Java集合框架——Collection
集合类
- 为什么出现集合类?
面向对象语言对事物的体现都是以对象的形式,所以为了方便对多个对象的操作,就对对象进行存储,集合就是存储对象最常用的一种方式。 - 数组和集合类同是容器,有何不同?
数组虽然也可以存储对象,但长度是固定的;集合长度是可变的。数组中可以存储基本数据类型,集合只能存储对象。 - 集合类的特点
集合只用于存储对象,集合长度是可变的,集合可以存储不同类型的对象。
集合框架的构成及分类
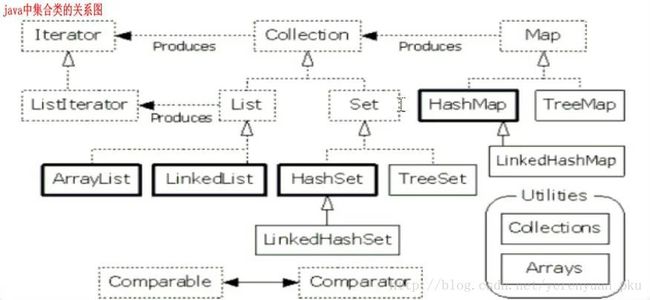
为什么会出现这么多的容器呢?
答:因为每一个容器对数据的存储方式都有不同。这个存储方式称之为:数据结构。
集合框架中的常用接口
Collection接口
集合中的最大接口——Collection,可以通过查看JDK帮助文档,了解Collection接口中的最共性的方法。现在我们就来练习这些方法,不过在做之前,须创建一个集合容器,我们使用Collection接口的子类——ArrayList。
Collection coll = new ArrayList();添加元素
coll.add("abc1"); coll.add("abc2"); coll.add("abc3");注意:
- add方法的参数类型是Object,以便于接受任意类型。
- 集合中存储的都是对象的引用(地址)。
删除元素
coll.remove("abc2");注意删除元素会改变集合的长度。
清空集合
coll.clear();判断元素
System.out.println("abc1是否存在:"+coll.contains("abc1")); System.out.println("集合是否为空?"+coll.isEmpty());
下面我们将演示Collection接口中带all的方法,不过在做之前,须创建两个集合容器,如下:
Collection c1 = new ArrayList();
Collection c2 = new ArrayList();然后分别往这两个容器中添加元素:
c1.add("abc1");
c1.add("abc2");
c1.add("abc3");
c1.add("abc4");
c2.add("abc2");
c2.add("abc3");
c2.add("abc5");往c1中添加c2
c1.addAll(c2);判断c1中是否包含c2中的所有元素
boolean b = c1.containsAll(c2); System.out.println("b = " + b);从c1中删除c2,所说的意思:将c1中和c2相同的元素从c1中删除。即移除交集
c1.removeAll(c2);将c1和c2不同的元素从c1中删除,保留c1中和c2相同的元素。即取交集
c1.retainAll(c2);
迭代器(Iterator)
什么是迭代器呢?
答:迭代是取出元素中的一种方式,用更通俗一点的话来说就是:
有没有啊?有!取一个。还有没有啊?有!取一个。还有没有啊?没有。算了。
所以,迭代器其实就是集合的取出元素的方式,或者也可说成是迭代器是取出Collection集合中元素的公共方式。
Iterator的初步解释:就是把取出方式定义在了集合的内部,这样取出方式就可以直接访问集合内部的元素,那么取出方式就被定义成了内部类。而每一个容器的数据结构不同,所以取出的动作细节也不一样,但是都有共性内容——判断和取出,那么可以将这些共性抽取,那么这些内部类都符合一个规则,该规则就是Iterator。
如何获取集合的取出对象呢?
