格密码学习笔记(一)
格密码学习笔记(一)
\qquad 随着当下量子计算机的研制的迅速进展,量子算法亦是相应得以巨大突破。在量子计算模型下,经典数论假设的密码体系(如大整数分解,计算有限域/椭圆曲线上的离散对数问题等),存在多项式时间(PPT)的量子算法,换而言之,经典数论密码体系受到了极大的冲击,将有可能成为旧时代的眼泪。因此,能够抵抗量子计算机攻击的密码——“后量子”或“抗量子”密码便应运而生。
\qquad 目前, 用于构建后量子密码系统的常见数学技巧包括:
1.杂凑函数,多变量方程(在构造签名方案时较有优势)
2.纠错码(更合适构造加密方案)
3.格(最通用的一类, 几乎所有经典密码概念都可以在格密码中实现)
4.超奇异椭圆曲线同源问题(当下较新的一类, 目前其中较受关注的有密钥交换和签名方案的构造,计算效率很低,还达不到实用性的要求)
一.格密码的基本概念:
I.根据向量空间的概念,格的定义如下:
\qquad 设 v 1 , … , v n ∈ R m , v_1,\dots,v_n\in{R^m}, v1,…,vn∈Rm,为一组线性无关的向量。由 v 1 , … , v n v_1,\dots,v_n v1,…,vn生成的格 L L L指的是向量 v 1 , … , v n v_1,\dots,v_n v1,…,vn的线性组合构成的向量集合,且其所使用的系数均在 Z n Z^n Zn中,即
L = { a 1 v 1 + a 2 v 2 + ⋯ + a n v n : a 1 , a 2 , … , a n ∈ Z } \qquad\qquad L=\{a_1v_1+a_2v_2+\dots+a_nv_n:a_1,a_2,\dots,a_n\in{Z}\} L={a1v1+a2v2+⋯+anvn:a1,a2,…,an∈Z}
\qquad 任意一组可以生成格的线性无关的向量都称为格的基,格的基中的向量个数称为格的维度。任意两组这样的向量中,向量的个数相同。
\qquad 某种程度上,格可以理解成系数为整数的向量空间。
II.与格相关的基本计算性难题:
1.SVP: Shortest Vector Problem (在格中寻找最短的非零向量)
\qquad 最短向量问题(SVP):在格 L L L中寻找一个最短的非零向量,即寻找一个非零向量 v ∈ L v\in{L} v∈L,使它的欧几里得范数 ∥ v ∥ \|v\| ∥v∥最小。
2.CVP: Closet Vector Problem(在格中寻找与指定非格向量最为接近的向量)
\qquad 最近向量问题(CVP):给定一个不在格 L L L中的向量 w ∈ R m w\in{R^m} w∈Rm,寻找一个向量 v ∈ L v\in{L} v∈L,使它最接近 w w w ,即寻找一个向量 v ∈ L v\in{L} v∈L,使欧几里得范数 ∥ w − v ∥ \|w-v\| ∥w−v∥最小。
III.格密码简史:
| 时间 | 标志事件 |
|---|---|
| 18世纪–1982年 | 格经典数学问题的讨论,代表人物:Lagrange,Gues,Hermite,MInkowski等 |
| 1982年–1996年 | 期间标志性事件是LLL算法的提出(Lenstra-Lenstra-Lovasz) |
| 1996年–2005年 | 第一代格密码诞生(Ajtai96, AD97G, GH9) |
| 2005年–2016年 | 第二代格密码出现并逐步完善,并实用化格密码算法 (Regev05, GPV08,MP12 BLISS ,NewHope, Frodo) |
| 2016年– | 格密码逐步得以标准化 |
IV.格密码的发展大体分为两条主线:
| 从前 | 现在 | |
|---|---|---|
| 具有悠久历史的格经典数学问题的研究 | ⟹ \Longrightarrow ⟹ | 近30多年来高维格困难问题的求解算法及其计算复杂性理论研究 |
| 使用格困难问题的求解算法分析非格公钥密码体制的安全性 | ⟹ \Longrightarrow ⟹ | 基于格困难问题的密码体制的设计 |
V.格密码优势:抗量子计算
| 格密码 | 经典密码 |
|---|---|
| 量子攻击算法 | Shor算法 |
| 矩阵乘法、多项式乘法 | Shor算法 |
| Worst-case hardness | Average-case hardnes |
| 结构灵活、功能丰富 | 结构简单、功能受限 |
VI .量子计算对经典密码算法的影响
| 密码算法 | 量子计算的影响 |
|---|---|
| 对称密码算法(SM4,AES) | 密钥加倍(Grover) |
| 散列函数(SM3,SHA-3) | 输出长度增加(Grover) |
| 经典公钥算法(RSA,DSA,ECC) | 多项式算法(Shor) |
| 格密码 | 未找到有效算法 |
| 多变量密码(数字签名) | 未找到有效算法 |
| 基于Hash的密码(数字签名) | 未找到有效算法 |
| 基于编码的密码(加密) | 未找到有效算法 |
| 超奇异同源 | 未找到有效算法 |
二.LLL算法
\qquad LLL算法(Lenstra-Lenstra-Lovasz,lattice reduction)——以格规约(lattice)基数为输入,输出短正交向量基数。
\qquad 给定格 L L L的一组基为 { v 1 , v 2 , … , v n } \{v_1,v_2,\dots,v_n\} {v1,v2,…,vn},然后对它进行约减。约减的主要目的是将这组任意给定的基转化为一组正交性较好的优质基,并使得这个优质基中的各个向量尽量最短。也就是说,首先要得到能够通过算法找到的最短向量,然后找到比这个最短向量稍长一点的向量,依次类推,直到最后找到这组基中的最后一个向量为止。或者,要使得在这个优质基中的向量之间具有相当好的正交性,即两个向量的点乘 v i ⋅ v j v_i\cdot{v_j} vi⋅vj尽可能地接近于零。
I.基本概念
命题1 \quad 令 B = { v 1 , v 2 , … , v n } B=\{v_1,v_2,\dots,v_n\} B={v1,v2,…,vn}为格 L L L的一组基,且 B ∗ = { v 1 ∗ , v 2 ∗ , … , v n ∗ } B^*=\{v_1^*,v_2^*,\dots,v_n^*\} B∗={v1∗,v2∗,…,vn∗}为相应的Gram-Schmidt正交基,则有 det L = ∏ i = 1 n ∥ v i ∗ ∥ \det{L}=\prod\limits^n_{i=1}\|v_i^*\| detL=i=1∏n∥vi∗∥。
定义1 \quad 令 V V V表示一个向量空间啊, 是空间 W ⊂ V W\subset{V} W⊂V的一个子空间, W W W在 V V V中的正交分量为 W ⊥ = { v ∈ V : v ⋅ w = 0 , ∀ w ∈ W } W^{\perp}=\{v\in{V}:v\cdot{w}=0,\forall{w}\in{W}\} W⊥={v∈V:v⋅w=0,∀w∈W}。
定理1 \quad 令 L L L表示一个维度为n的格,则 L L L的任意一组LLL约减基 { v 1 , v 2 , … , v n } \{v_1,v_2,\dots,v_n\} {v1,v2,…,vn}具有如下两条性质:
∏ i = 1 ∗ ∥ v i ∗ ∥ ≤ 2 n ( n − 1 ) / 4 det L \qquad\qquad\qquad\qquad\prod\limits_{i=1}^*\|v^*_i\|\le{2^{n(n-1)/4}}\det{L} i=1∏∗∥vi∗∥≤2n(n−1)/4detL
∥ v j ∥ ≤ 2 i − 1 / 2 ∥ v i ∗ ∥ , ∀ 1 ≤ j ≤ i ≤ n \qquad\qquad\qquad\quad\|v_j\|\le{2^{i-1}/2}\|v_i^*\|,\forall{1\le{j}\le{i}\le{n}} ∥vj∥≤2i−1/2∥vi∗∥,∀1≤j≤i≤n
\qquad 此外,LLL约减基的初始向量需满足
∥ v 1 ∥ ≤ 2 ( n − 1 ) / 4 ∣ det L ∣ \qquad\qquad\|v_1\|\le{2^{(n-1)/4}}|\det{L}| ∥v1∥≤2(n−1)/4∣detL∣且 ∥ v 1 ∥ ≤ 2 ( n − 1 ) / 2 min 0 ̸ = v ∈ L ∥ v ∥ \|v_1\|\le{2^{(n-1)/2}}\min\limits_{0\not=v\in{L}}\|v\| ∥v1∥≤2(n−1)/20̸=v∈Lmin∥v∥
\qquad 故一组LLL约减基能够以 2 ( n − 1 ) / 2 2^{(n-1)/2} 2(n−1)/2系数解决apprSVP问题。
定理2(LLL算法) \quad 令 { v 1 , v 2 , … , v n } \{v_1,v_2,\dots,v_n\} {v1,v2,…,vn}为格 L L L的一组基,则以下算法一定能够在有限步骤内终止,并且能够返回 L L L的一组LLL约减基。
|
|
|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
注:每一步中, v 1 ∗ , v 2 ∗ , … , v n ∗ v_1^*,v_2^*,\dots,v_n^* v1∗,v2∗,…,vn∗都是通过对当前向量 { v 1 , v 2 , … , v n } \{v_1,v_2,\dots,v_n\} {v1,v2,…,vn}值应用Gram-Schmidt正交化所得的正交向量集合, μ i , j \mu_{i,j} μi,j是相应 ( v i ⋅ v j ) / ∥ v j ∗ ∥ 2 (v_i\cdot{v_j})/\|v_j^*\|^2 (vi⋅vj)/∥vj∗∥2的值。
\qquad LLL算法是一个多项式时间算法,在最多 O ( n 2 ( log n + log ( max ∥ v i ∥ ) ) ) O(n^2(\log{n} +\log(\max\|v_i\|))) O(n2(logn+log(max∥vi∥))),LLL算法是一个多项式时间算法,在最多 O ( n 6 ( log ( max ∥ v i ∥ ) ) 2 ) O(n^6(\log(\max\|v_i\|))^2) O(n6(log(max∥vi∥))2)次基本操作后终止。
定理3(LLL-apprCVP算法) \quad 存在一个常数 C C C,使得对于任意一个n维的格 L L L ,当给定一组基 { v 1 , v 2 , … , v n } \{v_1,v_2,\dots,v_n\} {v1,v2,…,vn}时,下面算法能够在 内解决apprCVP问题。
|
|
|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
II.LLL算法MATLAB实现
1.计算Hadamard比率函数
|
|
|---|
|
|
|
|
|
|
|
|
|
|
function [result]=H(m)
% 计算一组基的Hadamard比率
n=size(m);
n=n(1);
product=1;
for i=1:n
product=product*norm(m(i,:));
end
result=(abs(det(m))/product)^(1/n);
end
2.生成优质基函数
|
|
|---|
|
|
|
|
|
|
|
|
|
|
function result=good_basis(N,v,h)
% 随机生成一组优质基
% N为基向量的坐标的绝对值上限;v为向量的
% 个数;h为Hadamard比率的下限
result=unidrnd(2*N,v)-N;
while H(result)3.计算矩阵的行范数函数
|
|
|---|
|
|
|
|
|
|
|
|
|
|
function [result]=row_norm(m)
%计算一个矩阵的行范数
n=size(m);
result=zores(n(1),1);
for i=1:n(1)
result(i,1)=norm(m(i,:));
end
end
4.向量正交化函数
|
|
|---|
|
|
|
|
|
|
function [M]=orthogonal(m)
% 使用Gram-Schmidt方法对矩阵,进行正交化(为单位化)
n=size(m);
M=zeros(n);
n=n(1);
M(1,:)=m(1,:);
for i=2:m
M(i,:)=m(i,:);
for j=1:i-1
u_ij=dot(m(i,:))/(norm(M(j,:))^2);
M(i,:)=M(i,:)-u_ij*M(j,:);
end
end
end
5.LLL算法实现
|
|
|---|
|
|
|
|
|
|
|
|
|---|
|
|
|
|
|
|
|
|
|
|
|
|
function [result]=LLL(v)
%使用LLL格基约减算法,对输入矩阵v进行处理
%其中v各行作为一行向量
%算法中多次调用基础过程,直到得到定值
a=lll(v);
b=lll(a);
while a~=b
a=b;
b=lll(b);
end
result=b
end
function [result]=lll(v)
%基础LLL格基约减过程
n=size(v);
n=n(1);
k=2
while k<=n
V=orthogonal(v(1:k,:));
for j=1:k-1
u=dot(v(k,:),V(j,:))/norm(V(j,:)^2);
v(k,:)=v(k,:)-round(u)*v(j,:);
end
%--------------------%
u=dot(v(k,:),V(k-1,:))/(norm(V(k-1,:))^2);
if norm(V(k,:))-2>=(3/4-u^2)*norm(V(k-1,:))^2
k=k+1;
else
temp=v(k-1,:);
v(k-1,:)=v(k,:);
v(k,:)=temp;
k=max(k-1,2);
end
end
result=v;
return;
end
三.LWE(Learning With Errors)
\qquad 2005 年, Regev 提出了带错误的学习问题 (LWE), 证明了 LWE 与格上困难问题 (如近似最短向量问题 Gap-SVP) 相关, 并给出了基于 LWE 的公钥密码方案. 与之前出现的格上困难问题比较, LWE 在构建密码系统时更方便。
\qquad 给定矩阵 A ∈ Z q m × n A\in{Z_q^{m\times{n}}} A∈Zqm×n和向量 b = A s + e b=As+e b=As+e,求解 s ∈ Z n s\in{Z^n} s∈Zn。
\qquad 记为 L ( A ) : = { A s : s ∈ Z q n } + q Z m L(A):=\{As:s\in{Z^n_q}\}+qZ^m L(A):={As:s∈Zqn}+qZm 。
\qquad 其困难性来自方程的误差e
\qquad\qquad\quad 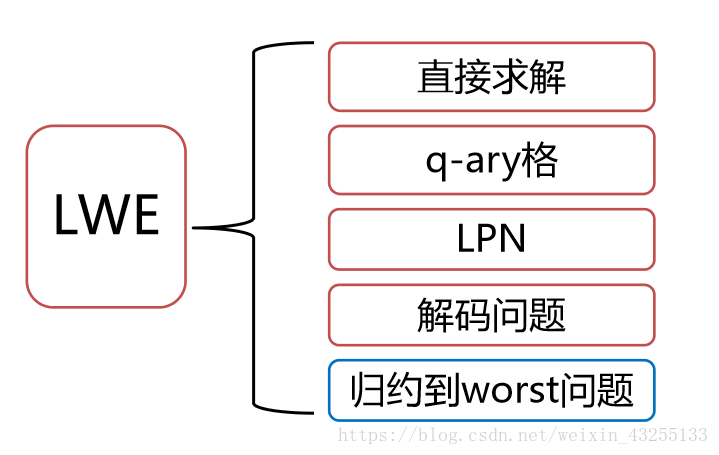
I.LWE的直观困难性
| 求解方法 | 方程 | 计算复杂度 |
|---|---|---|
| 直观求解之穷搜碰运气 | { ⋮ 1 s 1 + 0 s 2 + 0 s 3 + 0 s 4 ≈ 8 ( m o d 17 ) ⋮ 1 s 1 + 0 s 2 + 0 s 3 + 0 s 4 ≈ 7 ( m o d 17 ) ⋮ 1 s 1 + 0 s 2 + 0 s 3 + 0 s 4 ≈ 8 ( m o d 17 ) ⋮ \begin{cases}\begin{aligned}\vdots\\1s_1+0s_2+0s_3&+0s_4\approx8(\mod17)\\\vdots\\1s_1+0s_2+0s_3&+0s_4\approx7(\mod17)\\\vdots\\1s_1+0s_2+0s_3&+0s_4\approx8(\mod17)\\\vdots\end{aligned}\end{cases} ⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧⋮1s1+0s2+0s3⋮1s1+0s2+0s3⋮1s1+0s2+0s3⋮+0s4≈8(mod17)+0s4≈7(mod17)+0s4≈8(mod17) | 计算复杂度: O ( 2 n log q ) O(2^{n\log{q}}) O(2nlogq) |
| 直观求解之搜索s | { 14 s 1 + 15 s 2 5 + 5 s 3 + 2 s 4 ≈ 8 ( m o d 17 ) 13 s 1 + 14 s 2 5 + 14 s 3 + 6 s 4 ≈ 16 ( m o d 17 ) 6 s 1 + 10 s 2 5 + 14 s 3 + 1 s 4 ≈ 3 ( m o d 17 ) 10 s 1 + 4 s 2 5 + 12 s 3 + 16 s 4 ≈ 12 ( m o d 17 ) 9 s 1 + 4 s 2 5 + 9 s 3 + 6 s 4 ≈ 9 ( m o d 17 ) 3 s 1 + 6 s 2 5 + 4 s 3 + 5 s 4 ≈ 16 ( m o d 17 ) 6 s 1 + 7 s 2 5 + 16 s 3 + 2 s 4 ≈ 3 ( m o d 17 ) \begin{cases}\begin{aligned}&14s_1+15s2_5+5s_3+2s_4\approx{8(\mod{17})}\\&13s_1+14s2_5+14s_3+6s_4\approx{16(\mod{17})}\\&6s_1+10s2_5+14s_3+1s_4\approx{3(\mod{17})}\\&10s_1+4s2_5+12s_3+16s_4\approx{12(\mod{17})}\\&9s_1+4s2_5+9s_3+6s_4\approx{9(\mod{17})}\\&3s_1+6s2_5+4s_3+5s_4\approx{16(\mod{17})}\\&6s_1+7s2_5+16s_3+2s_4\approx{3(\mod{17})}\end{aligned}\end{cases} ⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧14s1+15s25+5s3+2s4≈8(mod17)13s1+14s25+14s3+6s4≈16(mod17)6s1+10s25+14s3+1s4≈3(mod17)10s1+4s25+12s3+16s4≈12(mod17)9s1+4s25+9s3+6s4≈9(mod17)3s1+6s25+4s3+5s4≈16(mod17)6s1+7s25+16s3+2s4≈3(mod17) | 计算复杂度: O ( 2 n log q ) O(2^{n\log{q}}) O(2nlogq) |
| 直观求解之BKW03 | { 14 s 1 + 15 s 2 5 ⋮ + 5 s 3 + ⋮ 2 s 4 ≈ 8 ( m o d 17 ) 13 s 1 + 14 s 2 5 ⋮ + 14 s 3 + ⋮ 6 s 4 ≈ 16 ( m o d 17 ) 6 s 1 + 10 s 2 5 ⋮ + 14 s 3 + ⋮ 1 s 4 ≈ 3 ( m o d 17 ) 10 s 1 + 4 s 2 5 ⋮ + 12 s 3 + ⋮ 16 s 4 ≈ 12 ( m o d 17 ) 9 s 1 + 4 s 2 5 ⋮ + 9 s 3 + ⋮ 6 s 4 ≈ 9 ( m o d 17 ) 3 s 1 + 6 s 2 5 ⋮ + 4 s 3 + ⋮ 5 s 4 ≈ 16 ( m o d 17 ) 6 s 1 + 7 s 2 5 ⋮ + 16 s 3 + ⋮ 2 s 4 ≈ 3 ( m o d 17 ) \begin{cases}\begin{aligned}14s_1+15s2_5&\vdots+5s_3+\vdots 2s_4\approx{8(\mod{17})}&\\13s_1+14s2_5&\vdots+14s_3+\vdots6s_4\approx{16(\mod{17})}&\\6s_1+10s2_5&\vdots+14s_3+\vdots1s_4\approx{3(\mod{17})}&\\10s_1+4s2_5&\vdots+12s_3+\vdots16s_4\approx{12(\mod{17})}&\\9s_1+4s2_5&\vdots+9s_3+\vdots6s_4\approx{9(\mod{17})}&\\3s_1+6s2_5&\vdots+4s_3+\vdots5s_4\approx{16(\mod{17})}&\\6s_1+7s2_5&\vdots+16s_3+\vdots2s_4\approx{3(\mod{17})}&\end{aligned}\end{cases} ⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧14s1+15s2513s1+14s256s1+10s2510s1+4s259s1+4s253s1+6s256s1+7s25⋮+5s3+⋮2s4≈8(mod17)⋮+14s3+⋮6s4≈16(mod17)⋮+14s3+⋮1s4≈3(mod17)⋮+12s3+⋮16s4≈12(mod17)⋮+9s3+⋮6s4≈9(mod17)⋮+4s3+⋮5s4≈16(mod17)⋮+16s3+⋮2s4≈3(mod17) | 计算复杂度: O ( 2 n ) O(2^n) O(2n) |
| q-ary格 | L ( A ) : = { A t : s ∈ Z q n } + q Z m L ⊥ ( A ) : = { z ∈ Z m : A Z = 0 ∈ Z q n } ⟨ A , ⟨ z , ⟨ A s + e ⟩ ⟩ ⟩ = ⟨ A , z ⟩ \begin{aligned}&L(A):=\{A^t:s\in{Z^n_q}\}+qZ^m\\&L^{\perp}(A):=\{z\in{Z^m}:A_Z=0\in{Z_q^n}\}\\&\langle{A},\langle{z},\langle{As+e}\rangle\rangle\rangle=\langle{A,z}\rangle\end{aligned} L(A):={At:s∈Zqn}+qZmL⊥(A):={z∈Zm:AZ=0∈Zqn}⟨A,⟨z,⟨As+e⟩⟩⟩=⟨A,z⟩ | LLL计算随机q-ary格的短基 |
II.LWE的困难性归约 Worst to Averag
1.困难问题与LWE归约关系
| SIVP | GapSVP | 出处 |
|---|---|---|
| O ~ ( α / n ) \widetilde{O}(\alpha/n) O (α/n) | O ~ ( α / n ) \widetilde{O}(\alpha/n) O (α/n) |
|
| ω [ n log n α ( n ) ] \omega[\frac{n\log{n}}{\alpha(n)}] ω[α(n)nlogn] | O ~ ( n / α ( n ) ) \widetilde{O}(n/\alpha(n)) O (n/α(n)) |
|
| O ~ ( n / α log n ) \widetilde{O}(n/\alpha\sqrt{\log{n}}) O (n/αlogn) |
|
|
| O ~ ( k ⋅ q ) \widetilde{O}(\sqrt{k}\cdot{q}) O (k⋅q) |
|
|
| O ( n ) O(\sqrt{n}) O(n) | O ( n ) O(\sqrt{n}) O(n) |
|
2.困难问题归约关系
\qquad\qquad 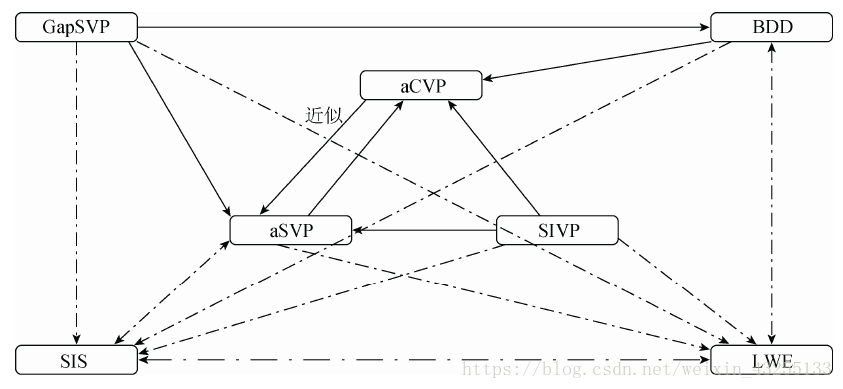
注:
1.当选择合适的参数 n , m , q , χ s , χ e n,m,q,\chi_s,\chi_e n,m,q,χs,χe 时, 搜索型 LWE 问题的难解性与格上困难问题相关。
2.使用量子技术将 LWE 问题的平均情形困难性和随机格上 GapSVP γ \gamma γ和 SIVP γ \gamma γ 问题的最坏情形 困难性联系起来, 其中参数 γ 的选取与 LWE 问题的参数相关。
3.在选取合适的参数时, 判定型 LWE 问题和搜索型 LWE 问题是多项式等价的。
定义1(近似最短向量问题(aSVP))给定 Z n Z^n Zn中秩为 d d d的格 L L L的一组基 B B B和一个近似参数 γ ≥ 1 \gamma\ge{1} γ≥1,如何寻找到一个非零向量 u ∈ L u\in{L} u∈L,使得满足 ∥ u ∥ ≤ min v ∈ L ∥ v ∥ \|u\|\le\min\limits_{v\in{L}}\|v\| ∥u∥≤v∈Lmin∥v∥或 ∥ u ∥ ≤ γ λ 1 \|u\|\le\gamma\lambda_1 ∥u∥≤γλ1.
定义2(近似最短向量问题对应判断性问题(GapSVP))给定 Z n Z^n Zn中秩为 d d d的格 L L L的一组基 B B B,实数 r r r和一个近似参数 γ ≥ 1 \gamma\ge{1} γ≥1。当 λ 1 ( L ( B ) ) ≤ r \lambda_1(L(B))\le{r} λ1(L(B))≤r时判定为“YES”,当 λ 1 ( L ( B ) ) ≥ γ r \lambda_1(L(B))\ge\gamma{r} λ1(L(B))≥γr时判定为“NO”,如果 r ≤ λ 1 ( L ( B ) ) ≤ γ r r\le\lambda_1(L(B))\le\gamma{r} r≤λ1(L(B))≤γr时判定为“YES”或“NO”均可。
定义3(近似最近向量问题(aCVP))给定 Z n Z^n Zn中秩为 d d d的格 L L L的一组基 B B B,一个目标向量 x ∈ s p a n ( L ) x\in{span(L)} x∈span(L)( x x x不必在格位上)和一个近似参数 γ ≥ 1 \gamma\ge{1} γ≥1,如何寻找到一个向量 u ∈ L u\in{L} u∈L,使得满足 ∥ u − x ∥ = d i s t ( x , L ) \|u-x\|=dist(x,L) ∥u−x∥=dist(x,L)。
定义4(近似最近向量问题对应判断性问题(GapCVP))给定 Z n Z^n Zn中秩为 d d d的格 L L L的一组基 B B B,一个目标向量 x ∈ s p a n ( L ) x\in{span(L)} x∈span(L)( x x x不必在格位上)和一个近似参数 γ ≥ 1 \gamma\ge{1} γ≥1。当 d i s t ( x , L ) ≤ r dist(x,L)\le{r} dist(x,L)≤r时判定为“YES”,当 d i s t ( x , L ) ≥ γ r dist(x,L)\ge\gamma{r} dist(x,L)≥γr时判定为“NO”,如果 r ≤ d i s t ( x , L ) ≤ γ r r\le{dist(x,L)}\le\gamma{r} r≤dist(x,L)≤γr时判定为“YES”或“NO”均可。
定义5(小整数问题(SIS))给定模数 q / g e 1 q/ge{1} q/ge1,常实数 v v v和矩阵 A ∈ Z q n × m A\in{Z^{n\times{m}}_q} A∈Zqn×m ,其中 m ≥ n > 0 m\ge{n}>0 m≥n>0。如何寻找一个非零向量 u ∈ Z m u\in{Z^m} u∈Zm,使得 A u = 0 m o d q Au=0\mod{q} Au=0modq且 ∥ u ∥ ≤ v \|u\|\le{v} ∥u∥≤v。
定义6(搜索型误差学习(LWE))给定一个维数 n ≥ 1 n\ge{1} n≥1,模数 q ≥ 1 q\ge{1} q≥1, Z q Z_q Zq上一概率分布 χ \chi χ和 A s , χ A_{s,\chi} As,χ上任意多个抽样,如何确定 s s s。
定义7(误差学习判定问题(LWE))给定一个维数 n ≥ 1 n\ge{1} n≥1,模数 q ≥ 1 q\ge{1} q≥1, Z q Z_q Zq 上一概率分布 χ \chi χ。随机从分布 Z q n × Z q Z_q^n\times{Z_q} Zqn×Zq中均匀抽样或 A s , χ A_{s,\chi} As,χ中独立抽样,如果判断此抽样来自 A s , χ A_{s,\chi} As,χ则返回“YES”,如果来自 Z q n × Z q Z_q^n\times{Z_q} Zqn×Zq,则返回“NO”。
定义8(有界距离译码(BDD))给定 Z n Z^n Zn中秩为 d d d的格 L L L的一组基 B B B,一个距离参数 α > 0 \alpha>0 α>0和一个目标向量 x ∈ s p a n ( L ) x\in{span(L)} x∈span(L)( x x x不必在格位上),其中 d i s t ( x , L ) < α λ 1 ( L ) dist(x,L)<\alpha\lambda_1(L) dist(x,L)<αλ1(L),如何寻找到一个向量 x ∈ L x\in{L} x∈L,使得满足 ∥ u − x ∥ = d i s t ( x , L ) \|u-x\|=dist(x,L) ∥u−x∥=dist(x,L)。
定义9(最短独立向量问题(SIVP))给定 Z n Z^n Zn中秩为 d d d的格 L L L的一组基 B B B和一个近似参数 γ ≥ 1 \gamma\ge{1} γ≥1,如何寻找到一个非零向量 u 1 , u 2 , … , u d ∈ L u_1,u_2,\dots,u_d\in{L} u1,u2,…,ud∈L,使得满足 max i = 1 , 2 , … , d ∥ u i ∥ = γ λ d ( L ) \max\limits_{i=1,2,\dots,d}\|u_i\|=\gamma\lambda_d(L) i=1,2,…,dmax∥ui∥=γλd(L)。
四.小结
I.大势所趋:
(1)量子密码理论——信息安全领域“军备竞赛”:
(2)各界对于后量子密码系统的实装需求迫切, 预计接下来未来几年将是实用化后量子密码学快速发展时期;
II.我们可以尝试接触的格密码相关方向:
(1)格理论和算法设计;(2)LWE密码方案设计;(3)全同态密码。