如何优雅地管理微信数据库?
最近每天在隔离点蹲着,发现隔离点的护士小姐姐每天两次在群里扒聊天记录统计一两百号人的体温真是太南了,所以想写个程序帮小姐姐自动收集,今天刚好隔离期满,也算是给这段特殊的经历留个纪念。
这篇文章主要内容是:
- 如何找到微信本地缓存数据库存放地址
- Mac OS 关闭 SIP 系统完整性保护
- lldb 断点调试得到缓存数据库地址
- 如何打开数据库
- lldb 断点调试得到数据库密码
- 使用 DB Browser for SQLite 打开数据库并重设密码
- 微信本地缓存数据库的结构介绍
- Contact - wccontact_new2.db - 好友信息
- Group - group_new.db - 群聊和群成员信息
- Message - {msg_0.db - msg_9.db} - 聊天记录和公众号文章
- Favorites - favorites.db - 收藏
- 如何解析数据库并提取目标信息
找到微信本地缓存数据库存放地址并获取数据库密码
捷径
对于Mac OS 系统,一个 short answer 是
/Users/xxx/Library/Containers/com.tencent.xinWeChat/Data/Library/Application Support/com.tencent.xinWeChat/
打开后,可以看到:
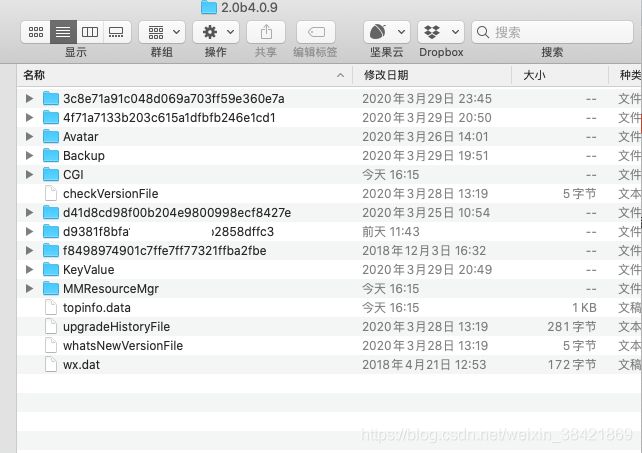
这里需要重点关注的是看起来很像 md5 码形式的文件,每个文件都代表一个曾经在你的电脑上登陆过并留下缓存的微信账号,有了下面将会介绍的解码方法,你可以逐个打开解析,确认到底哪个账号是你要找的。
总体来说,Windows 系统同理。
LLDB 调试
在没有任何信息的情况下,我们如何找到一个获取数据库地址的系统性方法?答案在于LLDB断点调试。
什么是 LLDB?
LLDB is a next generation, high-performance debugger. It is built as a set of reusable components which highly leverage existing libraries in the larger LLVM Project, such as the Clang expression parser and LLVM disassembler.
LLDB is the default debugger in Xcode on Mac OS X and supports debugging C, Objective-C and C++ on the desktop and iOS devices and simulator.
All of the code in the LLDB project is available under the standard LLVM License, an open source “BSD-style” license.
简言之,LLDB是一个有着 REPL(交互式解析器) 的特性和 C++ |Python 插件的开源调试器新一代高性能调试器。随着Xcode5的发布,LLDB调试器成为macOS系统调试的基础部分。对于开源和其他非基于GUI的应用程序调试的开发,可以将终端窗口中的LLDB用作传统的命令行调试器。
这里的主要的信息是:
- LLDB 是一个内建于 OS 终端窗口的命令行调试器
- LLDB 可以和系统运行的进程进行交互调试
这意味着,使用 LLDB 我们可以通过在命令行打断点来获得正在运行的进程的后台信息。这也是我们可以通过 LLDB 来寻找微信数据库地址以及获取访问密码的主要原因。
准备工作:关闭SIP系统完整性保护
系统完整性保护(SIP)是 OS X El Capitan 及更高版本所采用的一项安全技术,旨在帮助防止潜在恶意软件修改 Mac 上受保护的文件和文件夹,但这也造成了安装某些特殊版本软件的或者做特殊修改的时候权限不足。在这里就体现在使用 LLDB 调试时候,所有的调试语句都会被系统拒绝,因此在正式进行调试之前,一个重要的准备工作就是检查系统完整性保护(SIP)的开启状态,如果开启的话,要把它关闭。
-
检查 SIP 的开启状态
在终端里输入csrutil status回车,如果看到:System Integrity Protection status: enabled.
