MongoDB实用教程
[版权申明:本文系作者原创,转载请注明出处]
文章出处: http://blog.csdn.net/sdksdk0/article/details/51765219
作者:朱培 ID:sdksdk0
---------------------------------------------------------------------------------------------------------------
一、NoSql简介
传统的结构化的数据:固定长度,固定的类型
非结构化的数据:doc,ppt,pdf.
nosql(不仅仅是数据库可以干的事情),指的是非关系型数据库,以键值对存储,它的结构不固定,没一条记录可以有不一样的键,每条记录可以根据需要增加一些自己的键值对,这样就不会局限于固定的结构,可以减少一些时间和空间的开销。
常见的有:CouchDB、Redis、MongoDB、Neo4j、HBase、BigTable
二、MongoDB简介
MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
是用c++写的非关系型数据库,特点是高性能、易部署、易使用,存储数据非常方便,面向集合存储,易于存储对象类型的数据,模式自由,支持动态查询,支持完全索引,包含内部对象,支持复制和故障恢复,使用高效的二进制数据存储,包括大型对象,文件存储格式为BSON(一种json的扩展)。
三、MongoDB的体系结构
MongoDB 的文档(document),相当于关系数据库中的一行记录
集合(collection),相当于关系型数据库中的表的概念
文档(document)、集合(collection)、数据库(database)的层次结构如下图:

四、MongoDB安装配置
4.1 linux中安装
这里服务器用ubuntu15.10,在secureCRT中连接这个ubuntu。 首先使用 rz 上传window中从官网(https://www.mongodb.com/)下载的mongodb安装文件。
解压这个文件:
tar -xvzf mongodb-linux-x86_64-ubuntu1404-3.2.7.tgz
//重命名
mv mongodb-linux-x86_64-ubuntu1404-3.2.7 mongodb3.2
在目录中新建data,log和conf文件夹,在cong中新建mongodb.config,内容如下:
port=27017
dbpath=data
logpath=log/mongod.log
fork=true
启动服务:
./bin/mongod -f conf/mongodb.config
连接: mongo客户端连接
bin/mongo 192.168.44.131:27017/test
在linux中连接成功:
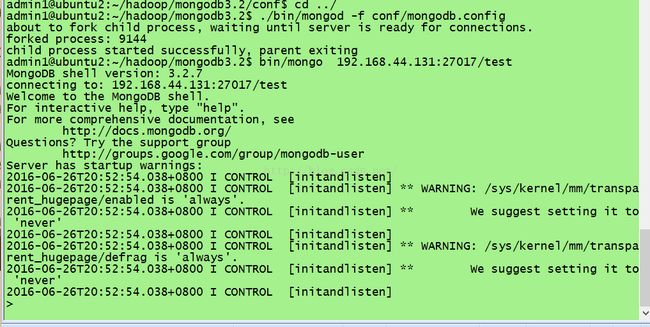
网页端:可以在浏览器中查看一下:http://www.192.168.44.131:27017/
关闭:
db.shutdownServer();
查看端口号: ps -ef|grep mongod|grep 27017
kill 相应端口
4.2 window中安装
安装过程与linux基本相同,就是配置一下环境变量,创建data,log,conf目录等。
如果是在window中,启动成功会是这样:

浏览器中访问:http://www.localhost:28017/
在mongodb有的版本中会提示端口号加1000的,所以我终于演示的时候是28017端口。

五、MongoDB安全控制
创建用户
安全性从高到低: 物理隔离、网络隔离、防火墙隔离、用户名密码。
开启权限认证: 在配置文件中——mongodb.config中设置:
auth=true
创建用户:(2.6之前是addUser)
createUser{user:"", pwd:"cleartext password", customData:{}, roles:[{role:"", db:""}] }
例如:创建用户名为zp,密码为a的用户
db.createUser({user:"zp",pwd:"a",roles:[{role:"userAdmin",db:"admin"},{role:"read",db:"test"}]})
登陆:
bin/mongod 192.168.44.131 -u zp -p a
角色类型
数据库角色 :read, readWrite,dbAdmin, dbOwner, userAdmin
集群角色:clusterAdmin,clusterManager
备份角色:backup,restore
其他:DBAdminAnyDatabase
六、MongoDB基本数据操作
//查看数据库
show dbs
//查看表
show tables
//创建数据库
use one_db//插入数据 格式:db.表名.insert({ json格式的数据 }) 例如:
db.one_db_collection.insert({ x:1 })
//查询刚才写入的表
show collections
查询具体内容 db.onedbcollection.find()
运行结果为:
{ "_id" : ObjectId("576fdc6e8224cdb105bcb3df"), "x" : 1 }
id是系统自动生成的,每条数据的id是唯一的 我们还可以自己给_id赋值:
db.one_db_collection.insert({x:2,_id:1})
批量插入多条数据
for(i=4;i<20;i++)db.one_db_collection.insert({x:i})统计条数:
db.one_db_collection.find().count()
过滤排序:
db.one_db_collection.find().skip(5).limit(3).sort({x:1})
从x:1开始,过滤前5条数据,然后从第6条开始选取3条数据,并进行排序。
演示效果如下:

//更新数据
db.one_db_collection.update({x:1},{x:100})
当插入这样的一条数据的时候:
db.one_db_collection.insert({x:100,y:100,z:100})
这个时候更新y的值,需要加$set符号:
db.one_db_collection.update({z:100},{$set:{y:200}})
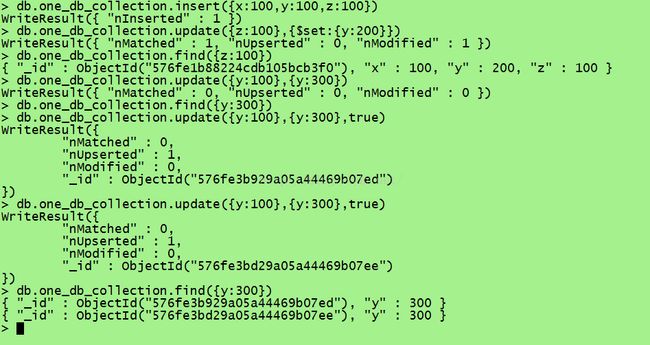
当更新一条不存在的数据的时候,如果加上true则会自动创建一条这个不存在的数据
db.one_db_collection.update({y:100},{y:300},true)
效果如下:
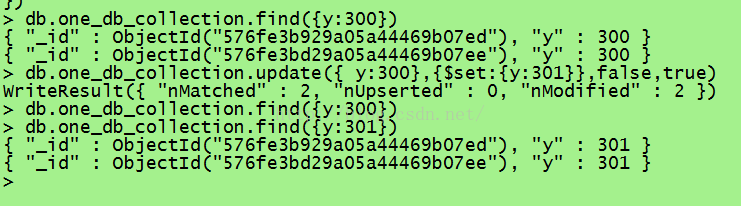
//一次性更新多条相同的数据
db.one_db_collection.update({ y:300},{$set:{y:301}},false,true)
如果有多条重名的且update时未加true,则只删除相同数据中的第一条数据。
//数据的删除
db.one_db_collection.remove({y:301})
//删除表
db.one_db_collection.drop()
七、查询索引
//查看当前表中索引
db.one_db_collection.getIndexes()
//创建索引
db.one_db_collection.ensureIndex({x:1})
x:1代表正向排序,x:-1代表逆向排序。如果文档数目较大,则创建索引时间会较长。如果系统中已经有很多文档了,这个时候就不能使用这个命令去创建索引了,否则严重影响数据库性能。 我们一般需要在使用数据库之前就要把索引创建完毕。 使用索引可以明显加快查询速度。