答:通过一个对外提供的方法:Iterator iterator()——获取集合中元素上迭代功能的迭代器对象(迭代器:具备着迭代功能的对象,而迭代器对象不需要new,直接通过iterator()方法获取即可)。
因为Collection中有iterator方法,所以每一个子类集合对象都具备迭代器。
Iterator接口中有如下2个重要方法:
- boolean hasNext():看看还有没有被获取到的元素。如果没有就返回false,如果有就返回true。
- E next():获取当前光标下的元素,然后再将光标往下移一行。光标初始值是0,而且每调用一次next()方法,光标都会往下移一行。
例,
public static void sop(Object obj) {
System.out.println(obj);
}
public static void method_get() {
ArrayList al = new ArrayList();
al.add("java01");
al.add("java02");
al.add("java03");
al.add("java04");
/*
Iterator it = al.iterator(); // 获取迭代器,用于取出集合中的元素
while(it.hasNext()) {
sop(it.next());
}
*/
// 开发时,这样写
for (Iterator it = al.iterator(); it.hasNext(); ) {
sop(it.next());
}
}List(列表)
Collection接口有两个子接口:List(列表),Set(集)。这一小节我们着重学习List(列表)接口。
查阅API,查看List的介绍,我们可以发现以下这些话语:
有序的collection(也称为序列)。此接口的用户可以对列表中每个元素的插入位置进行精确地控制。用户可以根据元素的整数索引(在列表中的位置)访问元素,并搜索列表中的元素。
与set不同,列表通常允许重复的元素。
看完API,我们总结一下:
List接口:
- 它是一个元素存取有序的集合。注意:有序指的是存入的顺序和取出的顺序一致。例如,存元素的顺序是11、22、33,那么集合中元素的存储就是按照11、22、33的顺序完成的。
- 它是一个带有索引的集合。通过索引就可以精确的操作集合中的元素(与数组的索引是一个道理)。
- 集合中可以有重复的元素。通过元素的equals方法,来比较是否为重复的元素。
我们已学完Collection接口的大部分方法,List接口中同样有这些方法,所以就不必重复了。现在我们将重点放在List接口中的特有方法上,它的特有方法都是围绕索引定义的。
List接口支持增删改查:
- 增:
add(index, element);addAll(index, Collection);
- 删:
remove(index);
- 改:
set(index, element);
- 查:
element get(index);subList(from, to);listIterator();int indexOf(element);
现在我们演示List接口中的特有方法。
添加元素
List al = new ArrayList(); // 添加元素 al.add("java01"); al.add("java02"); al.add("java03");在指定位置添加元素
al.add(1, "java09");删除指定位置的元素
al.remove(2);修改元素
al.set(2, "java007");通过角标获取元素
System.out.println("get(1):"+al.get(1));返回列表中第一次出现的指定元素的索引
System.out.println(al.indexOf("java03"));通过角标获取所有元素(List集合特有的取出方式)
for (int x = 0; x < al.size(); x++) { System.out.println("al("+x+")="+al.get(x)); }通过迭代器获取所有元素
Iterator it = al.iterator(); while(it.hasNext()) { System.out.println("next:"+it.next()); }返回列表中指定的部分视图(什么是View???)
List sub = al.subList(1, 3); System.out.println("sub="+sub);
Iterator的并发修改异常
现在我们来思考这样一个问题:在迭代过程中,准备添加或者删除元素。例如,在List集合迭代元素中,对元素进行判断,一旦条件满足就添加一个新元素。代码如下:
public class ListIteratorDemo {
public static void main(String[] args) {
List list = new ArrayList();
list.add("abc1");
list.add("abc2");
list.add("abc3");
list.add("abc4");
// 在遍历的过程中,如果遍历到abc2,添加一个元素haha
for (Iterator it = list.iterator(); it.hasNext();) {
Object obj = it.next();
if (obj.equals("abc2")) {
list.add("haha"); // 出现java.util.ConcurrentModificationException(并发修改异常)
}
}
}
}运行上述代码发生了异常——java.util.ConcurrentModificationException[并发修改异常],这是什么原因呢?
原因:在使用迭代器或者增强for循环遍历集合的时候,再调用集合的方法修改集合的长度(添加和删除 ),就会发生并发修改异常。也可以这样说:在迭代过程中,使用了集合的方法对元素进行操作,会导致迭代器并不知道集合中的变化,容易引发数据的不确定性。注意:并发修改异常是由next()方法抛出的。
虽然我们知道其原因了,但是要想知道其更深层次的原因,就得看源码了,跟着我一起去看看源码吧!
ArrayList集合中有一个成员变量modCount(该成员变量在其父接口AbstractList中),它用来记录集合长度修改的次数,每次修改集合的长度,这个变量就会增长。
![]()
迭代器有一个成员变量expectedModCount,它是预期被修改的值,它的初始值是被修改的值。
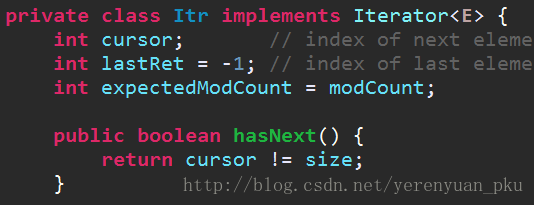
迭代器的next()方法源码截图:
