零基础入门CV赛事—Task 3字符识别模型
本章开始构建一个字符识别模型,基于对赛题理解本章将构建一个定长多字符分类模型。
3 字符识别模型
本章将会讲解卷积神经网络(Convolutional Neural Network, CNN)的常见层,并从头搭建一个字符识别模型。
3.1 学习目标
- 学习CNN基础和原理
- 使用Pytorch框架构建CNN模型,并完成训练
3.2 CNN
3.2.1 CNN简介
卷积神经网络(全称Convolutional Neural Networks,简称 CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习的代表算法之一 。卷积神经网络具有表征学习(representation learning)能力,能够按其阶层结构对输入信息进行平移不变分类,因此也被称为“平移不变人工神经网络。特别是在计算机视觉领域,CNN是解决图像分类、图像检索、物体检测和语义分割的主流模型。
CNN每一层由众多的卷积核组成,每个卷积核对输入的像素进行卷积操作,得到下一次的输入。随着网络层的增加卷积核会逐渐扩大感受野,并缩减图像的尺寸。
3.2.2 CNN结构
1.输入层
卷积神经网络的输入层可以处理多维数据,常见地,一维卷积神经网络的输入层接收一维或二维数组,二维卷积神经网络的输入层接收二维或三维数组;三维卷积神经网络的输入层接收四维数组 。由于卷积神经网络在计算机视觉领域应用较广,因此许多研究在介绍其结构时预先假设了三维输入数据,即平面上的二维像素点和RGB通道。
与其它神经网络算法类似,由于使用梯度下降算法进行学习,卷积神经网络的输入特征需要进行标准化处理。若输入数据为像素,也可将分布于 的原始像素值归一化至 区间 [16] 。输入特征的标准化有利于提升卷积神经网络的学习效率和表现 [16] 。
2.隐含层
卷积神经网络的隐含层包含卷积层、池化层和全连接层3类常见构筑,在一些更为现代的算法中可能有其他复杂构筑。在常见构筑中,卷积层和池化层为卷积神经网络特有。卷积层中的卷积核包含权重系数,而池化层不包含权重系数。以LeNet-5为例,3类常见构筑在隐含层中的顺序通常为:输入-卷积层-池化层-全连接层-输出。
2.1卷积层
卷积层的功能是对输入数据进行特征提取,其内部包含多个卷积核,组成卷积核的每个元素都对应一个权重系数和一个偏差量,类似于一个前馈神经网络的神经元。卷积层内每个神经元都与前一层中位置接近的区域的多个神经元相连,区域的大小取决于卷积核的大小,被称为“感受野“。
2.2池化层
在卷积层进行特征提取后,输出的特征图会被传递至池化层进行特征选择和信息过滤。池化层包含预设定的池化函数,其功能是将特征图中单个点的结果替换为其相邻区域的特征图统计量。
2.3全连接层
全连接层位于卷积神经网络隐含层的最后部分,并只向其它全连接层传递信号。特征图在全连接层中会失去空间拓扑结构,被展开为向量。全连接层的作用则是对提取的特征进行非线性组合以得到输出,即全连接层本身不被期望具有特征提取能力,而是试图利用现有的高阶特征完成学习目标。
在一些卷积神经网络中,全连接层的功能可由全局均值池化(global average pooling)取代 [41] ,全局均值池化会将特征图每个通道的所有值取平均,即若有7×7×256的特征图,全局均值池化将返回一个256的向量,其中每个元素都是7×7,步长为7,无填充的均值池化。
4.输出层
对于图像分类问题,输出层使用逻辑函数或归一化指数函数输出分类标签 。在物体识别问题中,输出层可设计为输出物体的中心坐标、大小和分类。
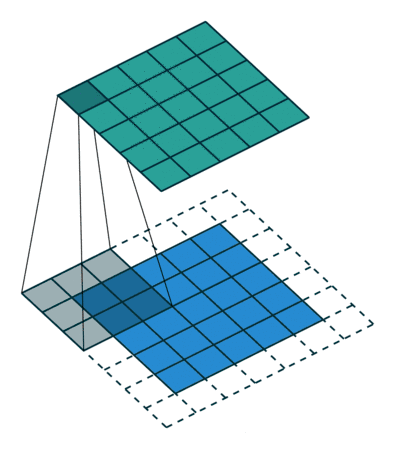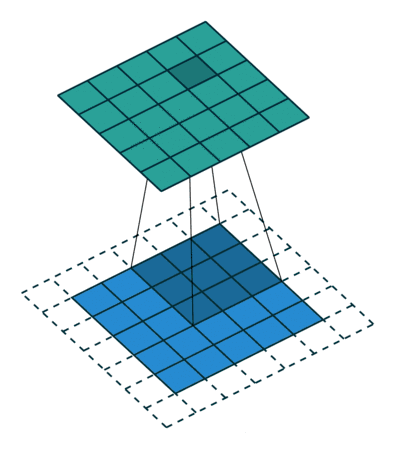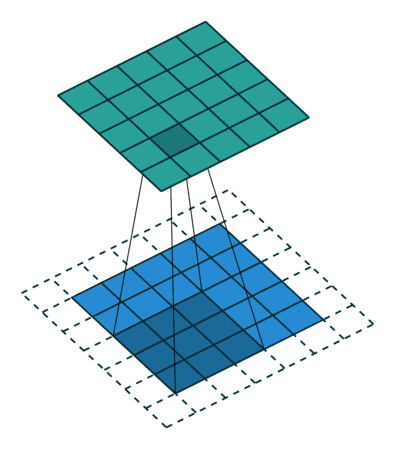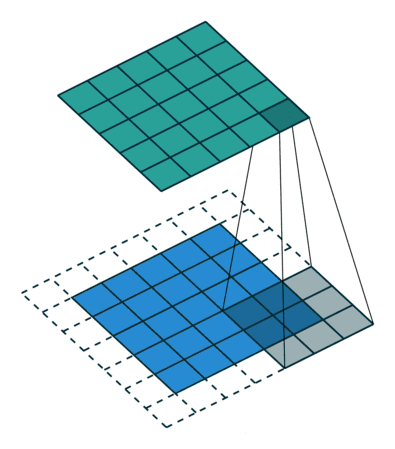
LeNet5网络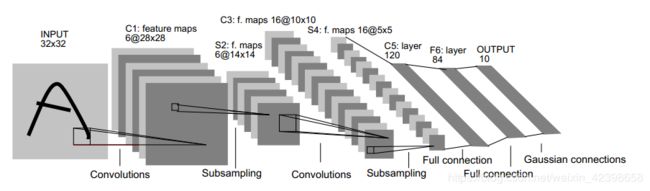
3.3 Pytorch构建CNN模型
在Pytorch中构建CNN模型非常简单,只需要定义好模型的参数和正向传播即可,Pytorch会根据正向传播自动计算反向传播。
在本章我们会构建一个非常简单的CNN,然后进行训练。这个CNN模型包括两个卷积层,最后并联6个全连接层进行分类。
import torch
torch.manual_seed(0)
torch.backends.cudnn.deterministic = False
torch.backends.cudnn.benchmark = True
import torchvision.models as models
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
