logstash插件开发环境搭建+kafka-input插件代码
文章目录
- 背景:
- 1 总体介绍
- 1.1 ruby介绍
- 1.2 Gem介绍
- 1.3 Bundler介绍
- 2 环境安装
- 2.1 Windows
- 2.1.1 安装Jruby
- 2.1.2 RubyGem/bundler
- 2.1.2.1 安装RubyGem
- 2.1.2.2 The Gemspec/Gemfile
- 2.1.2.2.1 The Gemspec
- 2.1.2.2.2 Gemfile
- 2.1.2.2.3 安装bundler
- 2.1.2.3 踩坑问题ssl
- 2.1.3 安装RubyMine
- 2.2 Linux
- 2.2.1 rvm安装
- 2.2.2 Jruby安装
- 2.2.3 gem/bundle
- 3 代码开发
- 3.1 Logstash一些规定
- 真正的代码逻辑
- 3.1.1 踩坑问题given1,except 0…
- 3.2 依赖的设置
背景:
通过本文可以上手搭建开发logstash的环境和开发logstash插件,并且末尾赋了一个kafka-input的插件例子,更好的帮助你熟悉插件开发。
通过本文可以进行ruby开发logstash插件,最近需要自定义一个插件(input),读取kafka(通过ruby调用kafka的jar)。(仅仅是给出大家一个总体脉络,和环境的搭建与介绍,具体详细可以参考文章中的链接。)
题外话……这简直是我的一部踩坑血泪史!!!!对于我一个英语渣渣来说,百度和google不到,简直是瑟瑟发抖,硬着头皮看了很多官方文档。当然这坑还是不少的,但是整体下来还是建议大家多多尝试看看官网,会有不少收获,下面博文为总体的过程,是一个大体方向性的文章,如有错误希望大家多多指出。
可以先看下github:https://github.com/brinjaul/logstash-input-test3.git
赠人玫瑰,手有余香,你的关注,我的动力!
更多分享可见:
1 总体介绍
1.1 ruby介绍
面向对象程序设计的服务器端脚本语言,在 20 世纪 90 年代中期由日本的松本行弘设计并开发。在 Ruby 社区,松本也被称为马茨(Matz)。Ruby 可运行于多种平台,如 Windows、MAC OS 和 UNIX 的各种版本。
这门语言最大特点就是为了简单再简单我们的编码,立志于代码就像读英文文章一样!!!!牛不牛吧!语法超简单,大家可以鲁一遍菜鸟教程的语法。
1.2 Gem介绍
学过java的朋友都知道library对应jar,而maven来拉取管理jar包,而ruby也属于面向对象,他同样也有自己的library,对应的后缀.gem的文件,而拉取.gem文件使用的命令就是 gem ,maven有很多源例如阿里源等,所以gem也有源,例如淘宝的,还有什么https://gems.ruby-china.com/ 这些都是国内的源,默认的是国外源https://rubygems.org/
但是要注意!!!!RubyGem工具仅仅是拉取源,并没有做到管理源。
1.3 Bundler介绍
在ruby中,library,是存放在整个ruby的library中,打个比喻,gem拉取的gem依赖会存在整个ruby的环境中,而每个ruby开发需要的项目,可不需要整个library,所以bundler管理工具应运而生!使用Gemfile和来管理。
2 环境安装
