- 【Python学习之路】——Day20(Django 下)
weixin_30758821
数据库pythonjavascriptViewUI
Model到目前为止,当我们的程序涉及到数据库相关操作时,我们一般都会这么搞:创建数据库,设计表结构和字段使用MySQLdb来连接数据库,并编写数据访问层代码业务逻辑层去调用数据访问层执行数据库操作importMySQLdbdefGetList(sql):db=MySQLdb.connect(user='root',db='wupeiqidb',passwd='1234',host='localh
- Python----数据结构----链表----双向链表
一盏偏灯
Python学习数据结构链表算法python
Python学习之路,点击有全套Python笔记双向链表一种更复杂的链表是“双向链表”或“双面链表”。每个节点有两个链接:一个指向前一个节点,当此节点为第一个节点时,指向空值;而另一个指向下一个节点,当此节点为最后一个节点时,指向空值。步骤:is_empty()链表是否为空length()链表长度travel()遍历链表add(item)链表头部添加append(item)链表尾部添加insert
- 5.0在python中是一个整数常量_python学习之路,基础篇-变量和常量
weixin_39553753
python语言基础1、常量和变量1.1、常量常量是内存中用于保存固定值的单元,在程序中常量的值不能发生改变;python并没有命名常量,也就是说不能像C语言那样给常量起一个名字。python常量包括:数字、字符串、布尔值、空值;1.1.1数字python包括:整数、长整数、浮点数、复数,4种类型的数字;1>整数:表示不包含小数点的实数,在32位计算机上,标准整数的取值范围为-231~231-1,
- Python学习之路-爬虫提高:scrapy基础
geobuins
python学习爬虫
Python学习之路-爬虫提高:scrapy基础为什么要学习scrapy通过前面的学习,我们已经能够解决90%的爬虫问题了,那么scrapy是为了解决剩下的10%的问题么,不是,scrapy框架能够让我们的爬虫效率更高什么是scrapyScrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需要实现少量的代码,就能够快速的抓取。Scrapy使用了Twisted['twɪstɪd]
- Python学习之路-爬虫提高:scrapy使用
geobuins
python学习爬虫
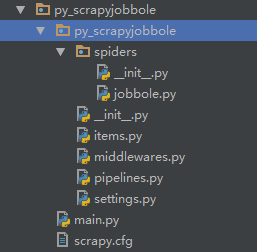
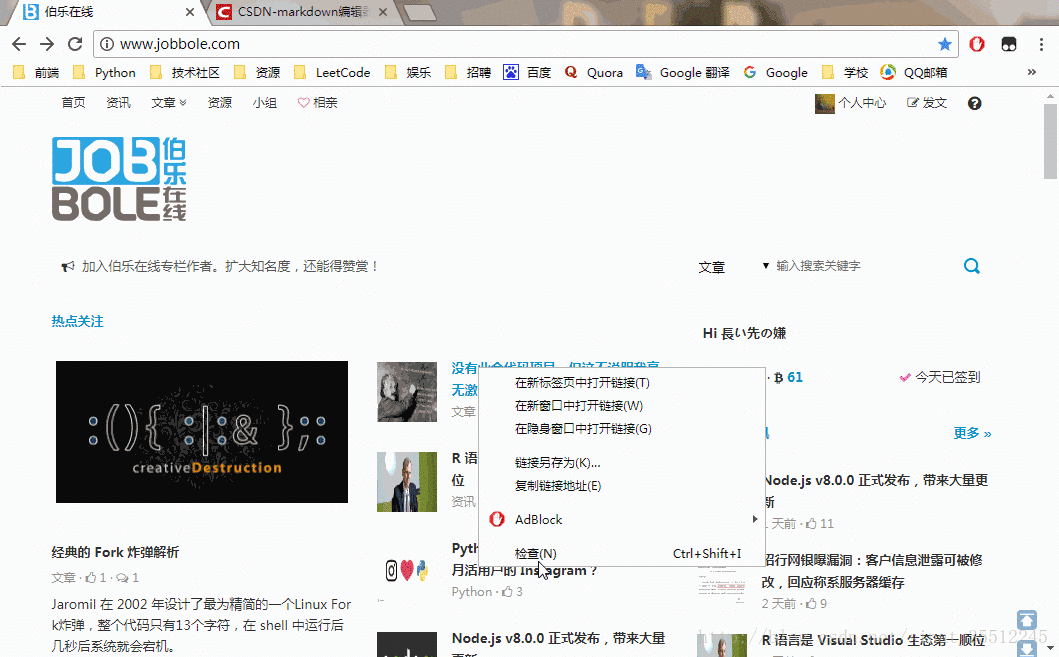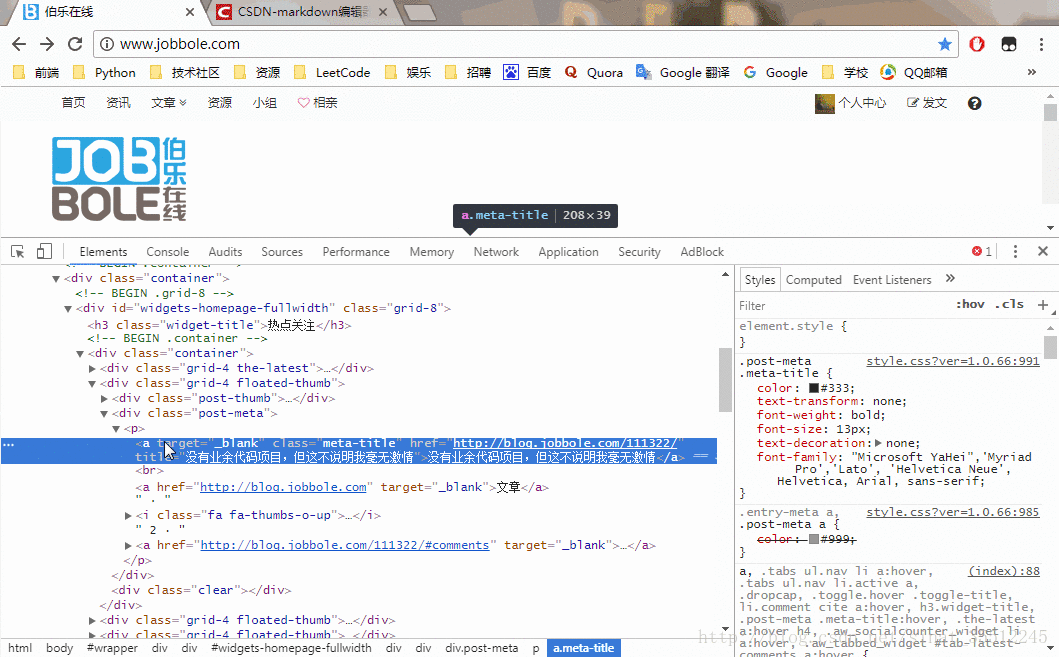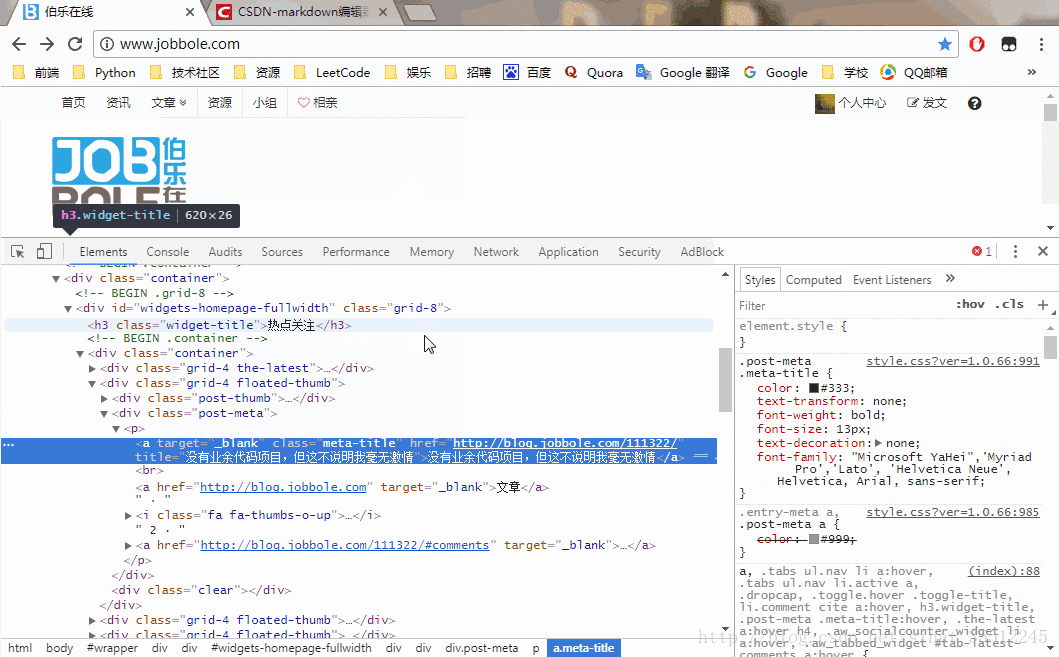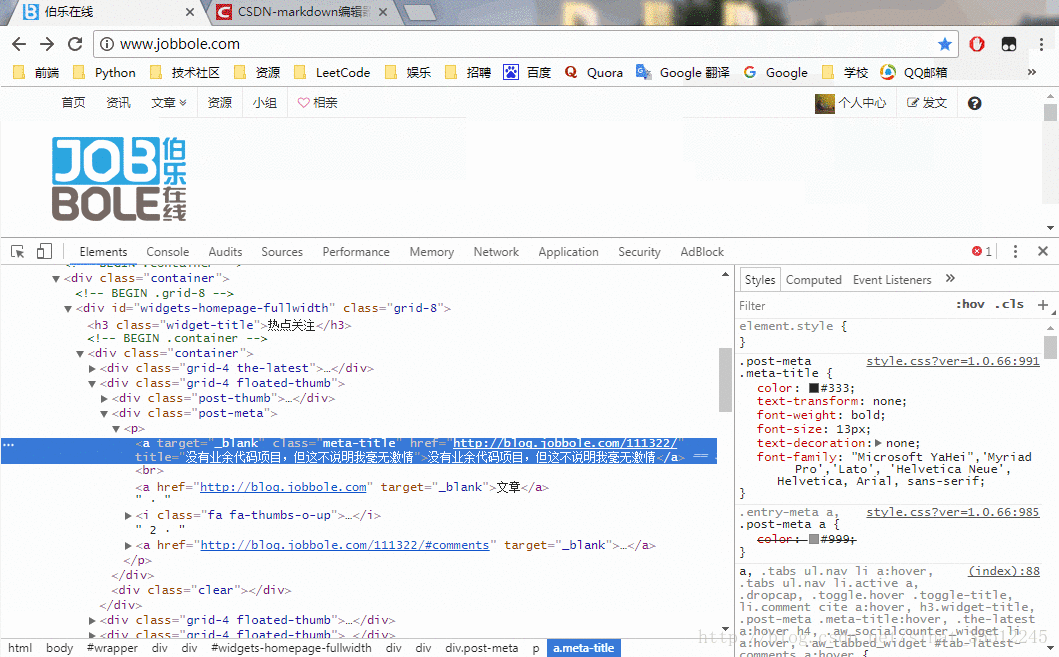
Python学习之路-爬虫提高:scrapy使用scrapy项目实现流程创建一个scrapy项目:scrapystartprojectmySpider生成一个爬虫:scrapygenspideritcast"itcast.cn提取数据:完善spider,使用xpath等方法保存数据:pipeline中保存数据创建scrapy项目下面以抓取传智师资库来学习scrapy的入门使用:http://www
- Python学习之路-爬虫提高:常见的反爬手段和解决思路
geobuins
python学习爬虫