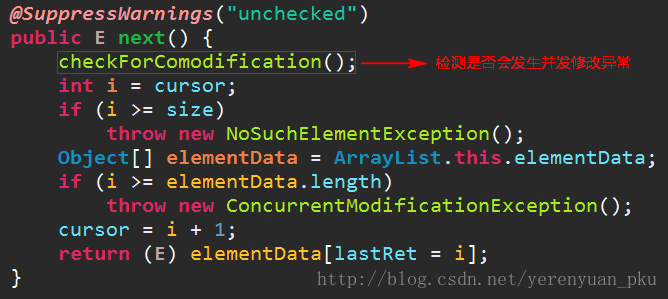
点击进入checkForComodification()该方法里面去,查看其源码。

该方法比较预期修改的次数和修改的次数是不是相等,如果不相等,就抛出并发修改异常。
小结:在迭代时,不可以通过集合对象的方法操作集合中的元素,因为会发生并发修改异常(ConcurrentModificationException)。
通过查阅API,发现迭代器还有另一个方法:remove(),我们可以试着用一下:
Iterator it = list.iterator();
while(it.hasNext()) {
Object obj = it.next();
if(obj.equals("abc2"))
it.remove(); // 将abc2的引用从集合中删除了,但abc2的引用还被obj使用
System.out.println("obj="+obj); // 注意:虽然移除掉了"abc2",但还能输出
}所以,在迭代时,只能用迭代器的方法操作元素,可是Iterator的方法是有限的,只能对元素进行判断,取出,删除的操作,如果想要其他的操作如添加,修改等,就需要使用其子接口listIterator——List集合特有的迭代器(listIterator)。该接口只能通过List集合的listIterator()获取。
// 使用list集合的特有的迭代器——ListIterator,可以通过List集合的方法listIterator()获取该迭代器对象。
// ListIterator可实现在迭代过程中的增删改查。
for (ListIterator it = list.listIterator(); it.hasNext();) {
Object obj = it.next();
if (obj.equals("abc2")) {
it.add("haha");
}
}
System.out.println(list);List集合存储数据的结构
List接口下有很多个集合,它们存储元素所采用的结构方式是不同的,这样就导致了这些集合有它们各自的特点,供给我们在不同的环境下进行使用。数据存储的常用结构有:堆栈、队列、数组、链表。我们分别来了解一下:
- 堆栈,采用该结构的集合,对元素的存取有如下的特点:
- 先进后出(即先存进去的元素,要在它前面的元素依次取出后,才能取出该元素) 。例如子弹压进弹夹,先压进去的子弹在下面,后压进去的子弹在上面,当开枪时,先弹出上面的子弹,然后才能弹出下面的子弹。
- 栈的入口、出口都是栈的顶端位置。
- 压栈:就是存元素。即把元素存储到栈的顶端位置,栈中已有元素依次向栈底方向移动一个位置。
- 弹栈:就是取元素。即把栈的顶端位置元素取出,栈中已有元素依次向栈顶方向移动一个位置。
- 队列,采用该结构的集合,对元素的存取有如下的特点:
- 先进先出(即后存进去的元素,要在它前面的元素依次取出后,才能取出该元素)。例如,安检时,排成一列,每个人依次检查,只有前面的人全部检查完毕后,才能排到当前的人进行检查。
- 队列的入口、出口各占一侧。
- 数组,采用该结构的集合,对元素的存取有如下的特点:
- 查找元素快:通过索引可以快速访问指定位置的元素。
- 增删元素慢:
- 指定索引位置增加元素:需要创建一个新数组,将指定新元素存储在指定索引位置,再把原数组元素根据索引,复制到新数组对应索引的位置上。
- 指定索引位置删除元素:需要创建一个新数组,把原数组元素根据索引,复制到新数组对应索引的位置,原数组中指定索引位置元素不复制到新数组中。
- 链表,采用该结构的集合,对元素的存取有如下的特点:
- 多个节点(它是由两部分组成,数据域[存储的数值]+指针域[存储的地址])之间,通过地址进行连接。例如,多个人手拉手,每个人使用自己的右手拉住下个人的左手,依次类推,这样多个人就连在一起了。
- 查找元素慢:想查找某个元素,需要通过连接的节点,依次向后查找指定元素。
- 增删元素快:
- 增加元素:只需要修改连接下个元素的地址即可。
- 删除元素:只需要修改连接下个元素的地址即可。
List集合的具体子类介绍
List集合的具体子类还蛮有几个,子类之所以区分,就是因为其内部的数据结构(存储数据的方式)不同。
- List
- ArrayList:底层的数据结构使用的是数组结构。特点:查询速度很快,但是增删稍慢。线程不同步,并且替换了Vector。
- LinkedList:底层使用的是链表数据结构。特点:增删速度很快,查询稍慢,并且是线程不同步的。
- Vector:底层是数组数据结构,数组是可变长度的(不断的new新数组并将原数组元素复制到新数组中)。特点:线程同步,增删和查询速度都慢!并且被ArrayList替代了。
ArrayList
ArrayList底层使用的是数组结构,所以它可以存储重复的元素,现在我们有这样一个需求:去除ArrayList集合中的重复元素。例子如下:
例1,定义功能,请去除ArrayList集合中的重复元素(集合中元素是字符串),要求编写出singleElement()方法的完整代码。
public class ArrayListTest2 {
public static void main(String[] args) {
/*
* 练习:定义功能,请除去ArrayList集合中的重复元素
*/
List list = new ArrayList();
list.add("abc1");
list.add("abc4");
list.add("abc2");
list.add("abc1");
list.add("abc4");
list.add("abc4");
list.add("abc2");
list.add("abc1");
list.add("abc4");
list.add("abc2");
System.out.println(list);
singleElement(list);
System.out.println(list);
}
}仔细思考该题,可发现有2种解决方式。先来看第一种解决方式:
/**
* 定义功能,去除重复元素
*/
public static void singleElement(List list) {
for (int x = 0; x < list.size() - 1; x++) {
Object obj_x = list.get(x);
for (int y = x + 1; y < list.size(); y++) {
if (obj_x.equals(list.get(y))) {
list.remove(y); // 集合的长度改变了
y--;
}
}
}
}这种解决方式其实有点类似于选择排序,不是吗?