一般ruby开发会使用专门的ide就是RubyMine,当然你也可以使用idea,但是目前我使用的是RubyMine。
2.1 Windows
2.1.1 安装Jruby
Jruby他就是Ruby,因为他是java实现的解释器,所以多个J,这样是不是java和ruby有点一家亲的关系啦,顺带提一句原生的ruby解释器是不存在真正的意义的多线程,但是Jruby解释器基于java真正提供多线程!(顺便说下如果你想用ruby开发logstash插件,那到最好你会发现根本不行,下载不下来依赖而且运行不了,其实官网也说了,用jruby,但是我以为没有那么严格,结结实实的踩坑了…)

官网连接:https://www.jruby.org/download
截图建议大家下载这里
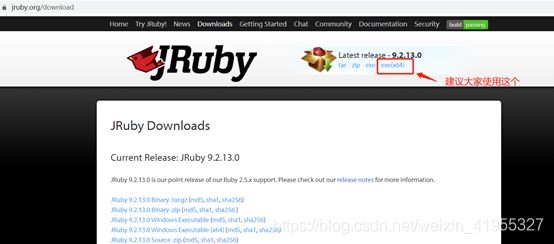
下载后一路next
最后验证下命令:(大家前提要安装好jdk,我jdk是8)
C:\Users\46323>jruby -v
jruby 9.2.13.0 (2.5.7) 2020-08-03 9a89c94bcc Java HotSpot™ 64-Bit Server VM 25.31-b07 on 1.8.0_31-b13 +jit [mswin32-x86_64]
2.1.2 RubyGem/bundler
2.1.2.1 安装RubyGem
gem源官网提供了几种的下载安装,但是相信我,采用下面的是最快了
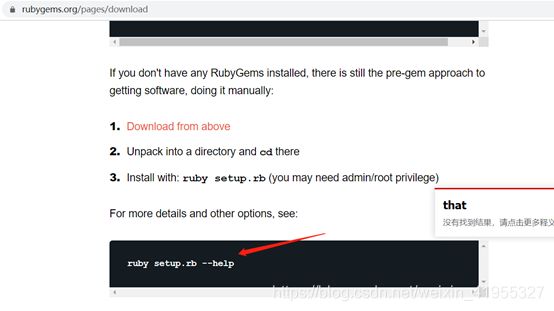
https://rubygems.org/pages/download
点击这里下载zip

所以接下来如何使用下载的zip 来安装,前提是Jruby安装好的基础上执行了:
jruby –S setup.rb (##注意在解压的目录下执行)

也许你会疑惑为啥要这么写,这里要结合两个文档
1 https://rubygems.org/pages/download
但下面这是使用ruby命令,可我们安装的是jruby
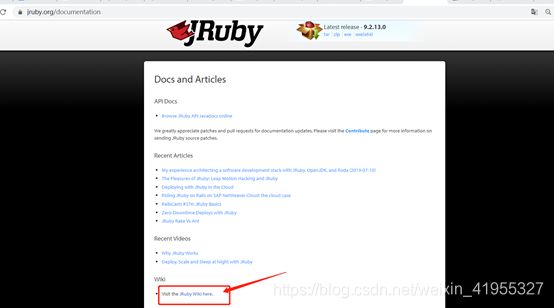
2 https://www.jruby.org/documentation
这里有说明使用jruby的具体命令
来到 此页https://github.com/jruby/jruby/wiki
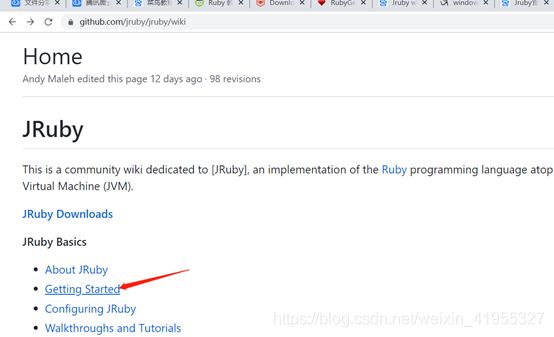
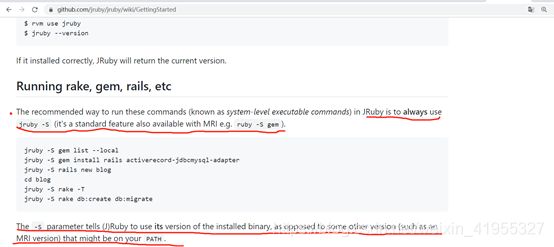
意思是官方推荐使用的一个标准方法,
所以总结出,安装RubyGem的命令应该是
jruby -S setup.rb
2.1.2.2 The Gemspec/Gemfile
2.1.2.2.1 The Gemspec
https://guides.rubygems.org/what-is-a-gem/ 这里介绍了什么是Gemspec文件中的定义,,感兴趣看这里。
这里介绍了 gemspec文件中每个字段的的意思入口,点击SpecifcationReference的红色字体。这里仅仅是指出,如果你想了解更多可以查看,但是我们后面会简单介绍logstash插件开发用的几个字段,现在大可不必扎入这些细节。(在这里我特别想说一句,学习东西要不求甚解,一定要站在一个上地的视角来看待这些技术总体脉络联系与关联,如果直接扎入到某个细节中不仅浪费时间,而且还耗掉了自己的学习热情,这是最可怕的!)