Python学习之路-爬虫提高:常见的反爬手段和解决思路常见的反爬手段和解决思路明确反反爬的主要思路反反爬的主要思路就是:尽可能的去模拟浏览器,浏览器在如何操作,代码中就如何去实现。浏览器先请求了地址url1,保留了cookie在本地,之后请求地址url2,带上了之前的cookie,代码中也可以这样去实现。很多时候,爬虫中携带的headers字段,cookie字段,url参数,post的参数很多,
- Python学习之路-爬虫提高:selenium
geobuins
python学习爬虫
Python学习之路-爬虫提高:selenium什么是seleniumSelenium是一个Web的自动化测试工具,最初是为网站自动化测试而开发的,Selenium可以直接运行在浏览器上,它支持所有主流的浏览器(包括PhantomJS这些无界面的浏览器),可以接收指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏PhantomJS的介绍PhantomJS是一个基于Webkit的“无界面”(h
- Python学习之路-初识爬虫:基础知识
geobuins
jmeter
Python学习之路-初识爬虫:基础知识什么是爬虫网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。原则上,只要是浏览器(客户端)能做的事情,爬虫都能够做用途如今,人工智能,大数据离我们越来越近,很多公司在开展相关的业务,但是人工智能和大数据中有一个东西非常重要,那就是数据,但是数据从哪里来呢?这时候爬虫的用途就凸显出
- Python学习之路-初识爬虫:数据提取
geobuins
python学习爬虫
Python学习之路-初识爬虫:数据提取什么是数据提取简单的来说,数据提取就是从响应中获取我们想要的数据的过程爬虫中数据的分类结构化数据:json,xml等处理方式:直接转化为python类型非结构化数据:HTML处理方式:正则表达式、xpath数据提取之json为什么要复习json由于把json数据转化为python内建数据类型很简单,所以爬虫中,如果我们能够找到返回json数据的URL,就会尽
- Python学习之路-初识爬虫:requests
geobuins
python学习爬虫
Python学习之路-初识爬虫:requestsrequests的作用作用:发送网络请求,返回响应数据中文文档:http://docs.python-requests.org/zh_CN/latest/index.html为什么学requests而不是urllibrequests的底层实现就是urllibrequests在python2和python3中通用,方法完全一样requests简单易用R
- Python学习之路-Tornado基础:部署
geobuins
python学习tornado
Python学习之路-Tornado基础:部署部署Tornado简介为了充分利用多核CPU,并且为了减少同步代码中的阻塞影响,在部署Tornado的时候需要开启多个进程(最好为每个CPU核心开启一个进程)因为Tornado自带的服务器性能很高,所以我们只需开启多个Tornado进程。为了对外有统一的接口,并且可以分发用户的请求到不同的Tornado进程上,我们用Nginx来进行代理。supervi
- Python学习之路-Tornado基础:异步与WebSocket
geobuins
python学习tornado