然后我们来看去除重复元素的第二种解决方式。
思路:
- 由于最后唯一性的元素也很多,所以可以先定义一个容器用于存储这些唯一性的元素。
- 对原有的容器进行元素的获取,并到临时容器中去判断是否存在,容器本身就有这个功能(判断元素是否存在)。
- 存在就不存储,不存在就存储。
遍历完原容器,临时容器中存储的就是唯一性的元素。
public static void singleElement(List list) { // 1,定义一个临时容器 List temp = new ArrayList(); // 2,遍历原容器 for (Iterator it = list.iterator(); it.hasNext();) { Object obj = (Object) it.next(); // 3,在临时容器中判断遍历到的元素是否存在 if (!temp.contains(obj)) { // 4,如果不存在,就存储到临时容器中 temp.add(obj); } } // 5,将原容器清空 list.clear(); // 6,将临时容器中的元素存储到原容器中 list.addAll(temp); }
例2,去除ArrayList集合中重复的自定义元素。将自定义对象作为元素存到ArrayList集合中,并去除重复元素。比如:存人对象。同姓名同年龄,视为同一个人,为重复元素。
思路:
- 对Person类进行描述,将数据封装到人对象中。
- 定义容器对象,将多个Person对象存储到集合中。
- 去除同姓名同年龄的Person对象(重复元素)。
取出集合中的Person对象
public class Person { private String name; private int age; public Person() { super(); } public Person(String name, int age) { super(); this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } /** * 建立Person类自己的判断对象是否相同的依据,必须覆盖Object类中的equals方法 */ public boolean equals(Object obj) { // System.out.println(this + "...." + obj); // 为了提高效率,如果比较的对象是同一个,直接返回true // 如果把同一个对象存了多次,没有必要再重新判断姓名和年龄,直接判断地址就完了 if (this == obj) return true; if (!(obj instanceof Person)) { throw new ClassCastException("类型错误"); } Person p = (Person) obj; return this.name.equals(p.name) && this.age == p.age; } @Override public String toString() { return "Person [name=" + name + ", age=" + age + "]"; } }注意:在Person类中必须覆盖Object类中的equals方法,不久我们就会看到集合的contains()方法底层调用的就是equals()方法。
public class ArrayListTest { public static void main(String[] args) { // 1,创建ArrayList集合对象 List list = new ArrayList(); // 2,添加Person类型的对象 Person p1 = new Person("lisi1", 21); Person p2 = new Person("lisi2", 22); list.add(p1); // add(Object obj) list.add(p1); // add(Object obj) list.add(p1); // add(Object obj) 存储了一个地址相同的对象 list.add(p2); list.add(new Person("lisi3", 23)); list.add(new Person("lisi1", 21)); list.add(new Person("lisi2", 22)); System.out.println(list); singleElement(list); // 去除重复元素 System.out.println(list); } public static void singleElement(List list) { // 1,定义一个临时容器 List temp = new ArrayList(); // 2,遍历原容器 for (Iterator it = list.iterator(); it.hasNext();) { Object obj = (Object) it.next(); // 3,在临时容器中判断遍历到的元素是否存在 if (!temp.contains(obj)) { // 4,如果不存在,就存储到临时容器中 temp.add(obj); } } // 5,将原容器清空 list.clear(); // 6,将临时容器中的元素存储到原容器中 list.addAll(temp); } }通过以上示例,说明contains()底层用的是equals()。
ArrayList去除重复元素的示意图:
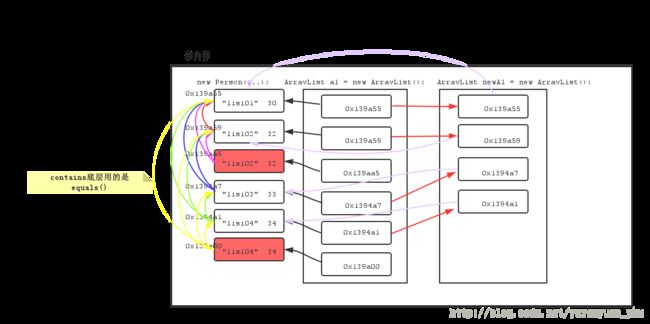
再来看以下代码:public class ArrayListTest2 { public static void sop(Object obj) { System.out.println(obj); } public static void main(String[] args) { ArrayList al = new ArrayList(); al.add(new Person("lisi01", 30)); // add(Object obj); Object obj = new Person("lisi01", 30); al.add(new Person("lisi02", 32)); al.add(new Person("lisi04", 35)); al.add(new Person("lisi03", 33)); sop("remove 03:"+al.remove(new Person("lisi03", 33))); // remove底层用的也是equals() Iterator it = al.iterator(); while(it.hasNext()) { Person p = (Person)it.next(); sop(p.getName()+"::"+p.getAge()); } } }通过以上示例,说明remove()底层用的也是equals()。