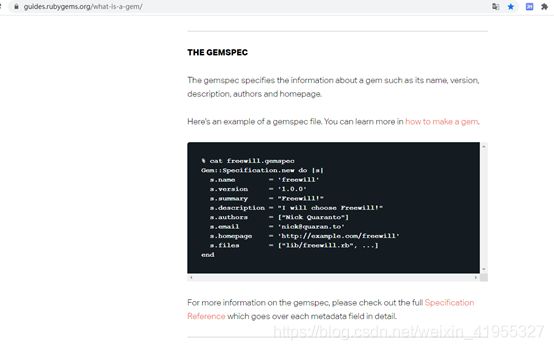
2.1.2.2.2 Gemfile
Gemfile这个概念应该是来自bundler工具提出的,看官网的说明,https://www.bundler.cn/
这里插图一张救命稻草!!!!!!!!!

怎么才能更多知道这些配置和工作机理了
看bundler官方网 关于source 和bundler的定义
2.1.2.2.3 安装bundler
https://www.bundler.cn/
2.1.2.3 踩坑问题ssl
如果你使用bundle install,会报错拉不了,没有验证ssl……
问题的截图就不上了,报错原因是rubygems.org 官网显示什么ssl没有权限验证,这真的是让我头大,怎么办,终于在bundler官网上找到答案:
https://www.bundler.cn/gemfile.html
(所以需要在rubygems.rog注册一个账号,并且在本地使用名命令:![]() )
)

然而这并没有结束,因为报错ssl 是来自ruby-china.com 源的,这是因为我们下载的,gem的zip包会默认,首先找此源,此时解决办法是删除
C:\Users\myhme.bundle 找到用户目录下的.bundle 文件夹中的conf文件,留下
RubyGems.org的源
2.1.3 安装RubyMine
RubyMine连接为:链接: https://pan.baidu.com/s/1vAJrRUEvjneBTbDpi48DpQ 提取码: g2w9
2.2 Linux
(这不一定是必须的,你可以跳过此部分)
2.2.1 rvm安装
rvm是一个管理ruby版本的工具,你可以理解为,我们电脑里面有多个版本的jdk,所以设计一个问题,怎么能自如的使用某个版本的ruby这就是rvm要做的事情。通常使用命令为 rvm use xxx
下面是三行命令
1 gpg --keyserver hkp://keys.gnupg.net --recv-keys 409B6B1796C275462A1703113804BB82D39DC0E3 7D2BAF1CF37B13E2069D6956105BD0E739499BDB
2 \curl -sSL https://get.rvm.io | bash -s stable
3 source /etc/profile.d/rvm.sh
2.2.2 Jruby安装
1 rvm install jruby
2 rvm use jruby
3验证 jruby -v
2.2.3 gem/bundle
1 gem install bundle
2 gem install rspec
3 代码开发
3.1 Logstash一些规定
这里要介绍logstash,在做插件开发时应该遵循的一些规定,才能打包出真正适合logstash使用的的包,在这里可以愉快的百度啦,有很多关于插件开发的资料。
https://www.elastic.co/guide/en/logstash/current/input-new-plugin.html 这里有生成插件的方法,不过你不用进去看了命令就在下方啦!