Python学习之路-Tornado基础:异步与WebSocket认识异步同步我们用两个函数来模拟两个客户端请求,并依次进行处理:#coding:utf-8defreq_a():"""模拟请求a"""print('开始处理请求req_a')print('完成处理请求req_a')defreq_b():"""模拟请求b"""print('开始处理请求req_b')print('完成处理请求req_b
- Python学习之路-Flask项目:博客后台
geobuins
python学习flask
Python学习之路-Flask项目:博客后台前言上一篇完成了博客前台的相关内容,接下来进行博客后台的相关开发。管理员登录需求分析管理员用户进行登录,并且根据不同的情况报出不同的错误信息,如果当前已登录用户是管理员,在访问登录页面时直接跳转到后台管理主页。登录界面可以直接使用Form表单提交(也可以采用ajax的方式)代码准备在templates目录下创建admin文件夹,将static/admi
- Python学习之路-Flask项目:项目部署
geobuins
python学习flask
Python学习之路-Flask项目:项目部署部署环境基于MacOS10.15.4系统,使用Gunicorn+Nginx进行布署,云服务器为阿里云服务器选择阿里云服务器地址个人免费试用进入控制台,查看实例创建情况给安全组配置规则,添加5000端口(一并加上5001端口)利用命令行进行远程服务器登录ssh用户名@ip地址相关环境安装以下操作都在远程服务器上进行操作先更新apt相关源sudoapt-g
- Python学习之路-Django基础:工程搭建
geobuins
python学习django
Python学习之路-Django基础:工程搭建环境安装创建虚拟环境mkvirtualenvdjango_1.11.10-ppython3安装Django使用Django1.11.10版本pipinstalldjango==1.11.10创建工程在使用Flask框架时,项目工程目录的组织与创建是需要我们自己手动创建完成的。在django中,项目工程目录可以借助django提供的命令帮助我们创建。创
- Python学习之路-Tornado基础:数据库
geobuins
python学习tornado
Python学习之路-Tornado基础:数据库简介与Django框架相比,Tornado没有自带ORM,对于数据库需要自己去适配。我们使用MySQL数据库。在Tornado3.0版本以前提供tornado.database模块用来操作MySQL数据库,而从3.0版本开始,此模块就被独立出来,作为torndb包单独提供。torndb只是对MySQLdb的简单封装,不支持Python3。连接初始化我
- Python学习之路-Tornado基础:安全应用
geobuins
python学习tornado
Python学习之路-Tornado基础:安全应用Cookie对于RequestHandler,除了在初始Tornado中讲到的之外,还提供了操作cookie的方法。设置set_cookie(name,value,domain=None,expires=None,path=‘/’,expires_days=None)参数说明:参数名说明namecookie名valuecookie值domain提交
- Python学习之路002-小插曲之变量和字符串
阿花去哪里啦
注:内容源于学习小甲鱼《零基础入门学Python》,这些都是我自己写的作业,学习地址:https://www.bilibili.com/video/BV1Fs411A7HZ?p=20.以下哪个变量的命名不正确?为什么?(A)MM_520(B)_MM520_(C)520_MM(D)_520_MMA:C不正确,变量不能以数字开头1.在不上机的情况下,以下代码你能猜到屏幕会打印什么内容吗?>>>myte