结论:List集合判断元素是否相同,依据的是元素的equals方法。
LinkedList
实际开发中对一个集合元素的添加与删除经常涉及到首尾操作,而LinkedList提供了大量首尾操作的方法,如下:
addFirst();
addLast();getFirst();
getLast();
获取元素,但不删除元素。如果集合中没有元素,会出现NoSuchElementException(没有此元素异常)异常。removeFirst();
removeLast();
获取元素,但是元素被删除。如果集合中没有元素,会出现NoSuchElementException(没有此元素异常)异常。
在JDK1.6出现了替代方法:
addFirst();→offerFirst();
addLast();→offerLast();getFirst();→peekFirst();
getLast();→peekLast();
获取元素,但不删除元素。如果集合中没有元素,会返回null。removeFirst();→pollFirst();
removeLast();→pollLast();
获取元素,但是元素被删除。如果集合中没有元素,会返回null。
现在,我们来演示LinkedList的xxxFirst()和xxxLast()方法。
创建一个链表对象
LinkedList link = new LinkedList();添加元素
link.addFirst("abc1"); link.addFirst("abc2"); link.addFirst("abc3");获取元素
System.out.println(link.getFirst()); System.out.println(link.getFirst());删除元素
System.out.println(link.removeFirst()); System.out.println(link.removeFirst());取出link中所有元素
while (!link.isEmpty()) { System.out.println(link.removeLast()); }
Set(集)
Set集合不允许存储重复元素,而且不保证元素是有序的(存入和取出的顺序有可能一致[有序],也有可能不一致[无序])。
通过查看JDK文档,发现Set集合的功能和Collection的是一致的,所以Set集合取出的方法只要一个,那就是迭代器。
Set接口中常用的类——HashSet
查阅HashSet集合的API介绍,可发现:
此类实现Set接口,由哈希表(实际上是一个HashMap实例)支持。它不保证set的迭代顺序,特别是它不保证该顺序恒久不变。此类允许使用null元素。
通过上面的这句话,我们可以总结出:
- HashSet集合采用哈希表结构存储数据,保证元素唯一性的方式依赖于hashCode()与equals()方法(后面会介绍到)。
- HashSet集合不能保证元素的迭代顺序与元素存储顺序相同。
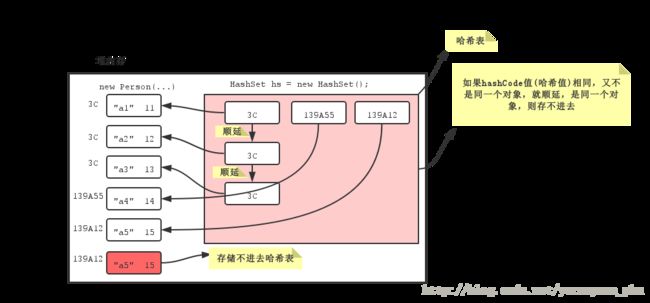
上面提到了HashSet集合采用哈希表结构存储数据,那什么是哈希表呢?
哈希表底层使用的也是数组机制,数组中也存放对象,而这些对象往数组中存放时的位置比较特殊,当需要把这些对象给数组存放时,会根据这些对象的特有数据结合相应的算法,计算出这个对象在数组中的位置,然后把这个对象存放在数组中。而这样的数组就称为哈希数组,即就是哈希表。
当向哈希表中存放元素时,需要根据元素的特有数据结合相应的算法,这个算法其实就是Object类中的hashCode方法。由于任何对象都是Object类的子类,所以任何对象都拥有这个方法。即就是在哈希表中存放对象时,会调用对象的hashCode方法,算出对象在表中的存放位置,这里需要注意,如果两个对象hashCode方法算出来的结果一样,这种现象称为哈希冲突,这时会调用对象的equals方法,比较这两个对象是不是同一个对象,如果equals方法返回的是true,那么就不会把第二个对象存放在哈希表中,如果返回的是false,就会把这个对象通过地址链接法或拉链法存放在哈希表中。
总结:保证HashSet集合元素的唯一,其实就是根据对象的hashCode和equals方法来决定的。如果我们往集合中存放自定义的对象,想要保证其唯一,就必须复写hashCode和equals方法建立属于当前对象的比较方式。
哈希表结构存储数据的原理用图来表示:

结论:Hashset是如何保证元素的唯一性的呢?——是通过元素的两个方法,hashCode()和equals()来完成的。即元素必须覆盖hashCode()和equals()方法,覆盖hashCode()方法是为了根据元素自身的特点确定哈希值,覆盖equals()方法是为了解决哈希值的冲突。
练习,往HashSet中存储学生对象(姓名,年龄)。同姓名,同年龄视为同一个人,不存。
解:HashSet中存放自定义类型元素时,需要重写对象中的hashCode和equals方法,建立自己的比较方式,才能保证HashSet集合中的对象唯一。
创建自定义对象Student