索引的属性 :
名字,由name指定;唯一性,unique指定;稀疏性,sparse指定
db.collection.ensureIndex({},{name:""})
db.collection.ensureIndex({},{unique:true/false})
db.collection.ensureIndex({},{sparse:true/false})索引的类型
- 1:_id索引
- 2:单键索引
- 3:多键索引
- 4:复合索引
- 5:过期索引
- 6:全文索引
- 7:地理位置索引
—id索引:是绝大多数集合默认建立的索引,对于每个插入的数据,MongoDB都会自动生成一条唯一的id字段。
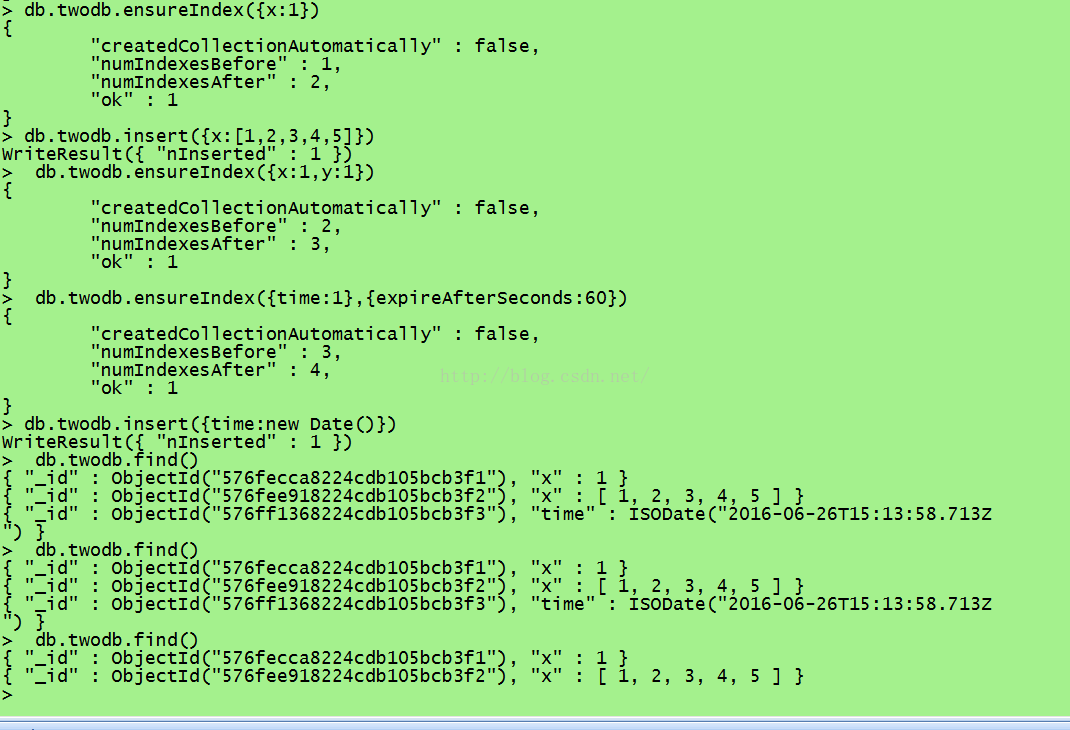
db.one_db_collection.ensureIndex({x:1})
例如查询结果为: { "_id" : ObjectId("576fecca8224cdb105bcb3f1"), "x" : 1 }
多键索引: 1.多键索引与单键索引创建形式相同,区别在于字段的值。 1)单键索引:值为一个单一的值,如字符串,数字或日期。 2)多键索引:值具有多个记录,如数组。
db.twodb.insert({x:[1,2,3,4,5]})
复合索引:
db.twodb.ensureIndex({x:1,y:1})
过期索引: 此索引过一段时间会过期,索引过期后,相应的数据会被删除,适合存储一些在一段时间之后会失效的数据,比如用户登录信息.
db.twodb.ensureIndex({time:1},{expireAfterSeconds:60}) //过期时间设置为60秒
db.twodb.insert({time:new Date()})
db.twodb.find() //60秒后就查不到数据了
过期索引的限制: 1.存储在过期索引字段的值必须是指定的时间类型,必须是ISODate或者ISODate数组,不能使用时间戳,否则不能自动删除。 例如 >db.twodb.insert({time:1}),这种是不能被自动删除的 2.如果指定了ISODate数组,则按照最小的时间进行删除。 3.过期索引不能是复合索引。因为不能指定两个过期时间。 4.删除时间是不精确的。删除过程是由MongoDB的后台进程每60s跑一次的,而且删除也需要一定时间,所以存在误差。
八、全文索引
对字符串与字符串数组创建全文可搜索的索引
创建全文索引的方法
db.threedb.ensureIndex({key:"text"})
db.threedb.ensureIndex({key_1:"text",key_2:"text"})
db.threedb.ensureIndex({"$**":"text"})
演示创建一个全文索引
db.threedb.ensureIndex({"article":"text"})
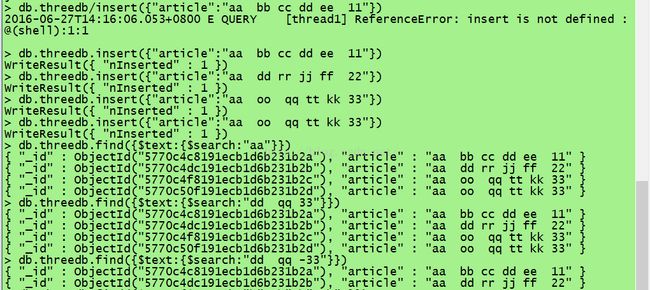
插入几条演示数据
db.threedb.insert({"article":"aa bb cc dd ee 11"})
db.threedb.insert({"article":"aa dd rr jj ff 22"})
db.threedb.insert({"article":"aa oo qq tt kk 33"})
使用全文索引进行查询 //搜索标题中有aa的记录
db.threedb.find({$text:{$search:"aa"}})
//多个关键字查找,查找只要含有dd qq 33中任何一个的就可以("或"关系)
db.threedb.find({$text:{$search:"dd qq 33"}})
//查找包含dd qq但是不包含33的数据,在关键词前面加上-号代表不包含:
db.threedb.find({$text:{$search:"dd qq -33"}})
//"与"关系查找,既包含aa 又包含qq的数据
db.threedb.find({$text:{$search:"\"aa\" \"qq\" "}})

