, B. Chen, and D. Mazieres, “A low-bandwidth network file system,” in ACM SIGOPS Operating Systems Review, 2001.
[24] N. Jain, M. Dahlin, and R. Tewari, “Taper: Tiered approach for eliminating redundancy in replica synchronization,” in Proc. USENIX Conference on File and Storage Technologies, 2005.
[25] Z. Zhu, S. Wang, X. Yang, V. Jacobson, and L. Zhang, “ACT: An audio conference tool over named data networking,” in Proc. of SIGCOMM ICN Workshop, 2011.
[26] “ZeroConf,” http://www.zeroconf.org/.