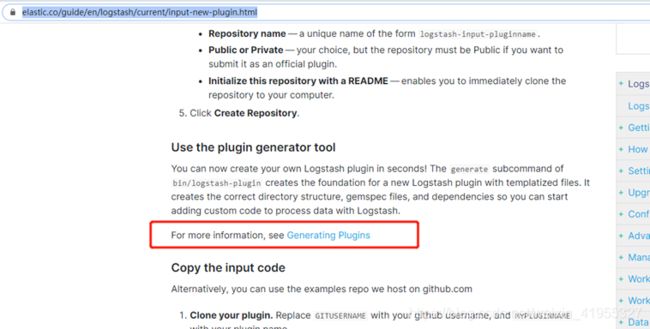
这里说明可以使用logstash自带的工具生成插件模板
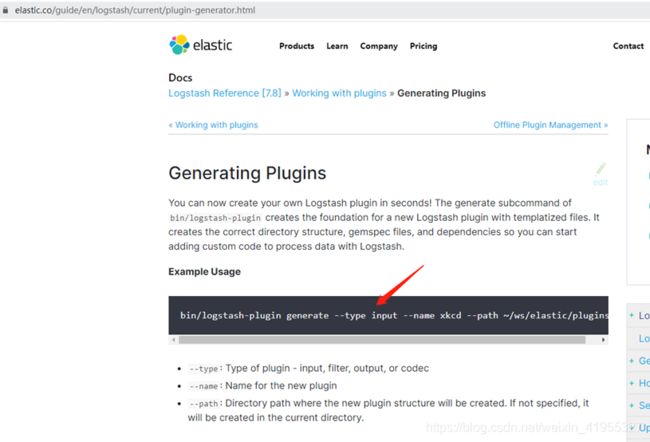
bin/logstash-plugin generate --type input --name xkcd --path ~/ws/elastic/plugins
• --type: 可以生成哪些插件模板的类型: input, filter, output, or codec
• --name: 生成的插件起个名字
• --path: 生成的模板制定一个路径存放,默认存放当前路径
logstash input插件必须实现另个方法:register 和run
Register
类似于调用run的前置处理的钩子方法。
Run
真正的代码逻辑
下面附上我抄袭kafka插件源码的代码,(不敢说借鉴,抄袭吧)
其实代码逻辑很简单,只是作为java开发,我们如何调用jar包的小点需要注意,例如jar包的引用,以及引入jar包后如何调用,具体不在详细介绍,可以看github的jruby调用实例,本文目的是给出方向性的引导,https://github.com/jruby/jruby/wiki/CallingJavaFromJRuby
# encoding: utf-8
require "logstash/inputs/base"
require "stud/interval"
require "socket" # for Socket.gethostname
require 'java'
require_relative '../../org/apache/kafka/kafka-clients/2.3.0/kafka-clients-2.3.0.jar'
require_relative '../../org/slf4j/slf4j-api/1.7.26/slf4j-api-1.7.26.jar'
#require_relative 'lib\org\apache\kafka\kafka-clients\2.3.0\kafka-clients-2.3.0.jar'
#require_relative 'lib\org\slf4j\slf4j-api\1.7.26\slf4j-api-1.7.26.jar'
##Generate a repeating message.