from torch.utils.data.dataset import Dataset
# 定义模型
class SVHN_Model1(nn.Module):
def __init__(self):
super(SVHN_Model1, self).__init__()
# CNN提取特征模块
self.cnn = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=(3, 3), stride=(2, 2)),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(16, 32, kernel_size=(3, 3), stride=(2, 2)),
nn.ReLU(),
nn.MaxPool2d(2),
)
#
self.fc1 = nn.Linear(32*3*7, 11)
self.fc2 = nn.Linear(32*3*7, 11)
self.fc3 = nn.Linear(32*3*7, 11)
self.fc4 = nn.Linear(32*3*7, 11)
self.fc5 = nn.Linear(32*3*7, 11)
self.fc6 = nn.Linear(32*3*7, 11)
def forward(self, img):
feat = self.cnn(img)
feat = feat.view(feat.shape[0], -1)
c1 = self.fc1(feat)
c2 = self.fc2(feat)
c3 = self.fc3(feat)
c4 = self.fc4(feat)
c5 = self.fc5(feat)
c6 = self.fc6(feat)
return c1, c2, c3, c4, c5, c6
model = SVHN_Model1()
接下来是训练代码:
# 损失函数
criterion = nn.CrossEntropyLoss()
# 优化器
optimizer = torch.optim.Adam(model.parameters(), 0.005)
loss_plot, c0_plot = [], []
# 迭代10个Epoch
for epoch in range(10):
for data in train_loader:
c0, c1, c2, c3, c4, c5 = model(data[0])
loss = criterion(c0, data[1][:, 0]) + \
criterion(c1, data[1][:, 1]) + \
criterion(c2, data[1][:, 2]) + \
criterion(c3, data[1][:, 3]) + \
criterion(c4, data[1][:, 4]) + \
criterion(c5, data[1][:, 5])
loss /= 6
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_plot.append(loss.item())
c0_plot.append((c0.argmax(1) == data[1][:, 0]).sum().item()*1.0 / c0.shape[0])
print(epoch)
当然为了追求精度,也可以使用在ImageNet数据集上的预训练模型,具体方法如下
class SVHN_Model2(nn.Module):
def __init__(self):
super(SVHN_Model1, self).__init__()
model_conv = models.resnet18(pretrained=True)
model_conv.avgpool = nn.AdaptiveAvgPool2d(1)
model_conv = nn.Sequential(*list(model_conv.children())[:-1])
self.cnn = model_conv
self.fc1 = nn.Linear(512, 11)
self.fc2 = nn.Linear(512, 11)
self.fc3 = nn.Linear(512, 11)
self.fc4 = nn.Linear(512, 11)
self.fc5 = nn.Linear(512, 11)
def forward(self, img):
feat = self.cnn(img)
# print(feat.shape)
feat = feat.view(feat.shape[0], -1)
c1 = self.fc1(feat)
c2 = self.fc2(feat)
c3 = self.fc3(feat)
c4 = self.fc4(feat)
c5 = self.fc5(feat)
return c1, c2, c3, c4, c5