- Python学习之路-Django基础:类视图与中间件
geobuins
python学习django
Python学习之路-Django基础:类视图与中间件类视图引入以函数的方式定义的视图称为函数视图,函数视图便于理解。但是遇到一个视图对应的路径提供了多种不同HTTP请求方式的支持时,便需要在一个函数中编写不同的业务逻辑,代码可读性与复用性都不佳。defregister(request):"""处理注册"""#获取请求方法,判断是GET/POST请求ifrequest.method=='GET':
- Python学习之路-Django基础:请求与响应
geobuins
python学习django
Python学习之路-Django基础:请求与响应请求简介回想一下,利用HTTP协议向服务器传参有几种途径?提取URL的特定部分,如/weather/beijing/2018,可以在服务器端的路由中用正则表达式截取;查询字符串(querystring),形如key1=value1&key2=value2;请求体(body)中发送的数据,比如表单数据、json、xml;在http报文的头(heade
- Python学习之路-数据库入门
geobuins
python学习数据库
Python学习之路-数据库入门简介数据库就是一种特殊的文件,其中存储着需要的数据。类型当前主要使用两种类型的数据库:关系型数据库、非关系型数据库,本篇主要讨论关系型数据库,对于非关系型数据库会在后面学习。所谓的关系型数据库RDBMS,是建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据。关系型数据库的主要产品:oracle:在以前的大型项目中使用,银行,电信等项目m
- Python学习之路-Python操作MySQL
geobuins
python学习mysql
Python学习之路-Python操作MySQL简介PyMySQLPyMySQL是在Python3.x版本中用于连接MySQL服务器的一个库,PyMySQL遵循Python数据库APIv2.0规范,并包含了pure-PythonMySQL客户端库。安装pipinstallpymsql连接通过Connection对象与数据库建立连接frompymysqlimportconnectconn=conne
- Python学习之路-MySQL进阶
geobuins
python学习mysql
Python学习之路-MySQL进阶视图前言对于复杂的查询,往往是有多个数据表进行关联查询而得到,如果数据库因为需求等原因发生了改变,为了保证查询出来的数据与之前相同,则需要在多个地方进行修改,维护起来非常麻烦。可以通过定义视图来解决简介通俗的讲,视图就是一条SELECT语句执行后返回的结果集。所以我们在创建视图的时候,主要的工作就落在创建这条SQL查询语句上。视图是对若干张基本表的引用,一张虚表
- Python学习之路-正则表达式
geobuins
python学习正则表达式
Python学习之路-正则表达式简介正则表达式是计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些匹配某个模式的文本。RE模块在Python中需要通过正则表达式对字符串进行匹配的时候,可以使用一个模块:re语法#导入re模块importre#使用match方法进行匹配操作result=re.match("
- Python学习之路——异常捕获
墨白001
Python零基础学习之路学习python开发语言
