Mask TextSpotter: An End-to-End Trainable Neural Network for Spotting Text with Arbitrary Shapes
Mask TextSpotter
摘要
Mask TextSpotter利用了端对端学习流程的简单和顺利的优势,通过语义分割获得更准确的文本检测和识别。而且,在处理不规则形状的文本实例中,如弯曲文本,优于之前的方法。
- 引言
近年来,场景文本检测和识别逐渐吸引了机器视觉领域中的研究兴趣,尤其是在神经网络复兴及图像数据集增长后。由于文本检测和识别提供了一个自动快速的方法来获得在自然场景中包含的文本信息,有利于很多真实世界的应用,如地理定位、即时翻译和辅助盲人。
Scene text spotting旨在同时定位和识别自然场景中的文本,在之前有很多工作研究。但是,大多数工作中,除了【27】和【3】,文本定位和后续的识别是分开处理的。首先用一个训练好的检测器从原始图片中获得文本区域,然后送到识别模块。这个流程看似简单自然,但是可能导致对于检测和识别不是最优的结果,因为这两个任务有着很高的相关性和互补性。一方面,检测质量很大程度决定了识别准确率;另一方面,识别结果可以反馈回去帮助检测阶段去除错误的正样本(FP)。
最近,针对场景文本spotting,提出了两个端对端训练的网络框架。受益于检测和识别之间的互补性,这些统一的模型很大程度上由于之前的方法。但是,在【27】和【3】中有两个主要的缺点。首先,它们都不能完全以端对端的形式进行训练。【27】在训练阶段用了课程学习模式,这里用于文本识别的自网络在前边的迭代中固定,每个阶段的训练数据也是很仔细的选择。【3】首先是分开预训练网络的检测和识别,然后联合训练直到收敛。这里主要有两个原因阻止【27】和【3】以一个流畅的端对端的形式进行模型训练。一是,文本识别部分在训练时要求准确的定位,同时在早期的迭代中定位通常是不准确的。另外,适用的LSTM和CTC loss比普通的CNN难优化。【27】和【3】的第二个限制是这些方法只关注阅读水平或有角度的文本。但是在真实世界场景中的文本实例的形状可能变化很大,形成水平的、多方向的及弯曲的形式。
在本文中,我们提出了个名为Mask TextSpotter的文本spotter,可以检测和识别任意形状的文本实例。这里,任意形状表示在真实世界中的各种形式的文本实例。受可以生成目标的形状掩模的Msak R-CNN的启发,我们通过分割实例文本区域来检测文本。因此我们的检测器可以检测任意形状的文本。除此之外,不同于之前的基于序列的识别方法,设计一维序列,我们通过在2-D的语义分割来识别文本,来解决理解不规则文本实例。另外一个优势就是识别不要求准确的定位。所以,检测任务和识别任务可以完全进行端对端的训练,受益于特征共享和联合优化。
我们在包括水平、多方向和弯曲文本的数据集上验证了我们模型的有效性。结构说明了提出算法在文本检测和端对端的文本识别任务的优势。明确地,在ICDAR2015上,在单一尺度评估,我们的方法在检测任务上获得0.86的F-Measure,比之前端对端是别人五中最高的效果高了13.2%-25.3%。
本文的主要贡献有四部分。(1)、我们针对文本spotting提出了一个可端对端训练的模型,一个简单流畅的训练方案。(2)、提出的方法可以检测和识别各种形状的文本,包括水平、多方向及弯曲文本。(3)、与之前的方法对比,我们的方法通过语义分割获得了准确的文本定位和识别。(4)、我们的方法在很多基准上,在文本检测和文本spotting上都获得了最优的效果。