//相似度查询
使用$meta:{score:{$meta:"textScore"}} 写在查询条件后面可以返回结果的相似度,与sort一起使用,可以达到很好的实用效果。
db.threedb.find({$text:{$search:"dd qq 33"}},{score:{$meta:"textScore"}})
db.threedb.find({$text:{$search:"dd qq 33"}},{score:{$meta:"textScore"}}).sort({score:{$meta:"textScore"}})

全文搜索的使用限制
- 每次查询,只能指定一个$text查询
- $text查询不能出现在$nor查询中
- 查询中如果包含了$text, hint不再起作用
- MongoDB全文索引还不支持中文
九、地理位置索引
将一些点的位置存储在Mongodb数据库中,并且创建索引,这些就是地理位置索引,之后就可以按照位置来查找其他的点了!
分类 1.2D索引,用于存储和查找平面上的点。 2.2Dsphere索引,用于存储和查找球面上的点。
查找方式: 1:查找距离某个点一定距离内的点 2:查找包含在某个区域内的点
2D索引
2D地理位置索引创建方式 db.collection.ensureIndex({w:"2d"}) 2D地理位置索引的取值范围以及表示方法 经纬度[经度,纬度] 经纬度取值范围 经度[-180,180] 纬度[-90,90]
//创建2d索引
db.location.ensureIndex({"w":"2d"})
//插入数据 db.location.insert({w:[20,30]}) db.location.insert({w:[160,90]}) db.location.insert({w:[20,90]}) db.location.insert({w:[80,120]})
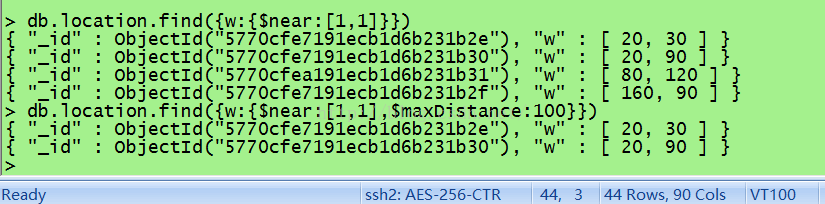
1、使用$near 查询距离某个点最近的点 db.collection.find({w:{$near:[x,y]}}) 使用$near默认返回最近的100个点,可以使用$maxDistance:x 限制返回的最远距离 查询距离(1,1)最近的点
db.location.find({w:{$near:[1,1]}})
查询在最远距离为100的点
db.location.find({w:{$near:[1,1],$maxDistance:100}})
2、使用$geoWithin 查询某个形状内的点 形状的表示方式: 1. $box 矩形,使用{$box:[[x1,y1],[x2,y2]]} 2. $center 圆形,使用 {$center:[[x,y],r]} 3. $polygon 多边形,使用 {$polygon:[[x1,y1],[x2,y2],[x3,y3]]}
//查询在(0,0)(80,80)之间的位置的数据 一个矩形
db.location.find({w:{$geoWithin:{$box:[[0,0],[80,80]]}}})
![]()
//圆形区域内,原心为(20,30),半径是80
db.location.find({w:{$geoWithin:{$center:[[20,30],80]}}})