一、什么是异常当检测到一个错误时,Python解释器就无法继续执行了,反而出现了一些错误的提示,这就是所谓的“异常”,也就是bug二、异常的捕获方法当我们的程序遇到bug,那么就下来有两种情况①整个程序因为一个bug停止运行②对bug进行提示,整个程序继续运行捕获异常的作用在于:提前假设某处会出现异常,做好提前准备,当真的出现异常的时候,可以有后续手段。1、捕获常规异常(一)基本语法try:可能发
- Python学习之路-注释
geobuins
学习
Python学习之路-注释将注释放在Python语法前面足以提现它的重要性。注释的作用一个好的程序中注释是不可缺失的一环。在程序中对某些代码进行标注说明,可以增强程序的可读性。在团队协同开发中,良好的注释可以提高开发效率。什么时候需要使用注释?注释不是越多越好,对于一目了然的代码,不需要添加注释对于复杂的操作,应该在操作开始前写上思路的注释对于不是一目了然的代码,应在其行尾添加注释(为了提高可读性
- Python学习之路-语法
geobuins
python学习开发语言
Python学习之路-语法简介Python的设计目标之一是让代码具备高度的可阅读性。在设计时尽量使用经常使用的标点符号和英文单字,让代码看起来整洁美观。缩进在Python中缩进表示语句块的开始和结束,作用等同于Java、Go中的大括号。增加缩进表示语句块的开始,而减少缩进则表示语句块的结束。缩进成为了语法的一部分,违反了“缩进规则”的程序不能通过解释器解释。{{}}根据PEP8的规定,使用4个空格
- Python学习之路-常量与变量
geobuins
python学习开发语言
Python学习之路-常量与变量程序就是用来处理数据的,而常量和变量就是最简单用来存储数据的常量定义声明在文件的顶部命名规范全部大写单词间用下划线分隔变量定义变量在使用前都必须要要进行赋值,只有被赋值后变量才会被创建命名规范一般情况当变量名需要由二个或多个单词组成时,每个单词都使用小写字母单词与单词之间使用_下划线连接驼峰命名法当变量名是由二个或多个单词组成时,还可以利用驼峰命名法来命名小驼峰式命
- Python学习之路-运算符
geobuins
学习
Python学习之路-运算符简介上一篇讲到Python中的语句提到很多运算符,本篇来总结一下各类运算符的作用与用法。算数运算符运算符描述实例+加1+1=2-减1-1=0*乘1*1=1**幂次方2**3=8/除2/1=2//取整5//2=2%取余5%2=1{{}}在Python中*运算符还可以用于字符串,计算结果就是字符串重复指定次数的结果{{}}比较运算符运算符描述==比较两个数据的值是否相等,如
- Python学习之路——文件部分【书接上回】
墨白001
Python零基础学习之路学习python开发语言
一、书接上回上个博客我说过,为什么最开始的时候一定要将文件内的中文的逗号替换为英文的逗号,接下来,请看(其实想一想,感觉没必要,不过也是好的,总要练练手的嘛)deffunc03(str):#先拿到文件的内容fr=open(str,'r',encoding='utf-8')fr_content=fr.read()print(fr_content)fr_now_content=fr_content.r
- 多线程编程之存钱与取钱
周凡杨
javathread多线程存钱取钱
生活费问题是这样的:学生每月都需要生活费,家长一次预存一段时间的生活费,家长和学生使用统一的一个帐号,在学生每次取帐号中一部分钱,直到帐号中没钱时 通知家长存钱,而家长看到帐户还有钱则不存钱,直到帐户没钱时才存钱。
问题分析:首先问题中有三个实体,学生、家长、银行账户,所以设计程序时就要设计三个类。其中银行账户只有一个,学生和家长操作的是同一个银行账户,学生的行为是
