用Python操作excel文档
使用Python第三方库
这一节我们学习如何使用Python去操作Excel文档。如果大家有人不知道Excel的话,那么建议先学一学office办公基础。这里想要操作Excel,必须安装一个Python第三方库。
有人可能会疑问,第三方库是什么?其实第三方库就是非Python官方提供的库,也就是民间好心人开发出来的开源库,供大家免费使用。那这里肯定又有人会疑问,库是什么呢?我们前面已经知道了Python模块,其实库就是一个或多个相关连的Python模块合在一起,这样说很容易理解吧。通常Python中的所谓库,其实就是一个文件夹,这个文件夹中放了几个Python模块,而一个Python源代码文件就是一个模块。
安装
第三方库和Python的标准库不同,它需要我们手动去安装,不安装是没法使用的。这里简要说一下如何安装Python第三方库。通常一些书籍或网络博客中,推荐使用pip命令去自动下载安装第三方库,但是前提是需要我们将pip配置到环境变量中。这样去使用存在一些问题,当我们电脑装了多个Python版本时,极容易造成pip环境混乱。我在这里介绍一个小技巧,不需要去配置pip到环境变量中,且不会造成环境混乱。当我们需要使用pip命令时,在它前面加上python -m去使用,如下
python -m pip install 第三方库名称
好了,今天我们要使用的第三方库叫做openpyxl,大家一定要记住这个库名字哦,按照我们上面学习的公式,打开WIndows上面的cmd命令行,输入如下命令安装
python -m pip install openpyxl
如果大家的网络不好,就需要耐心等待,安装完成之后,命令行中会看到如下内容
Successfully installed et-xmlfile-1.0.1 jdcal-1.4 openpyxl-2.6.0
如果大家的命令行中出现以下内容
You should consider upgrading via the 'python -m pip install --upgrade pip' command
则按照英文提示,先输入python -m pip install --upgrade pip执行一下,这个命令是升级我们的pip版本的,升级成功后,再去执行python -m pip install openpyxl
使用
实际上Excel文档也是一个文件,它虽然不是我们之前学的纯文本文件,但它也是文件,脱离不了文件的读与写两种操作。
先让我们认识一下Excel的一些概念,有助于我们理解代码,这里主要是三个概念,行、列和Sheet表。如下图
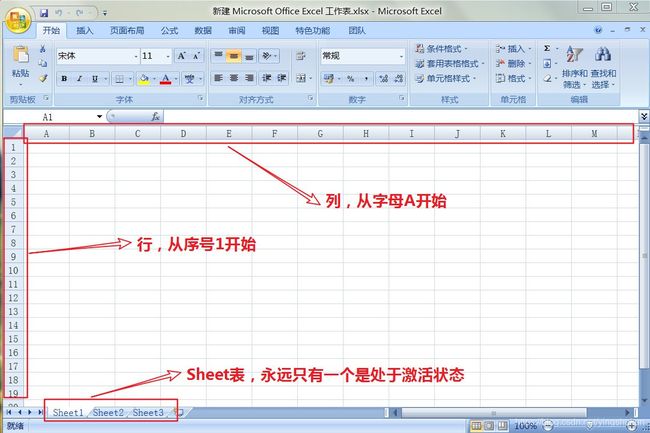
当我们选中第一行的第A列小格子时,可以看到上面的显示框中显示的是A1,再次选中第二行的第A列小格子时,则会显示A2,由此我们即可掌握规律,Excel中的行列坐标,是使用列号+行号的方式定位。
写Excel文档
import openpyxl as exl
# 创建一个工作簿对象
wb = exl.Workbook()
# 获取一个激活的sheet表,相当于获取第一个Sheet表
sheet = wb.active
# 给sheet表取一个名字
sheet.title = '一班'
sheet['A1'] = '学号'
sheet['B1'] = '姓名'
sheet['C1'] = '语文'
sheet['D1'] = '数学'
sheet['E1'] = '英语'
sheet['A2'] = '201901'
sheet['B2'] = '王五'
sheet['C2'] = 81.5
sheet['D2'] = 90
sheet['E2'] = 85
wb.save('test.xlsx')
运行如上代码后,我们可以看到代码当前目录下生成了一个test.xlsx的Excel文档。
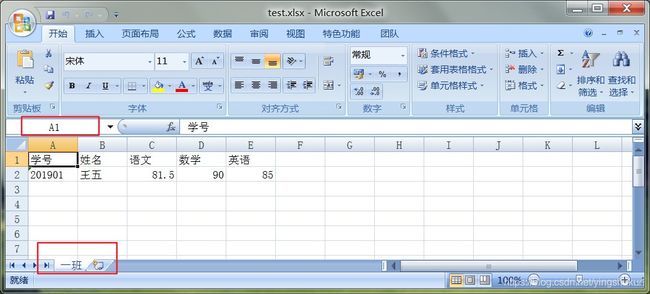
可以看到,我们通过几行简单代码就创建了一个Excel文档。当然,上述代码中,我们是纯手动的去填表的,如果我们的表有1000行,我们不可能这样手写代码填入信息,因此我们应当借助循环去完成这种枯燥的事情,还记得我们前面学过的章节吗,循环是重复的艺术。
# 导入我们已安装的第三方库openpyxl
import openpyxl as exl
# 创建一个存放数据的列表,该列表中元素也是一个列表,每一个元素代码一行数据
data = [
['学号', '姓名', '语文', '数学', '英语'],
['201901', '张三', 90, 68.5, 95],
['201902', '李四', 50, 71, 83],
['201903', '王五', 73, 91, 69],
['201904', '赵六', 85.6, 36, 77],