public class Student { private String name; private int age; public Student() { super(); } public Student(String name, int age) { super(); this.name = name; this.age = age; } /* * 覆盖hashCode方法,根据对象自身的特点定义哈希值。 */ public int hashCode() { final int NUMBER = 37; return name.hashCode() + age * NUMBER; // 尽量减小哈希冲突 } /** * 还需要定义对象自身判断内容相同的依据,覆盖equals()方法。 */ public boolean equals(Object obj) { if (this == obj) { return true; } if (!(obj instanceof Student)) { throw new ClassCastException("类型错误"); } Student stu = (Student) obj; return this.name.equals(stu.name) && this.age == stu.age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } @Override public String toString() { return "Student [name=" + name + ", age=" + age + "]"; } }创建HashSet集合,存储Student对象
public class HashSetTest { public static void main(String[] args) { // 1,创建容器对象 Set set = new HashSet(); // 2,存储学生对象 set.add(new Student("xiaoqiang", 20)); set.add(new Student("wangcai", 27)); set.add(new Student("xiaoming", 22)); set.add(new Student("xiaoqiang", 20)); set.add(new Student("daniu", 24)); set.add(new Student("wangcai", 27)); // 3,获取所有学生 for (Iterator it = set.iterator(); it.hasNext();) { Student stu = (Student) it.next(); System.out.println(stu.getName() + "::" + stu.getAge()); } } }HashSet保证元素的唯一性示意图:
注意:对于判断元素是否存在,以及删除、添加等操作,依赖的方法也是元素的hashCode()和equals()方法。
Set接口中常用的类——LinkedHashSet
通过查阅LinkedHashSet的API介绍,我们可知道:
具有可预知迭代顺序的Set接口的哈希表和链接列表实现。此实现与HashSet的不同之外在于,后者维护着一个运行于所有条目的双重链接列表。
可总结为:LinkedHashSet是一个特殊的Set集合,而且是有序的,底层是一个双向链表。
例,
public class LinkedHashSetDemo {
public static void main(String[] args) {
// 1,创建一个Set容器对象
Set set = new LinkedHashSet();
// 2,添加元素
set.add("abc");
set.add("heihei");
set.add("haha");
set.add("nba");
// 3,只能用迭代器取出
for (Iterator it = set.iterator(); it.hasNext();) {
System.out.println(it.next());
}
}
}运行以上程序,可知LinkedHashSet是有序的。
Set接口中常用的类——TreeSet
TreeSet是线程不同步的,可以对Set集合中的元素进行排序。底层数据结构是二叉树(也叫红黑树),保证元素唯一性的依据是:compareTo()方法return 0。更通俗一点说就是比较方法的返回值是否是0,只要是0,就是重复元素,不存。
TreeSet对集合中的元素进行排序的方式有两种,下面分别对其进行详细介绍:
- TreeSet排序的第一种方式:让元素自身具备比较性。元素需要实现Comparable接口,覆盖compareTo()方法。这种方式也称为元素的自然顺序,或者也叫默认顺序。
- TreeSet排序的第二种方式:当元素自身不具备比较性时,或者具备的比较性不是所需要的,这时就需要让集合自身具备比较性。在集合一初始化时,就具备比较方式。
具体做法是:定义一个比较器实现Comparator接口,覆盖compare方法,将Comparator接口的对象作为参数传递给TreeSet集合的构造函数。
注意:比较器更为灵活,自然排序通常都作为元素的默认排序。
例1,需求:往TreeSet集合中存储自定义对象学生。想按照学生的年龄进行排序。
解:
先看TreeSet排序的第一种方式:我们自定义的Student类须实现Comparable接口(该接口强制让Student类具备比较性),覆盖compareTo方法。
int compareTo(T o):比较此对象与指定对象的顺序。如果该对象小于、等于或大于指定对象,则分别返回负整数、零或正整数。
自定义的Student类的代码为:
public class Student implements Comparable {
private String name;
private int age;
public Student() {
super();
}
public Student(String name, int age) {
super();
this.name = name;
this.age = age;
}
/*
* 覆盖hashCode方法,根据对象自身的特点定义哈希值。
*/
public int hashCode() {
final int NUMBER = 37;
return name.hashCode() + age * NUMBER; // 尽量减小哈希冲突
}
/**
* 还需要定义对象自身判断内容相同的依据,覆盖equals()方法。
*/
public boolean equals(Object obj) {
if (this == obj) {
return true;
}
if (!(obj instanceof Student)) {
throw new ClassCastException("类型错误");
}
Student stu = (Student) obj;