- 相关工作
2.1、场景文本检测
在场景文本识别系统中,文本检测扮演着重要的角色。已经提出了大量的方法来检测场景文本。【21】中,Jaderberg等人用Edge Boxes生成候选框,然后用回归来微调候选框。【54】Zhang等人利用文本的对称性来检测场景文本。用精心的设计修改来改进Faster R-CNN和SSD,【56】和【30】被提出来检测水平文字。
近年来多方向场景文本检测成为了很热的话题。【52】Yao等人和【55】Zhang等人通过语义分割来检测多方向场景文本。【48】Tian和【43】Shi提出的方法是首个检测文本片段,然后通过空间关系或连接预测将其连接为文本实例。【57】Zhou和【16】He直接从密集分割图来回归文本框。【35】Lyu等人提出检测文本的角点并将其分组,然后生成文本框。【31】Liao提出了针对多方向场景文本检测的方向敏感回归。
对比流行的水平或多方向的场景文本检测,这里很少有工作关注任意形状的文本实例。最近,由于现实生活中的应用需求,任意形状的文本检测吸引了越来越多研究者的关注。在【41】中,Risnumawan等人提出了一个基于文本对称性的任意文本检测系统。在【4】中,提出了一个关注曲线方向文本检测的数据集。不同于上边提到的大部分方法,我们提出了通过实例分割来检测场景文本,可以检测任意形状的文本。
2.2、场景文本识别
场景文本识别【53】、【46】旨在将检测到的或者分割出的图片区域编码为字符序列。之前的场景文本识别方法可以大概分为三个分支:基于字符的方法、基于单词的方法和基于序列的方法。基于字符的识别方法【2】、【22】大多数首先定位单个字符然后识别再将其组合为单词。在【20】中,Jaderberg等人提出基于单词的方法,将文本识别看作是通常的英文单词(90k)的分类问题。基于序列的方法将文本识别看作是序列标签问题来解决。在【44】中,Shi等人用CNN和RNN来构建图像特征,用CTC输出识别序列。在【26】、【45】中,Lee等人和Shi等人通过基于注意力的序列-序列的模型来识别场景文本。
在我们提出的框架中的文本识别部分可以分为基于字符的方法。但是,对于之前基于字符的方法,我们用FCN同时定位和分类字符。此外,和设计为1-D序列的基于序列的方法对比,我们的方法更适合处理不规则文本(多方向文本、弯曲文本等)。
2.3、场景文本Spotting
之前的文本spotting方法大部分是将spotting过程分为两阶段。首先用一个场景文本检测器【21】、【30】、【29】来定位文本实例,然后用文本识别器【20】、【44】来获得识别文本。在【27】、【3】中,Li和Busta等人提出了端对端的方法来在一个统一的网络中检测识别文本,但是要求相对复杂的训练流程。对比这些方法,我们提出的文本spotter不仅可以进行完全端对端的训练,而且可以检测识别任意形状的场景文本。
2.4、一般的目标检测和语义分割
随着深度学习的发展,通常的目标检测和语义分割已经获得了很大的进展。大量的目标检测和分割方法被提出。受益于这些方法,场景文本检测和识别在过去的几年里也获得了明显的进步。我们的方法也是受这些方法的启发。明确的,我们的方法利用了通常的目标实例分割模型Mask R-CNN。但是,在我们的方法中的mask分支和Mask R-CNN中的分支之间,有一些关键的不同点。我们的mask分支不仅可以分割文本区域,还可以预测字符概率map,这就意味着我们的方法可以用于识别字符map中的实例序列而不是仅仅预测目标mask。
3、方法