]
# 定义一个函数,用于写入一行数据,参数i用于Excel中的行号,参数row是一个列表,存放的是一行数据
def write_row(i, row):
# 获取全局变量sheet
global sheet
# 字符串使用 “+”连接符进行拼接。这里变量i必须是字符串,只有字符串才能和字符串拼接
sheet['A' + i] = row[0]
sheet['B' + i] = row[1]
sheet['C' + i] = row[2]
sheet['D' + i] = row[3]
sheet['E' + i] = row[4]
# 创建一个工作簿对象
wb = exl.Workbook()
# 创建一个激活的sheet表
sheet = wb.active
# 给sheet表取一个名字
sheet.title = '一班'
for index, line in enumerate(data):
print(index, line)
# Excel中行号从1开始,而列表的序号是从0开始,因此要加1,并将该整数转换为字符串变量
write_row(str(index + 1), line)
wb.save('test.xlsx')
特别注意:
大家在用Python操作Excel时,请务必将相应的文档关闭。如果你操作的文档已经被打开了,那么代码运行是会报错退出的。如遇报错,请检查是否关闭了Excel文档 。
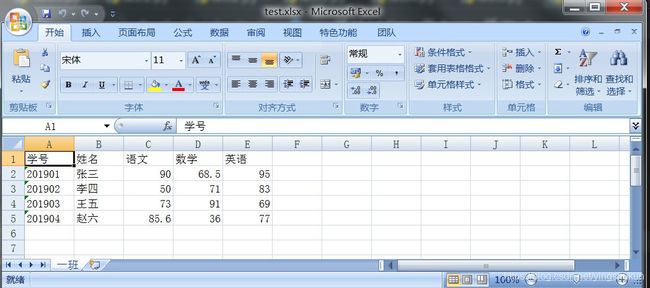
以上代码比较简单,只有一个新知识点需要说明一下,我们以前也使用for循环去遍历列表,这里和以往不同的地方在于我们在in之后调用了一个enumerate函数,该函数的作用是可以返回两个参数,第一个参数是返回元素在列表中的索引,即序号,第二个参数才是元素的内容,即元素的值。
大家如果对这个用法不熟悉,可以稍加练习一下
infos = ["Python", "Java", "C", "C++", "Go"]
for i, item in enumerate(infos):
print(i, item)
输出结果
0 Python
1 Java
2 C
3 C++
4 Go
美化
这里简单说一下关于美化的问题,我们的Excel表格没有加边框,看起来没有主次感觉,我们可以添加一点代码美化一下
import openpyxl as exl
# 导入openpyxl库的styles模块
import openpyxl.styles as sl
# 创建一个存放数据的列表,该列表中元素也是一个列表,每一个元素代码一行数据
data = [
['学号', '姓名', '语文', '数学', '英语'],
['201901', '张三', 90, 68.5, 95],
['201902', '李四', 50, 71, 83],
['201903', '王五', 73, 91, 69],
['201904', '赵六', 85.6, 36, 77],
]
# 定义一个函数,用于写入一行数据
def write_row(i, row):
# 获取全局变量sheet, align, side, border
global sheet, align, side, border
sheet['A' + i] = row[0]
sheet['A' + i].border = border
sheet['A' + i].alignment = align
sheet['B' + i] = row[1]
sheet['B' + i].border = border
sheet['B' + i].alignment = align
sheet['C' + i] = row[2]
sheet['C' + i].border = border
sheet['C' + i].alignment = align
sheet['D' + i] = row[3]
sheet['D' + i].border = border
sheet['D' + i].alignment = align
sheet['E' + i] = row[4]
sheet['E' + i].border = border
sheet['E' + i].alignment = align
# 创建一个工作簿对象
wb = exl.Workbook()
# 创建一个激活的sheet表
sheet = wb.active
# 给sheet表取一个名字
sheet.title = '一班'
# 设置单元格文本对齐方式,这里设置横向和水平都居中
align = sl.Alignment(horizontal='center', vertical='center', wrap_text=True)
# 设置边框线的样式和颜色
side = sl.Side(border_style='thin', color='FF000000')
# 设置单元格的上下左右四个方向都加边框线
border = sl.Border(left=side, right=side, top=side, bottom=side)
for index, line in enumerate(data):
print(index, line)
write_row(str(index + 1), line)
wb.save('test.xlsx')

更多的样式设置方式,请大家查询openpyxl库的文档。openpyxl 文档
读Excel文档
我们上面已经学会了写,现在来学习一下怎么去读取Excel文档。
import openpyxl as exl
# 根据文件名打开一个Excel工作簿,并返回工作簿对象
wb = exl.load_workbook('test.xlsx')
# 根据sheet表的名字,获取到指定的sheet表
sheet = wb['一班']
# sheet.rows返回当前sheet表的所有行,我们将其转换为一个列表方便操作
# 列表中的每一个元素就是一行数据
all_row = list(sheet.rows)
# 取第二行第一列单元格中的值
print(all_row[1][0].value)
输出结果:
201901
以上代码中,大家可能看不习惯一种写法,这里多写多看就会习惯,这种语法正是Python简洁的特性。
# 简洁表达
print(all_row[1][0].value)
# 相当于以下写法
# 取全部行列表中的第二个元素,即第二行
line = all_row[1]
# 该行也是列表,取第一个元素,则相当于第二行第一列。
# 由于这个列表中的元素是单元格对象,并不是字符串,因此需要调用其value属性获取单元格的值
print(line[0].value)
以上代码是纯手工取值的,接下来我们通过循环去自动遍历全部值
import openpyxl as exl
# 根据文件名打开一个Excel工作簿,并返回工作簿对象
wb = exl.load_workbook('test.xlsx')
# 根据sheet表的名字,获取到指定的sheet表
sheet = wb['一班']
# sheet.rows返回当前sheet表的所有行,并将其转换为一个列表,列表中的每一个元素就是一行数据
all_row = list(sheet.rows)
for cell in all_row:
print(cell[0].value, cell[1].value, cell[2].value, cell[3].value, cell[4].value)
输出结果:
学号 姓名 语文 数学 英语
201901 张三 90 68.5 95
201902 李四 50 71 83
201903 王五 73 91 69
201904 赵六 85.6 36 77
现在让我们利用代码遍历的优势,做一点实际用途
import openpyxl as exl
# 根据文件名打开一个Excel工作簿,并返回工作簿对象
wb = exl.load_workbook('test.xlsx')
# 根据sheet表的名字,获取到指定的sheet表
sheet = wb['一班']
# sheet.rows返回当前sheet表的所有行,并将其转换为一个列表,列表中的每一个元素就是一行数据
all_row = list(sheet.rows)
for i, cell in enumerate(all_row):
# 跳过第一行表头(i等于0时,是表头)
if i != 0:
# 给每个人算一下三门课总分
count = cell[2].value + cell[3].value + cell[4].value
print(cell[1].value, count)
sum = 0
# 计算一班所有人的语文平均分。
for i, cell in enumerate(all_row):
# 跳过第一行表头(i等于0时,是表头)
if i != 0:
# 使用累加法,求得所有人的语文成绩总和
sum += cell[2].value
# 使用内置函数len 获取列表中的元素个数,即总行数
lenght = len(all_row)
# 求平均分,除以总人数。总行数要减去表头那行
print("语文平均分", sum / (lenght - 1))
输出结果:
张三 253.5
李四 204
王五 233
赵六 198.6
语文平均分 74.65
我们今天学习的内容是很有实用性的,特别有用的一种情景是,当100个人每人填完了一份Excel文档发给你汇总时,你只需要简单的几行Python代码,就能将提交的这一百份Excel文档合并成一份总的Excel文档。
请关注公众号:编程之路从0到1
进入公众号还有视频内容