- java中数组与List相互转换的方法
征客丶
JavaScriptjavajsonp
1.List转换成为数组。(这里的List是实体是ArrayList)
调用ArrayList的toArray方法。
toArray
public T[] toArray(T[] a)返回一个按照正确的顺序包含此列表中所有元素的数组;返回数组的运行时类型就是指定数组的运行时类型。如果列表能放入指定的数组,则返回放入此列表元素的数组。否则,将根据指定数组的运行时类型和此列表的大小分
- Shell 流程控制
daizj
流程控制if elsewhilecaseshell
Shell 流程控制
和Java、PHP等语言不一样,sh的流程控制不可为空,如(以下为PHP流程控制写法):
<?php
if(isset($_GET["q"])){
search(q);}else{// 不做任何事情}
在sh/bash里可不能这么写,如果else分支没有语句执行,就不要写这个else,就像这样 if else if
if 语句语
- Linux服务器新手操作之二
周凡杨
Linux 简单 操作
1.利用关键字搜寻Man Pages man -k keyword 其中-k 是选项,keyword是要搜寻的关键字 如果现在想使用whoami命令,但是只记住了前3个字符who,就可以使用 man -k who来搜寻关键字who的man命令 [haself@HA5-DZ26 ~]$ man -k
- socket聊天室之服务器搭建
朱辉辉33
socket
因为我们做的是聊天室,所以会有多个客户端,每个客户端我们用一个线程去实现,通过搭建一个服务器来实现从每个客户端来读取信息和发送信息。
我们先写客户端的线程。
public class ChatSocket extends Thread{
Socket socket;
public ChatSocket(Socket socket){
this.sock
- 利用finereport建设保险公司决策分析系统的思路和方法
老A不折腾
finereport金融保险分析系统报表系统项目开发
决策分析系统呈现的是数据页面,也就是俗称的报表,报表与报表间、数据与数据间都按照一定的逻辑设定,是业务人员查看、分析数据的平台,更是辅助领导们运营决策的平台。底层数据决定上层分析,所以建设决策分析系统一般包括数据层处理(数据仓库建设)。
项目背景介绍
通常,保险公司信息化程度很高,基本上都有业务处理系统(像集团业务处理系统、老业务处理系统、个人代理人系统等)、数据服务系统(通过
- 始终要页面在ifream的最顶层
林鹤霄
index.jsp中有ifream,但是session消失后要让login.jsp始终显示到ifream的最顶层。。。始终没搞定,后来反复琢磨之后,得到了解决办法,在这儿给大家分享下。。
index.jsp--->主要是加了颜色的那一句
<html>
<iframe name="top" ></iframe>
<ifram
- MySQL binlog恢复数据
aigo
mysql
1,先确保my.ini已经配置了binlog:
# binlog
log_bin = D:/mysql-5.6.21-winx64/log/binlog/mysql-bin.log
log_bin_index = D:/mysql-5.6.21-winx64/log/binlog/mysql-bin.index
log_error = D:/mysql-5.6.21-win
- OCX打成CBA包并实现自动安装与自动升级
alxw4616
ocxcab
近来手上有个项目,需要使用ocx控件
(ocx是什么?
http://baike.baidu.com/view/393671.htm)
在生产过程中我遇到了如下问题.
1. 如何让 ocx 自动安装?
a) 如何签名?
b) 如何打包?
c) 如何安装到指定目录?
2.
- Hashmap队列和PriorityQueue队列的应用
百合不是茶
Hashmap队列PriorityQueue队列
HashMap队列已经是学过了的,但是最近在用的时候不是很熟悉,刚刚重新看以一次,
HashMap是K,v键 ,值
put()添加元素
//下面试HashMap去掉重复的
package com.hashMapandPriorityQueue;
import java.util.H
- JDK1.5 returnvalue实例
bijian1013
javathreadjava多线程returnvalue
Callable接口:
返回结果并且可能抛出异常的任务。实现者定义了一个不带任何参数的叫做 call 的方法。
Callable 接口类似于 Runnable,两者都是为那些其实例可能被另一个线程执行的类设计的。但是 Runnable 不会返回结果,并且无法抛出经过检查的异常。
ExecutorService接口方
- angularjs指令中动态编译的方法(适用于有异步请求的情况) 内嵌指令无效
bijian1013
JavaScriptAngularJS
在directive的link中有一个$http请求,当请求完成后根据返回的值动态做element.append('......');这个操作,能显示没问题,可问题是我动态组的HTML里面有ng-click,发现显示出来的内容根本不执行ng-click绑定的方法!
- 【Java范型二】Java范型详解之extend限定范型参数的类型
bit1129
extend
在第一篇中,定义范型类时,使用如下的方式:
public class Generics<M, S, N> {
//M,S,N是范型参数
}
这种方式定义的范型类有两个基本的问题:
1. 范型参数定义的实例字段,如private M m = null;由于M的类型在运行时才能确定,那么我们在类的方法中,无法使用m,这跟定义pri
- 【HBase十三】HBase知识点总结
bit1129
hbase
1. 数据从MemStore flush到磁盘的触发条件有哪些?
a.显式调用flush,比如flush 'mytable'
b.MemStore中的数据容量超过flush的指定容量,hbase.hregion.memstore.flush.size,默认值是64M 2. Region的构成是怎么样?
1个Region由若干个Store组成
- 服务器被DDOS攻击防御的SHELL脚本
ronin47
mkdir /root/bin
vi /root/bin/dropip.sh
#!/bin/bash/bin/netstat -na|grep ESTABLISHED|awk ‘{print $5}’|awk -F:‘{print $1}’|sort|uniq -c|sort -rn|head -10|grep -v -E ’192.168|127.0′|awk ‘{if($2!=null&a
- java程序员生存手册-craps 游戏-一个简单的游戏
bylijinnan
java
import java.util.Random;
public class CrapsGame {
/**
*
*一个简单的赌*博游戏,游戏规则如下:
*玩家掷两个骰子,点数为1到6,如果第一次点数和为7或11,则玩家胜,
*如果点数和为2、3或12,则玩家输,
*如果和为其它点数,则记录第一次的点数和,然后继续掷骰,直至点数和等于第一次掷出的点
- TOMCAT启动提示NB: JAVA_HOME should point to a JDK not a JRE解决
开窍的石头
JAVA_HOME
当tomcat是解压的时候,用eclipse启动正常,点击startup.bat的时候启动报错;
报错如下:
The JAVA_HOME environment variable is not defined correctly
This environment variable is needed to run this program
NB: JAVA_HOME shou
- [操作系统内核]操作系统与互联网
comsci
操作系统
我首先申明:我这里所说的问题并不是针对哪个厂商的,仅仅是描述我对操作系统技术的一些看法
操作系统是一种与硬件层关系非常密切的系统软件,按理说,这种系统软件应该是由设计CPU和硬件板卡的厂商开发的,和软件公司没有直接的关系,也就是说,操作系统应该由做硬件的厂商来设计和开发
- 富文本框ckeditor_4.4.7 文本框的简单使用 支持IE11
cuityang
富文本框
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<title>知识库内容编辑</tit
- Property null not found
darrenzhu
datagridFlexAdvancedpropery null
When you got error message like "Property null not found ***", try to fix it by the following way:
1)if you are using AdvancedDatagrid, make sure you only update the data in the data prov
- MySQl数据库字符串替换函数使用
dcj3sjt126com
mysql函数替换
需求:需要将数据表中一个字段的值里面的所有的 . 替换成 _
原来的数据是 site.title site.keywords ....