//多边形
db.location.find({w:{$geoWithin:{$polygon:[[0,0],[40,30],[80,100],[30,60]]}}})

//geoNear的使用 格式: db.runCommand({geoNear:,near:[x,y],minDistance:maxDistance:num:})
查询距离(1,1)最远距离为100的,最多返回1条数据
db.runCommand({geoNear:"location",near:[1,1],maxDistance:100,num:1})

球面地理位置索引
2dsphere索引
GeoJSON:描述一个点,一条直线,多边形等形状。 格式: {type:'', coordinates:[list]} GeoJSON查询可支持多边形交叉点等,支持MaxDistance 和 MinDistance
db.collection.ensureindex({key: '2dsphere'})
十、索引构建情况分析
如何评判当前索引构建情况: 1.mongostat 工具
使用mongostat -h [ip]:端口 例如:
bin/mongostat -h 192.168.44.131:27017
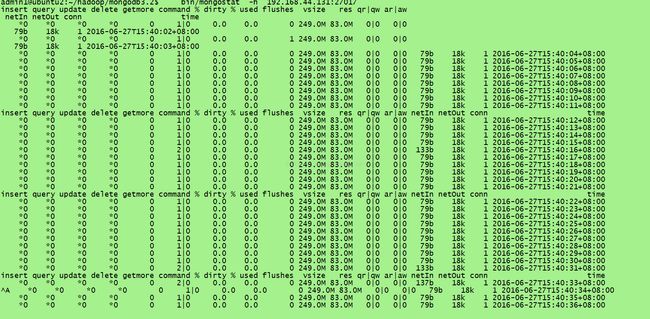
idx miss和qr|qw是需要我们重点关注的地方。
2.profile集合
db.getProfilingStatus()
db.getProfilingLevel()
当level为0代表profiling是关闭的. 级别为1时会记录所有超过slowms中设定的数目的操作。 级别为2时会记录你的所有操作。
3.日志分析
在配置文件中——mongodb.config中设置:
verbose=VVVVV
设置日志,5个v记录最详细的数据,1个v记录简单的日志信息。1到5个v来进行设置。
4.使用explain查询分析器分析
db.collection.find({x:1}).explain()
{ "cursor" : "BasicCursor", --使用的游标 "isMultiKey" : false, "n" : 1, "nscannedObjects" : 100000, --扫描的数据量 "nscanned" : 100000, --包含索引的扫描量 "nscannedObjectsAllPlans" : 100000, "nscannedAllPlans" : 100000, "scanAndOrder" : false, "indexOnly" : false, "nYields" : 781, "nChunkSkips" : 0, "millis" : 25, --查询消耗时间(毫秒) "server" : "XXX", "filterSet" : false }
十一、总结
1:为什么有这么多种索引?
不同的情况下使用对应情况下的索引,可以让查询速度更快,可以使查询得到进一步的优化。
2:什么时候使用什么索引才是合适的?
简单的说,索引就好比一本书的目录,你只要浏览标题就可以快速的找到具体内容是放在哪一页的。也就是说用find()查找时不用直接去搜索表,只要查找索引,就可以直接定位到你想查找的内容位置。索引带来的方便不是免费的,是以每次插入或更新(相当于删除并插入)时都要维护索引为代价的。所以如果一张表更多是用于查询而很少插入,那么就可以建立尽量多的索引以优化查询性能。相反如果一张表要经常插入或更新,则尽可能少用索引,有时甚至连主键都不建。
3:怎么判断索引建立的合适与否?
索引的建立必须慎重,对每个索引的必要性都应该经过仔细分析,要有建立的依据.因为太多的索引与不充分、不正确的索引对性能都毫无益处:在表上建立的每个索引都会增加存储开销,索引对于插入、删除、更新操作也会增加处理上的开销.另外,过多的复合索引,在有单字段索引的情况下,一般都是没有存在价值的;相反,还会降低数据增加删除时的性能,特别是对频繁更新的表来说,负面影响更大.