#
##This plugin is intented only as an example.
class LogStash::Inputs::Test3 < LogStash::Inputs::Base
config_name 'test3'
default :codec, 'plain'
config :bootstrap_servers, :validate => :string, :default => "localhost:9092"
config :client_id, :validate => :string, :default => "fjpp"
config :group_id, :validate => :string, :default => "fjpp"
config :auto_offset_reset, :validate => :string, :default => "earliest"
config :consumer_threads, :validate => :number, :default => 5
config :max_poll_records, :validate => :string, :default => "3"
config :topics, :validate => :string, :default => "audit"
config :poll_timeout_ms, :validate => :number, :default => 100
config :decorate_events, :validate => :boolean, :default => false
public
def register
begin
puts "register-----------begin"
@runner_threads = []
rescue Exception => e
puts "register ex"
puts e.message
raise e
end
end
##def register
public
def run(logstash_queue)
begin
puts "run-----------begin"
@runner_consumers = consumer_threads.times.map { |i| create_consumer("#{client_id}-#{i}") }
@runner_threads = @runner_consumers.map { |consumer| thread_runner2(logstash_queue,consumer) }
@runner_threads.each { |t| t.join }
rescue Exception => e
puts "run ex"
puts e.message
raise e
end
end
public
def stop
# if we have consumers, wake them up to unblock our runner threads
@runner_consumers && @runner_consumers.each(&:wakeup)
end
public
def thread_runner2(logstash_queue, consumer)
puts "thread------runner-------------begin"
Thread.new do
begin
pattern = java.util.regex.Pattern.compile(topics) ### 需要转换
consumer.subscribe(pattern)
while !stop?
records = consumer.poll(poll_timeout_ms)
codec_instance = @codec.clone
next unless records.count > 0
for record in records do
codec_instance.decode(record.value.to_s) do |event|
decorate(event)
if @decorate_events
event.set("[@metadata][kafka][topic]", record.topic)
event.set("[@metadata][kafka][consumer_group]", @group_id)
event.set("[@metadata][kafka][partition]", record.partition)
event.set("[@metadata][kafka][offset]", record.offset)
event.set("[@metadata][kafka][key]", record.key)
event.set("[@metadata][kafka][timestamp]", record.timestamp)
end
logstash_queue << event
end
end
end
rescue org.apache.kafka.common.errors.WakeupException => e
raise e if !stop?
ensure
consumer.close
end
end
end
def create_consumer(client_id)
#logger.info("create---------consumer------begin")
begin
props = java.util.Properties.new
kafka = org.apache.kafka.clients.consumer.ConsumerConfig
props.put(kafka::AUTO_OFFSET_RESET_CONFIG, auto_offset_reset) unless auto_offset_reset.nil?
props.put(kafka::BOOTSTRAP_SERVERS_CONFIG, bootstrap_servers)
props.put(kafka::CLIENT_ID_CONFIG, client_id)
props.put(kafka::GROUP_ID_CONFIG, group_id)
props.put(kafka::MAX_POLL_RECORDS_CONFIG, max_poll_records) unless max_poll_records.nil?
props.put(kafka::KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer")
props.put(kafka::VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer")
org.apache.kafka.clients.consumer.KafkaConsumer.new(props)
rescue => e
logger.error("Unable to create Kafka consumer from given configuration",
:kafka_error_message => e,
:cause => e.respond_to?(:getCause) ? e.getCause() : nil)
raise e
end
end
end
3.1.1 踩坑问题given1,except 0…
1 一种是jdk 版本的问题 需要用8
2 一种就是代码的问题,参数入参缺少logstash_queue参数的传递
3.2 依赖的设置
Gemfile
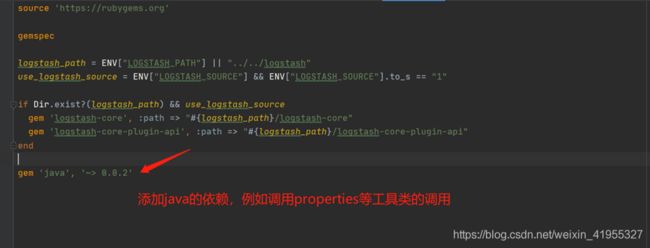
spec

Kafka 的客户端依赖jar,会使用maven拉取jar包。
至此本文仅仅是讲了大概的,一个整体脉络,具体详细,大家可以看给出的官方文档的链接
赠人玫瑰,手有余香,你的关注,我的动力!
更多分享可见: