docker hadoop集群配置
环境
1、操作系统: CentOS 64位
网路设置
| hostname | ip |
| cluster-master | 172.18.0.2 |
| cluster-slave1 | 172.18.0.3 |
| cluster-slave2 | 172.18.0.4 |
| cluster-slave3 | 172.18.0.5 |
一、docker 安装
二、拉去centos最新版本镜像
docker pull centos  2.1 按照集群的架构,创建容器时需要设置固定IP,所以先要在docker使用如下命令创建固定IP的子网
2.1 按照集群的架构,创建容器时需要设置固定IP,所以先要在docker使用如下命令创建固定IP的子网
docker network create --subnet=172.18.0.0/16 netgroup![]()
docker的子网创建完成之后就可以创建固定IP的容器了
#cluster-master
#-p 设置docker映射到容器的端口 后续查看web管理页面使用
docker run -d --privileged -ti -v /sys/fs/cgroup:/sys/fs/cgroup --name cluster-master -h cluster-master -p 18088:18088 -p 9870:9870 --net netgroup --ip 172.18.0.2 daocloud.io/library/centos /usr/sbin/init
#cluster-slaves
docker run -d --privileged -ti -v /sys/fs/cgroup:/sys/fs/cgroup --name cluster-slave1 -h cluster-slave1 --net netgroup --ip 172.18.0.3 daocloud.io/library/centos /usr/sbin/init
docker run -d --privileged -ti -v /sys/fs/cgroup:/sys/fs/cgroup --name cluster-slave2 -h cluster-slave2 --net netgroup --ip 172.18.0.4 daocloud.io/library/centos /usr/sbin/init
docker run -d --privileged -ti -v /sys/fs/cgroup:/sys/fs/cgroup --name cluster-slave3 -h cluster-slave3 --net netgroup --ip 172.18.0.5 daocloud.io/library/centos /usr/sbin/init
启动控制台并进入docker容器中:
docker exec -it cluster-master /bin/bash2.2安装OpenSSH免密登录
2.2.1、cluster-master安装:
#cluster-master需要修改配置文件--特殊
#安装openssh
[root@cluster-master /]# yum -y install openssh openssh-server openssh-clients
[root@cluster-master /]# systemctl start sshd
####ssh自动接受新的公钥
####master设置ssh登录自动添加kown_hosts
[root@cluster-master /]# vi /etc/ssh/ssh_config
#将原来的StrictHostKeyChecking ask
#设置StrictHostKeyChecking为no
#保存
[root@cluster-master /]# systemctl restart sshd
2.2.2、分别对slaves安装OpenSSH
#进入容器
docker exec -it cluster-slave1 /bin/bash
#安装openssh
[root@cluster-slave1 /]#yum -y install openssh openssh-server openssh-clients
[root@cluster-slave1 /]# systemctl start sshd2.2.3、cluster-master公钥分发
在master机上执行
ssh-keygen -t rsa
并一路回车,完成之后会生成~/.ssh目录,目录下有id_rsa(私钥文件)和id_rsa.pub(公钥文件),再将id_rsa.pub重定向到文件authorized_keys
ssh-keygen -t rsa
#碰见输入密码地方一路回车即可
[root@cluster-master /]# cat ~/.ssh/id_rsa.pub > ~/.ssh/authorized_keys文件生成之后用scp将公钥文件分发到集群slave主机
[root@cluster-master /]# ssh root@cluster-slave1 'mkdir ~/.ssh'
[root@cluster-master /]# scp ~/.ssh/authorized_keys root@cluster-slave1:~/.ssh
[root@cluster-master /]# ssh root@cluster-slave2 'mkdir ~/.ssh'
[root@cluster-master /]# scp ~/.ssh/authorized_keys root@cluster-slave2:~/.ssh
[root@cluster-master /]# ssh root@cluster-slave3 'mkdir ~/.ssh'
[root@cluster-master /]# scp ~/.ssh/authorized_keys root@cluster-slave3:~/.ssh如果出现输入密码直接可以去对应slave创建文件,并从master拷贝。
分发完成之后测试(ssh root@cluster-slave1)是否已经可以免输入密码登录
Ansible安装
[root@cluster-master /]# yum -y install epel-release
[root@cluster-master /]# yum -y install ansible
#这样的话ansible会被安装到/etc/ansible目录下
此时我们再去编辑ansible的hosts文件
vi /etc/ansible/hosts
软件环境配置:
下载jdk,hadoop3 到/opt目录下,解压安装包,并创建链接文件
- 安装jdk1.8, 安装方式,yum search java* 查询java版本,并通过yum install java1.8直接安装
- 下载hadoop, 下载链接:https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz
wget https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gztar -xzvf hadoop-3.3.0.tar.gz
ln -s hadoop-3.3.0 hadoop配置java和hadoop环境变量
编辑 ~/.bashrc文件
# hadoop
export HADOOP_HOME=/opt/hadoop-3.3.0
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
#java
export JAVA_HOME=/opt/jdk8
export PATH=$HADOOP_HOME/bin:$PATH执行命令使。bashrc文件生效
source .bashrc配置hadoop运行所需配置文件
#进入hadoop目录进行配置
cd $HADOOP_HOME/etc/hadoop/1、修改core-site.xml
hadoop.tmp.dir
/home/hadoop/tmp
A base for other temporary directories.
fs.default.name
hdfs://cluster-master:9000
fs.trash.interval
4320
2、修改hdfs-site.xml
dfs.namenode.name.dir
/home/hadoop/tmp/dfs/name
dfs.datanode.data.dir
/home/hadoop/data
dfs.replication
3
dfs.webhdfs.enabled
true
dfs.permissions.superusergroup
staff
dfs.permissions.enabled
false
3、修改mapred-site.xml
mapreduce.framework.name
yarn
mapred.job.tracker
cluster-master:9001
mapreduce.jobtracker.http.address
cluster-master:50030
mapreduce.jobhisotry.address
cluster-master:10020
mapreduce.jobhistory.webapp.address
cluster-master:19888
mapreduce.jobhistory.done-dir
/jobhistory/done
mapreduce.intermediate-done-dir
/jobhisotry/done_intermediate
mapreduce.job.ubertask.enable
true
4、yarn-site.xml
yarn.resourcemanager.hostname
cluster-master
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.address
cluster-master:18040
yarn.resourcemanager.scheduler.address
cluster-master:18030
yarn.resourcemanager.resource-tracker.address
cluster-master:18025
yarn.resourcemanager.admin.address
cluster-master:18141
yarn.resourcemanager.webapp.address
cluster-master:18088
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
86400
yarn.log-aggregation.retain-check-interval-seconds
86400
yarn.nodemanager.remote-app-log-dir
/tmp/logs
yarn.nodemanager.remote-app-log-dir-suffix
logs
打包hadoop 向slaves分发
tar -cvf hadoop-dis.tar hadoop hadoop-3.3.0使用ansible-playbook分发.bashrc和hadoop-dis.tar至slave主机
---
- hosts: cluster
tasks:
- name: copy .bashrc to slaves
copy: src=~/.bashrc dest=~/
notify:
- exec source
- name: copy hadoop-dis.tar to slaves
unarchive: src=/opt/hadoop-dis.tar dest=/opt
handlers:
- name: exec source
shell: source ~/.bashrc将以上yaml保存为playbook01.yml,并执行 参考文档
ansible-playbook playbook01.ymlhadoop-dis.tar会自动解压到slave主机的/opt目录下
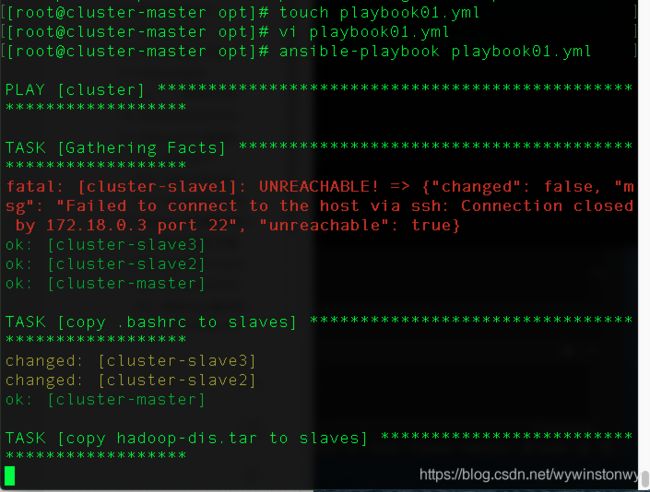
Hadoop 启动
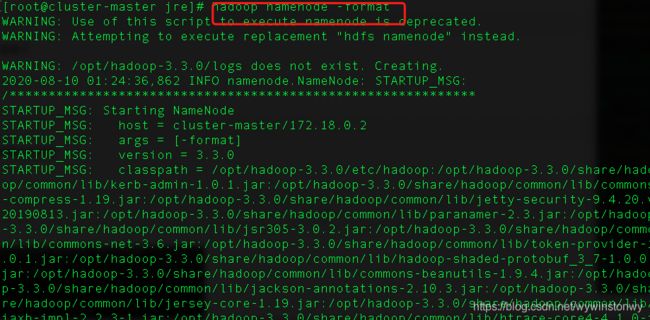
格式化namenode
hadoop namenode -format如果看到storage format success等字样,即可格式化成功
再次启动集群服务:
start-all.sh如果start-all.sh 出现报错:ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
参考:https://www.cnblogs.com/Mr-nie/p/11133416.html

验证服务
访问:
http://host:18088
http://host:9870

hadoop 查看文件夹
./hadoop fs -ls /
创建文件夹
./hadoop fs -mkdir /test
上传文件:
./hadoop fs -put /Users/wangyun/Desktop/lala.txt /test/
查看文件
./hadoop fs -ls /test
读取文件
./hadoop fs -text /test/lala.txt