return this.name.equals(stu.name) && this.age == stu.age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student [name=" + name + ", age=" + age + "]";
}
/**
* 学生就具备了比较功能。该功能是自然排序使用的方法。
* 自然排序就以年龄的升序排序为主。
*/
@Override
public int compareTo(Object o) {
Student stu = (Student)o;
// 验证TreeSet集合的add()方法调用了compareTo()方法
System.out.println(this.name + ":" + this.age + "......" + stu.name + ":" + stu.age) ;
if (this.age > stu.age)
return 1;
if (this.age < stu.age)
return -1;
return 0;
}
}接下来编写一个测试类——TreeSetDemo.java,其代码为:
public class TreeSetDemo {
public static void main(String[] args) {
Set set = new TreeSet();
set.add(new Student("xiaoqiang", 20));
set.add(new Student("daniu", 24));
set.add(new Student("xiaoming", 22));
set.add(new Student("tudou", 18));
set.add(new Student("dahuang", 19));
// 3,只能用迭代器取出
for (Iterator it = set.iterator(); it.hasNext();) {
Student stu = (Student) it.next();
System.out.println(stu.getName() + "::" + stu.getAge());
}
}
}运行以上程序,会发现TreeSet集合中存储的学生真是按照年龄来升序排序的。
接着我们面临的需求又发生了变化,同姓名同年龄的学生视为同一个人,是不用存入TreeSet集合中的,而且当年龄相同时,需要按照姓名的自然顺序排序。这时自定义的Student类的代码需要修改为:
public class Student implements Comparable {
private String name;
private int age;
public Student() {
super();
}
public Student(String name, int age) {
super();
this.name = name;
this.age = age;
}
/*
* 覆盖hashCode方法,根据对象自身的特点定义哈希值。
*/
public int hashCode() {
final int NUMBER = 37;
return name.hashCode() + age * NUMBER; // 尽量减小哈希冲突
}
/**
* 还需要定义对象自身判断内容相同的依据,覆盖equals()方法。
*/
public boolean equals(Object obj) {
if (this == obj) {
return true;
}
if (!(obj instanceof Student)) {
throw new ClassCastException("类型错误");
}
Student stu = (Student) obj;
return this.name.equals(stu.name) && this.age == stu.age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student [name=" + name + ", age=" + age + "]";
}
/**
* 学生就具备了比较功能。该功能是自然排序使用的方法。
* 自然排序就以年龄的升序排序为主。
*/
@Override
public int compareTo(Object o) {
Student stu = (Student)o;
// 验证TreeSet集合的add()方法调用了compareTo()方法
// System.out.println(this.name + ":" + this.age + "......" + stu.name + ":" + stu.age) ;
/*
* 既然是同姓名同年龄是同一个人,视为重复元素,要判断的要素有两个。
* 既然是按照年龄进行排序,所以先判断年龄,再判断姓名
*/
int temp = this.age - stu.age;
return temp == 0 ? this.name.compareTo(stu.name) : temp;
}
}这时测试类——TreeSetDemo.java的代码应改为:
public class TreeSetDemo {
public static void main(String[] args) {
Set set = new TreeSet();
set.add(new Student("xiaoqiang", 20));
set.add(new Student("daniu", 24));
set.add(new Student("xiaoming", 22));
set.add(new Student("tudou", 18));
set.add(new Student("daming", 22));
set.add(new Student("dahuang", 19));
// 3,只能用迭代器取出
for (Iterator it = set.iterator(); it.hasNext();) {
Student stu = (Student) it.next();
System.out.println(stu.getName() + "::" + stu.getAge());
}
}
}才能看出测试效果。
从中我们可以稍许了解到二叉树原理:
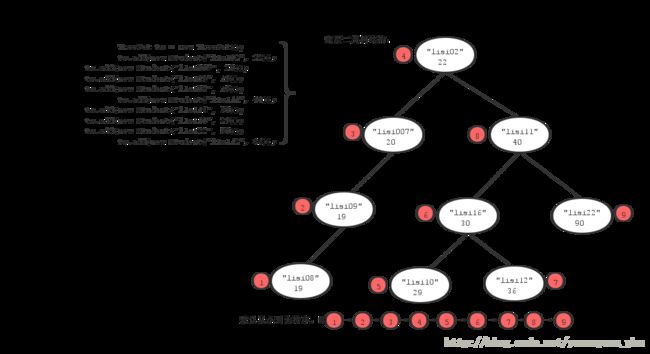
记住,排序时,当主要条件相同时,一定判断一下次要条件。
思考一个这样的问题:元素变为怎么存进去的就怎么取出来的,怎么做呢?