这说明的 SIP 已经开启,如果要继续调试的话,需要关闭。如果是
System Integrity Protection status: disabled.则说明 SIP 已经处于关闭状态,可以直接进行调试。 -
关闭 SIP
-
重启,并在开机的时候长按
Command和R -
进入系统恢复状态
-
点击屏幕顶部工具栏上的
实用工具,选择终端 -
在终端中输入
csrutil disable回车,会出现Successfully disabled System Integrity Protection. Please restart the machine for the changes to take effect.
-
再次重启生效
-
-
记得在调试后按照同样的步骤输入
csrutil enable重新开启 SIP 惹
LLDB 获取微信数据库地址
-
打开微信,但是不要登录
-
在命令行里输入
lldb -p $(pgrep WeChat)(lldb) process attach --pid 77855 Process 77855 stopped * thread #1, queue = 'com.apple.main-thread', stop reason = signal SIGSTOP frame #0: 0x00007fff6e878dfa libsystem_kernel.dylib`mach_msg_trap + 10 libsystem_kernel.dylib`mach_msg_trap: -> 0x7fff6e878dfa <+10>: retq 0x7fff6e878dfb <+11>: nop libsystem_kernel.dylib`mach_msg_overwrite_trap: 0x7fff6e878dfc <+0>: movq %rcx, %r10 0x7fff6e878dff <+3>: movl $0x1000020, %eax ; imm = 0x1000020 Target 0: (WeChat) stopped. Executable module set to "/Applications/WeChat.app/Contents/MacOS/WeChat". Architecture set to: x86_64h-apple-macosx-. -
这时候微信的进程被我们暂停了,需要在命令行中输入
c回车,可以看到:Process 77855 resuming
-
扫码登陆微信
-
输入
br set -n '[WCTDatabase initWithPath:]Breakpoint 1: where = WCDB`-[WCTDatabase(Database) initWithPath:], address = 0x000000010e54120a -
进入
聊天备份与恢复页面点击恢复聊天记录到手机触发断点Process 78136 stopped * thread #1, queue = 'com.apple.main-thread', stop reason = breakpoint 1.1 frame #0: 0x000000010e54120a WCDB`-[WCTDatabase(Database) initWithPath:] WCDB`-[WCTDatabase(Database) initWithPath:]: -> 0x10e54120a <+0>: pushq %rbp 0x10e54120b <+1>: movq %rsp, %rbp 0x10e54120e <+4>: pushq %r15 0x10e541210 <+6>: pushq %r14 Target 0: (WeChat) stopped. -
在命令行输入
po $arg3/Users/xxxx/Library/Containers/com.tencent.xinWeChat/Data/Library/ApplicationSupport/com.tencent.xinWeChat/2.0b4.0.9/Backup/d9381f8bfa1ab8fa0f5e54b2858dffc3/EA2CC6CD-FCD2-4570-9CAC-9C95FF7E348B/Backup.db
-
以上可以得到微信数据库的本地存储地址,确切地来说是微信备份文件的存储地址,往上一层文件夹就可以找到微信好友和聊天记录数据库
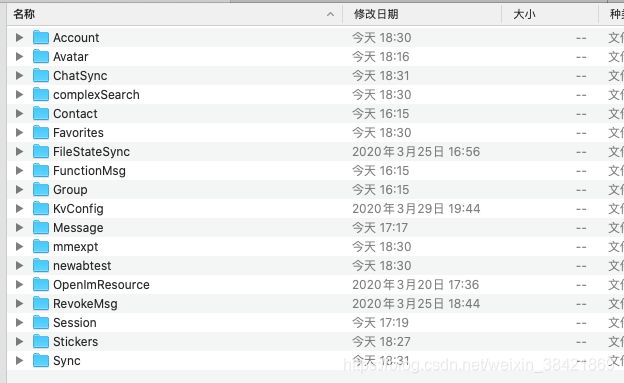
LLDB 获取微信数据库密码
-
接着上面的操作在命令行里输入
br set -n sqlite3_keyBreakpoint 2: 2 locations. -
输入
memory read --size 1 --format x --count 32 $rsi0x7fff78a12bc9: 0x69 0x6e 0x59 0x74 0x57 0x69 0x74 0x68 0x7fff78a12bd1: 0x50 0x61 0x34 0x68 0x3a 0x00 0x73 0x65 0x7fff78a12bd9: 0x74 0x53 0x70 0x65 0x65 0x64 0x4d 0x75 0x7fff78a12be1: 0x6c 0x74 0x69 0x70 0x6c 0x69 0x65 0x72 -
按照以下的步骤处理上面的输出即可得到 64 位密码:
-
只保留
:右边的数据0x69 0x6e 0x59 0x74 0x57 0x69 0x74 0x68 0x50 0x61 0x34 0x68 0x3a 0x00 0x73 0x65 0x74 0x53 0x70 0x65 0x65 0x64 0x4d 0x75 0x6c 0x74 0x69 0x70 0x6c 0x69 0x65 0x72 -
删掉所有的
0x69 6e 59 74 57 69 74 68 50 61 34 68 3a 00 73 65 74 53 70 65 65 64 4d 75 6c 74 69 70 6c 69 65 72 -
删掉所有的空格和换行
696e597457697468506134683a0073657453706565644d756c7469706c696572 -
以上就是打开数据库的 64 位密码啦,该密码适用于聊天记录,好友信息,群聊成员等各个数据库
-
打开数据库并重设密码
微信存储数据用的是轻量级的数据库工具 SQLite ,有很多软件可以打开,这里以 DB Browser for SQLite 为例。比如我双击聊天记录数据库 msg_0.db,会出现以下界面:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7slG29fg-1585744780662)(/Users/mengjiexu/Library/Application Support/typora-user-images/image-20200401184709226.png)]](http://img.e-com-net.com/image/info8/fcc427eea9e446afbef2c5509a69297a.jpg)
注意:
- Encryption settings 选择 SQLClipher 3 defaults
- 右边的密码形式选择 Raw key
- 密码填写 0x 加上之前获取的 64 位密码,所以一共是 66 位
如果正确操作的话,这里应该可以打开数据库了。这里我们来看下数据库的结构,这里可以看出这个数据库里一共有 144 张表,每张表对应一个微信好友/群聊/公众号的聊天记录。
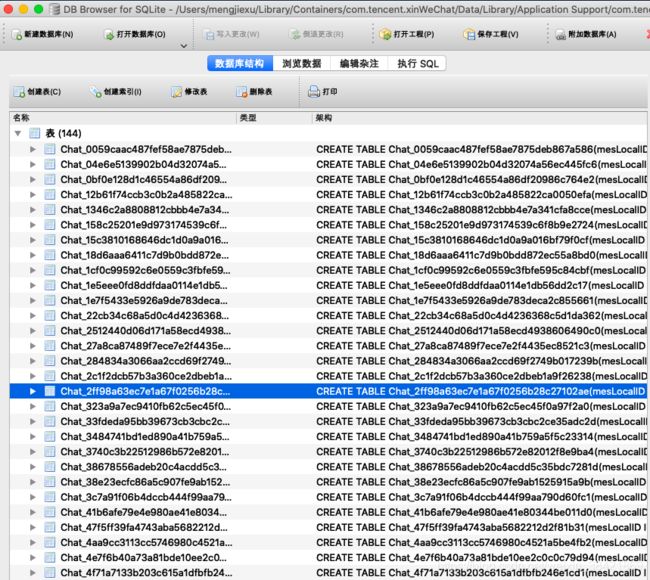
一个典型的表的属性如下:
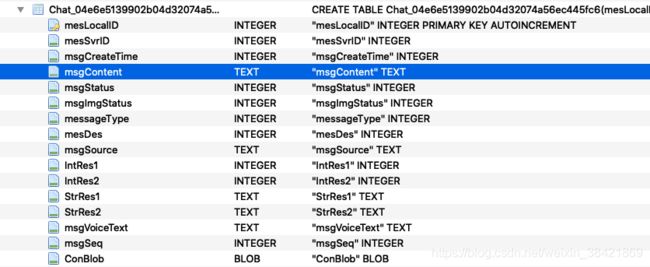
最重要的几个属性为:
- msgCreateTime 聊天时间戳
- msgContent 聊天内容
- messageType 聊天类型 文字为1
点击浏览数据可以进行预览:
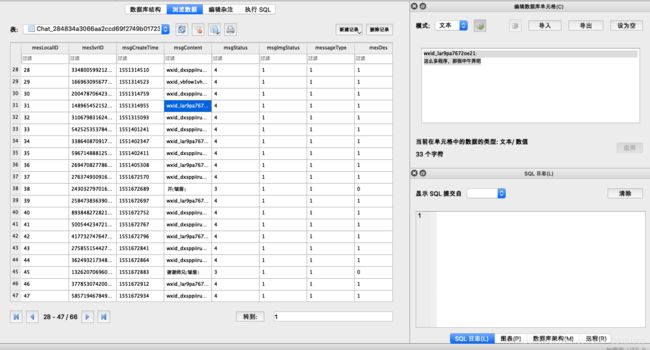
为了避免每次打开都输入密码,我们可以移除数据库的密码。在 DB Browser for SQLite 中的具体操作是 工具 - 设置加密 - OK,即直接重设为空密码,这样也方便我们进一步提取数据。

本地存储的微信数据库里都有什么?
我翻了翻几个文件夹,认为以下四项最有分析意义,当然还有其他的小伙伴们可以自行发掘。
- Contact - wccontact_new2.db - 好友信息
- Group - group_new.db - 群聊和群成员信息
- Message - {msg_0.db - msg_9.db} - 聊天记录和公众号文章
- Favorites - favorites.db - 收藏
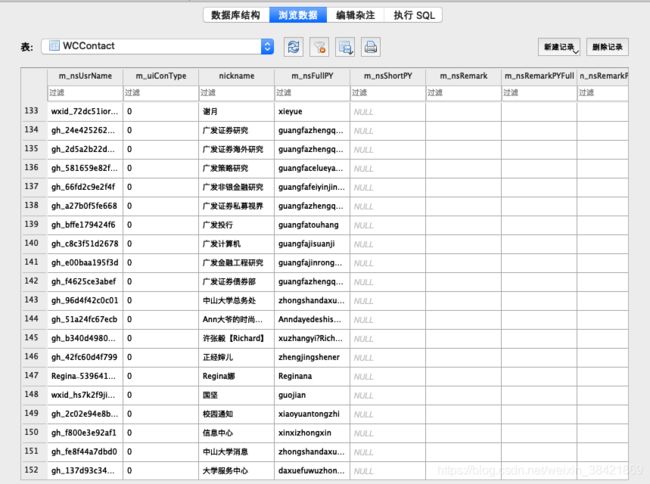
微信好友/公众号
首先来看联系人数据库 wccontact_new2.db,这里主要就是一张表 WCContact,这里面存储了我们加的微信好友和关注的公众号的信息,主要是昵称和微信号 m_nsUsrName。一般公众号以 gh_ 开头。这里的 m_nsUsrName 非常重要,因为聊天数据库里的表名都是 md5 编码后的 m_nsUsrName。比如公众号 广发证券研究 的 m_nsUsrName 为 gh_24e4252623cf,md5 编译后即为 41cbc56f1e10ab139339a40a4df2132d,因此聊天记录数据库里的 Chat_41cbc56f1e10ab139339a40a4df2132d 即为这个公众号的全部历史信息。
群聊/群成员
group_new.db 数据库里有两张表,分别是 GroupContact 和 GroupMember。其中 GroupContact 和微信好友数据库很像,只不过里面存储的是群聊名称和群聊 m_nsUsrName。用法和联系人数据库一样,都是通过对 m_nsUsrName 进行 md5 编译索引到聊天记录数据库里的表。
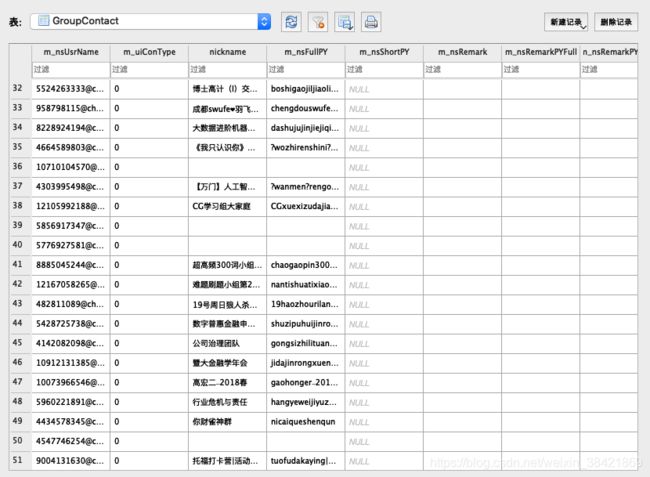
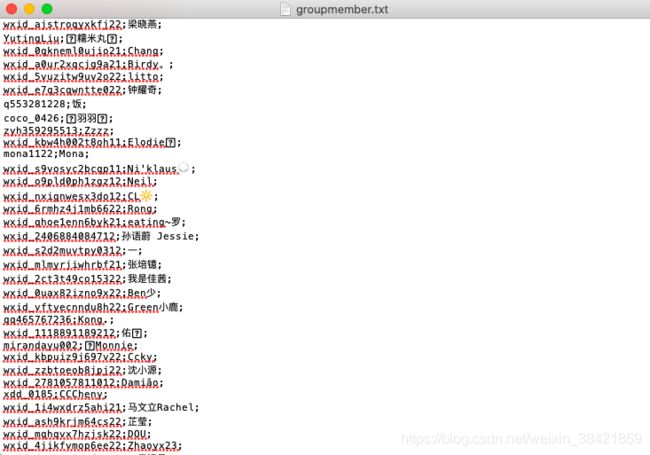
GroupMember 表里包含了你加群里所有群成员的微信号和昵称,不管有没有加过好友。所以一般如果联系人数据库里有几百个的话,这个表里往往有几千上万条记录。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LsJWBgFs-1585744780694)(/Users/mengjiexu/Library/Application Support/typora-user-images/image-20200401195259014.png)]](http://img.e-com-net.com/image/info8/6bd0bfcd78e8493382fb88da0459f609.jpg)
收藏
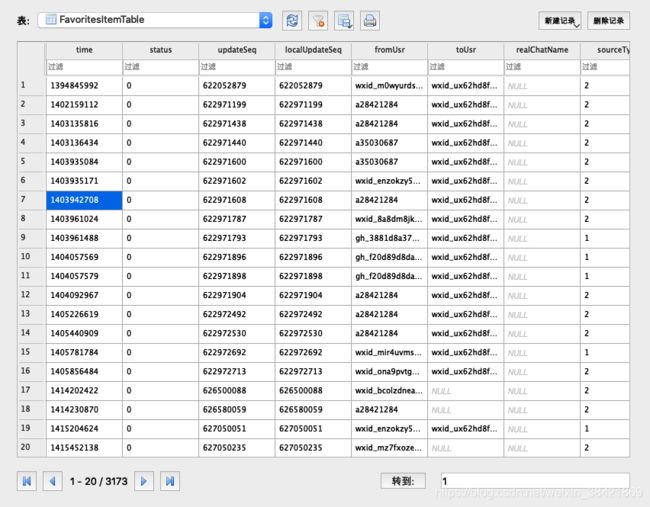
favorites.db 里面有 8 张表,其中最重要的是两个,FavoriteItemTable 和 FavoriteSearchTable。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-L46rj09X-1585744780703)(/Users/mengjiexu/Library/Application Support/typora-user-images/image-20200401195806062.png)]](http://img.e-com-net.com/image/info8/6dbde6674cb640d989b247f4d146b5c2.jpg)
FavoriteSearchTable 给了收藏的标题和 localID。
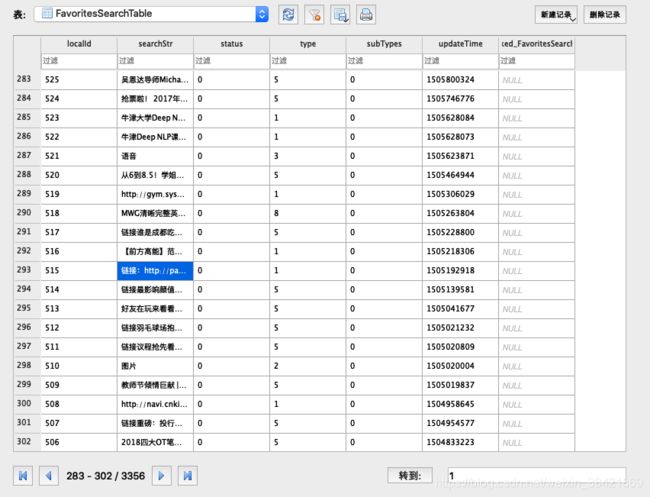
FavoriteItemTable 给了收藏时间戳,收藏内容链接,以及收藏内容来源用户等,并且可以和 FavoriteSearchTable 通过 localID 互相索引。
聊天记录
见上文
如何解析数据库并提取目标信息?
使用解密脚本打开数据库:
from pysqlcipher import dbapi2 as sqlite
output = 'output_db_whole.db'
key = 'a3c77a9'
conn = sqlite.connect(db)
c = conn.cursor()
c.execute("PRAGMA key = '" + key + "';")
c.execute("PRAGMA cipher_use_hmac = OFF;")
c.execute("PRAGMA cipher_page_size = 1024;")
c.execute("PRAGMA kdf_iter = 4000;")
c.execute("SELECT name FROM sqlite_master WHERE type='table'")
c.execute("ATTACH DATABASE '" + output + "' AS db KEY '';")
c.execute("SELECT sqlcipher_export('db');")
c.execute("DETACH DATABASE db;")
conn.close()
从群聊数据库里提取群聊列表,使用 transmd5 函数获得群聊索引序号 md5 编码,并写入文本文件中:
import sqlite3
import time, datetime
import hashlib
conn = sqlite3.connect('group_new.db')
print("Opened database successfully")
def transmd5(string):
m = hashlib.md5(string.encode(encoding='UTF-8')).hexdigest()
return(m)
def transfertime(timeStamp):
timeArray = time.localtime(timeStamp)
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
return(otherStyleTime)
cursor = conn.execute("SELECT m_nsUsrName, nickname, m_nsFullPY, m_nsChatRoomMemList from GroupContact")
f = open('groupcontact.txt','w')
for row in cursor:
for i in range(3):
f.write(row[i]+';')
f.write(transmd5(row[0]))
f.write('\n')
print("Operation done successfully")
conn.close()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YUEzSPk8-1585744780710)(/Users/mengjiexu/Library/Application Support/typora-user-images/image-20200401201319956.png)]](http://img.e-com-net.com/image/info8/45451f71150e48de917ffb910095be7d.jpg)
从以上结果里面,我们可以得到我们想要的群聊在数据库中的 md5 编码 Chat_aa309112204d5fd125c5a8bad609ff25。同时提取群聊成员列表,准备与聊天记录进行合并:
conn = sqlite3.connect('group_new.db')
cursor = conn.execute("SELECT m_nsUsrName, nickname from GroupMember")
f = open('groupmember.txt','w')
for row in cursor:
for i in range(2):
f.write(row[i]+';')
f.write('\n')
conn.close()
由于聊天记录被自动拆分到了 10 个数据库文件 msg_0.db - msg_9.db 里,需要遍历所有的数据库文件获取每个数据库里所有的表名才能确定我们要的聊天记录到底存储在哪个文件里。
def sheetname(i):
conn = sqlite3.connect('msg_%s.db'%i)
return(conn)
def getdata(conn):
cursor = conn.execute("select name from sqlite_master where type='table'")
tab_name=cursor.fetchall()
tab_name=[line[0] for line in tab_name]
return(tab_name)
f = open('sheetname.txt','a')
for j in range(10):
conn = sheetname(j)
tab_name = getdata(conn)
for i in tab_name:
f.write(i+','+'sheet_%s'%j+'\n')
conn.close()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8NderBKA-1585744780715)(/Users/mengjiexu/Library/Application Support/typora-user-images/image-20200401201816684.png)]](http://img.e-com-net.com/image/info8/8bfe4fa1cc8847d29bbb3d47eeb15d30.jpg)
经过这一步,我们可以精确定位想要的群聊到底在哪个数据库文件里的哪张表里。于是可以从聊天数据库里提取指定群聊信息的聊天记录,转换时间戳,使用正则表达式筛选符合指定信息的聊天记录,并写入文本文件中:
conn = sqlite3.connect('msg_0.db')
def transfertime(timeStamp):
timeArray=time.localtime(timeStamp)
otherStyleTime=time.strftime("%Y-%m-%d %H:%M:%S",timeArray)
return(otherStyleTime)
cursor=conn.execute("SELECT msgCreateTime,messageType,msgContent from Chat_aa309112204d5fd125c5a8bad609ff25 where messageType=1")
f = open('chatrecord.txt','w')
for row in cursor:
a = re.findall('[\d]+.*[\d]+\.[\d]',row[2].split(':')[-1])
if a != []:
f.write("%s;%s;%s;\n"%(transfertime(row[0]),row[2].split(':')[0],a))
conn.close()

如果不通过正则表达式筛选的话,得到的就是文本格式的聊天记录:
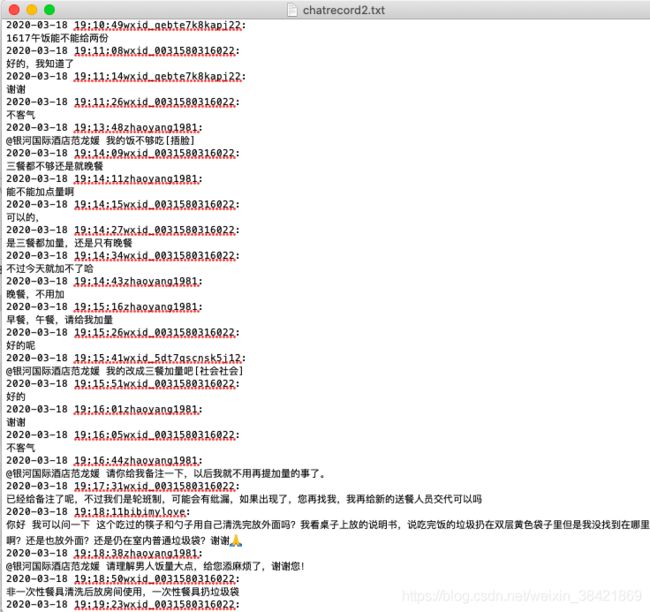
这里存在一个问题是,聊天记录里只有每个人的微信号,没有昵称,因此我们需要把这张表和群聊成员表合并,并导出最终的结果:
import pandas as pd
import csv
df1 = pd.read_table('/Users/mengjiexu/PycharmProjects/wx/chatrecord.txt',sep = ';')
df1.columns = ['timestamp','wxindex','record','']
df2 = pd.read_table('/Users/mengjiexu/PycharmProjects/wx/groupmember.txt',sep = ';',error_bad_lines=False,quoting=csv.QUOTE_NONE)
df2.columns = ['wxindex','nickname','']
df = pd.merge(df1,df2,on = 'wxindex',how='left')
df.to_csv('resultspd.csv',mode ='w',encoding='gb18030')
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nfy9xIZz-1585744780719)(/Users/mengjiexu/Library/Application Support/typora-user-images/image-20200401202426435.png)]](http://img.e-com-net.com/image/info8/5c787364966d4255b7ebea35d44176af.jpg)
如果对自己的好友分布感兴趣,还可以导出自己的好友和公众号列表,并进行进一步的分析:
conn = sqlite3.connect('wccontact_new2.db')
cursor = conn.execute("SELECT m_nsUsrName, nickname, m_nsFullPY, m_nsAliasName from WCContact")
#df = pd.DataFrame(cursor, columns=['username','nickname','fullpy','aliasname'])
#df.to_csv('contact.csv', sep=',', mode='a', encoding='utf8')
f = open('contact.txt','a')
for row in cursor:
for i in range(3):
f.write(row[i]+',')
f.write('\n')
conn.close()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EmnGRZlN-1585744780720)(/Users/mengjiexu/Library/Application Support/typora-user-images/image-20200401202802754.png)]](http://img.e-com-net.com/image/info8/f259022db4554ac19f0cacc544938013.jpg)
参考链接
- https://www.jianshu.com/p/0f41c120160d
- https://jingyan.baidu.com/article/f0e83a255eea0622e591013d.html
- https://www.jianshu.com/p/90224ab9cdf2
- http://xferris.cn/dao-chu-wei-xin-bei-fen-de-mac/
- https://www.jianshu.com/p/93bbcda3133a