替换后要为 site_title site_keywords
使用的SQL语句如下:
updat
- mac上终端起动MySQL的方法
dcj3sjt126com
mysqlmac
首先去官网下载: http://www.mysql.com/downloads/
我下载了5.6.11的dmg然后安装,安装完成之后..如果要用终端去玩SQL.那么一开始要输入很长的:/usr/local/mysql/bin/mysql
这不方便啊,好想像windows下的cmd里面一样输入mysql -uroot -p1这样...上网查了下..可以实现滴.
打开终端,输入:
1
- Gson使用一(Gson)
eksliang
jsongson
转载请出自出处:http://eksliang.iteye.com/blog/2175401 一.概述
从结构上看Json,所有的数据(data)最终都可以分解成三种类型:
第一种类型是标量(scalar),也就是一个单独的字符串(string)或数字(numbers),比如"ickes"这个字符串。
第二种类型是序列(sequence),又叫做数组(array)
- android点滴4
gundumw100
android
Android 47个小知识
http://www.open-open.com/lib/view/open1422676091314.html
Android实用代码七段(一)
http://www.cnblogs.com/over140/archive/2012/09/26/2611999.html
http://www.cnblogs.com/over140/arch
- JavaWeb之JSP基本语法
ihuning
javaweb
目录
JSP模版元素
JSP表达式
JSP脚本片断
EL表达式
JSP注释
特殊字符序列的转义处理
如何查找JSP页面中的错误
JSP模版元素
JSP页面中的静态HTML内容称之为JSP模版元素,在静态的HTML内容之中可以嵌套JSP
- App Extension编程指南(iOS8/OS X v10.10)中文版
啸笑天
ext
当iOS 8.0和OS X v10.10发布后,一个全新的概念出现在我们眼前,那就是应用扩展。顾名思义,应用扩展允许开发者扩展应用的自定义功能和内容,能够让用户在使用其他app时使用该项功能。你可以开发一个应用扩展来执行某些特定的任务,用户使用该扩展后就可以在多个上下文环境中执行该任务。比如说,你提供了一个能让用户把内容分
- SQLServer实现无限级树结构
macroli
oraclesqlSQL Server
表结构如下:
数据库id path titlesort 排序 1 0 首页 0 2 0,1 新闻 1 3 0,2 JAVA 2 4 0,3 JSP 3 5 0,2,3 业界动态 2 6 0,2,3 国内新闻 1
创建一个存储过程来实现,如果要在页面上使用可以设置一个返回变量将至传过去
create procedure test
as
begin
decla
- Css居中div,Css居中img,Css居中文本,Css垂直居中div
qiaolevip
众观千象学习永无止境每天进步一点点css
/**********Css居中Div**********/
div.center {
width: 100px;
margin: 0 auto;
}
/**********Css居中img**********/
img.center {
display: block;
margin-left: auto;
margin-right: auto;
}
- Oracle 常用操作(实用)
吃猫的鱼
oracle
SQL>select text from all_source where owner=user and name=upper('&plsql_name');
SQL>select * from user_ind_columns where index_name=upper('&index_name'); 将表记录恢复到指定时间段以前
- iOS中使用RSA对数据进行加密解密
witcheryne
iosrsaiPhoneobjective c
RSA算法是一种非对称加密算法,常被用于加密数据传输.如果配合上数字摘要算法, 也可以用于文件签名.
本文将讨论如何在iOS中使用RSA传输加密数据. 本文环境
mac os
openssl-1.0.1j, openssl需要使用1.x版本, 推荐使用[homebrew](http://brew.sh/)安装.
Java 8
RSA基本原理
RS