解:这时可依据二叉树原理来实现,只要让compareTo()方法返回正数即可,比如:
import java.util.*;
class Student implements Comparable { // 该接口强制让学生具备比较性
private String name;
private int age;
Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
public int compareTo(Object obj) {
return 1;
}
}
class TreeSetDemo {
public static void main(String[] args) {
TreeSet ts = new TreeSet();
ts.add(new Student("lisi02", 22));
ts.add(new Student("lisi007", 20));
ts.add(new Student("lisi09", 19));
ts.add(new Student("lisi08", 19));
Iterator it = ts.iterator();
while(it.hasNext()) {
Student stu = (Student)it.next();
System.out.println(stu.getName()+"..."+stu.getAge());
}
}
}例2,将Student对象存储到TreeSet集合中,同姓名同年龄视为同一个人,不存,按照学生的姓名进行升序排序,而且当姓名相同时,需要按照学生的年龄进行升序排序。
解:当元素自身不具备比较性时,或者具备的比较性不是所需要的,这时就需要让容器自身具备比较性。定义一个比较器,将比较器对象作为参数传递给TreeSet集合的构造函数。当两种排序都存在时,以比较器为主。
我们自定义的Student类的代码没必要修改。接着,自定义一个比较器实现Comparator接口,覆盖compare()方法。
int compare(T o1, T o2):比较用来排序的两个参数。根据第一个参数小于、等于或大于第二个参数分别返回负整数、零或正整数。
自定义比较器——ComparatorByName.java的代码为:
/**
* 自定义一个比较器,用来对学生对象按照姓名进行升序排序
* @author li ayun
*
*/
public class ComparatorByName /*extends Object 继承Object类覆盖了equals()方法*/ implements Comparator {
@Override
public int compare(Object o1, Object o2) {
Student s1 = (Student) o1;
Student s2 = (Student) o2;
int temp = s1.getName().compareTo(s2.getName());
return temp == 0 ? s1.getAge() - s2.getAge() : temp;
}
}最后编写一个测试类——TreeSetDemo2.java进行测试。
public class TreeSetDemo2 {
public static void main(String[] args) {
// 初始化TreeSet集合时明确一个比较器
Set set = new TreeSet(new ComparatorByName()); // 此时学生对象自己具备的比较方式不是我们所需要的
set.add(new Student("xiaoqiang", 20));
set.add(new Student("daniu", 24));
set.add(new Student("xiaoming", 22));
set.add(new Student("tudou", 18));
set.add(new Student("daming", 22));
set.add(new Student("daming", 29));
set.add(new Student("dahuang", 19));
for (Iterator it = set.iterator(); it.hasNext();) {
Student stu = (Student) it.next();
System.out.println(stu.getName() + "::" + stu.getAge());
}
}
}练习一、对多个字符串(不重复)按照长度排序(由短到长)。
解:字符串本身具备比较性,但是它的比较方式不是所需要的,这时就只能使用比较器。
先自定义一个比较器——ComparatorByLength.java:
public class ComparatorByLength implements Comparator {
@Override
public int compare(Object o1, Object o2) {
// 对字符串按照长度比较
String s1 = (String) o1;
String s2 = (String) o2;
// 比较长度
int temp = s1.length() - s2.length();
// 长度相同,再按字典顺序
return temp == 0 ? s1.compareTo(s2) : temp;
}
}再编写一个测试类Test.java进行测试:
public class Test {
public static void main(String[] args) {
sortStringByLength();
}
/*
* 练习一:对多个字符串(不重复)按照长度排序(由短到长)
*
* 思路:
* 1,多个字符串,需要容器存储。
* 2,选择哪个容器。字符串是对象,可以选择集合,而且不重复,选择Set集合
* 3,还需要排序,可以选择TreeSet集合。
*
*/
public static void sortStringByLength() {
Set set = new TreeSet(new ComparatorByLength()); // 自然排序的方式
set.add("haha");
set.add("abc");
set.add("zz");
set.add("nba");
set.add("xixixi");
for (Object obj : set) {
System.out.println(obj);
}
}
}练习二、对多个字符串(重复),按照长度排序。
解:自然排序可以使用String类中的compareTo方法,但是现在要的是长度排序,这就需要比较器了。所以须定义一个按照长度排序的比较器对象。
public class ComparatorByLength implements Comparator {
@Override
public int compare(Object o1, Object o2) {
// 对字符串按照长度比较
String s1 = (String) o1;
String s2 = (String) o2;
// 比较长度
int temp = s1.length() - s2.length();
// 长度相同,再按字典顺序
return temp == 0 ? s1.compareTo(s2) : temp;
}
}接下来编写一个测试类Test.java进行测试:
public class Test {
public static void main(String[] args) {
sortStringByLength();
}
/*
* 练习二:对多个字符串(重复),按照长度排序。
*
* 思路:
* 1,能使用TreeSet吗?不能。
* 2,可以存储到数组,List。这里先选择数组。
*/
public static void sortStringByLength() {
String[] strs = {"nba", "haha", "abccc", "zero", "xixi", "nba", "abccc", "cctv", "zero"};
// 自然排序可以使用String类中的compareTo方法,
// 但是现在要的是长度排序,这就需要比较器。
// 定义一个按照长度排序的比较器对象
Comparator comp = new ComparatorByLength();
// 排序就需要嵌套循环,位置置换
for (int x = 0; x < strs.length - 1; x++) {
for (int y = x + 1; y < strs.length; y++) {
// if (strs[x].compareTo(strs[y]) > 0) { // 按照字典顺序
if (comp.compare(strs[x], strs[y]) > 0) { // 按照长度顺序
swap(strs, x, y);
}
}
}
for (String s : strs) {
System.out.println(s);
}
}
private static void swap(String[] strs, int x, int y) {
String temp = strs[x];
strs[x] = strs[y];
strs[y] = temp;
}
}集合名称阅读技巧
JDK1.2以后出现的集合框架中的常用子类对象,存在的子类规律可总结为:前缀名是数据结构名,后缀名是所属体系名。如:
- ArrayList
数组结构。看到数组,就知道查询快;看到List,就知道可以重复,可以增删改查。 - LinkeList
链表结构。增删快。 - HashSet
哈希表,就要想到元素必须覆盖hashCode()和equals()方法,查询速度更快。不保证有序,看到set,就知道不可以重复。 - LinkedHashSet
链表+哈希表。可以实现有序,因为有链表。 - TreeSet
二叉树,可以排序。就要想到两种比较方式:一种是自然排序Comparable,一种是比较器Comparator。