提出的方法是一个可进行端对端训练的文本spotter,可以处理各种形状的文本。它包括一个基于实例分割的文本检测器和一个基于字符分割的文本识别器。
3.1、框架
我们提出的方法的总体结构如图2所示。功能上,框架包括四个部分:一个特征金字塔网络(FPN)作为backbone,一个区域建议网络(RPN)来生成文本候选框,一个Fast R-CNN来进行边界框回归,一个mask分支来进行文本实例分割和字符分割。在训练阶段,首先用RPN来生成大量文本候选框,然后候选框的RoI特征送入到Fast R-CNN分支中,mask分支生成准确的文本候选框、文本实例分割map以及字符分割map。
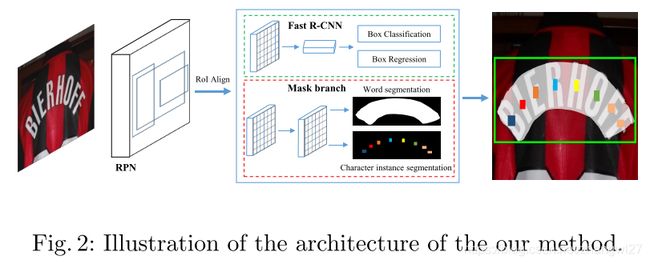
Backbone 自然图像中的文本大小变化很大。为了在所有的尺度上构建高级别的语义特征map,我们利用了有50层深的ResNet的FPN主干网络。FPN利用top-down的结构来融合来自同一尺度输入的不同分辨率的特征,用一点代价来提高准确率。
RPN RPN是用于为后续的Fast R-CNN和mask分支生成文本候选框的。根据【32】,我们根据anchor大小在不同阶段分配anchor。明确的,anchors的面积在五个阶段 {P2 ,P3 ,P4 ,P5,P6 }分别为![]() 。在每个阶段采用的不同的宽高比{0.5,1,2}也和【40】中一样。以这种方式,RPN可以处理各种大小和宽高比的区域。采用RoI Align提取候选框的区域特征。对比RoI Pooling,RoI Align保留了更准确的位置信息,这对在mask分支的分割任务是很有益的。注意到没有针对文本采用特殊的设计,例如特定的宽高比或带角度的anchor,像之前工作那样【30】、【15】、【34】.
。在每个阶段采用的不同的宽高比{0.5,1,2}也和【40】中一样。以这种方式,RPN可以处理各种大小和宽高比的区域。采用RoI Align提取候选框的区域特征。对比RoI Pooling,RoI Align保留了更准确的位置信息,这对在mask分支的分割任务是很有益的。注意到没有针对文本采用特殊的设计,例如特定的宽高比或带角度的anchor,像之前工作那样【30】、【15】、【34】.
Fast R-CNN 这个Fast R-CNN分支包括一个分类任务和一个回归任务。这个分支的主要功能是为检测提供更准确的边界框。Fast R-CNN的输入是7*7的分辨率大小,是RPN从候选框用RoI Align生成的。
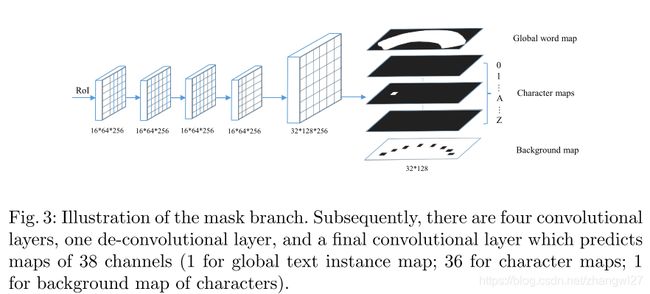
Mask Branch 在mask分支中有两个任务,包括全局文本实例分割任务和一个字符分割任务。如图3所示,给定输入RoI,大小固定为16*64,通过4层卷积和一个反卷积层,mask分支预测38个map(大小为32*128),包括一个全局文本实例map,36个字符map和一个字符的背景map。全局文本实例map可以给出一个文本区域的准确定位,不管文本实例的形状。字符map是36个字符的map,包括26个字母和10个阿拉伯数字。字符的背景map不包括字符区域,用于后处理。
3.2、标签的生成
为了用输入图像I和对应的ground truth训练简单,我们为RPN、Fast R-CNN和mask分支生成目标。一般来说,ground truth包括![]() 和
和![]()
![]() ,这里
,这里![]() 是一个多边形,表示文本区域的位置,
是一个多边形,表示文本区域的位置,![]() 分别是字符的类别和位置。值得注意的是,在我们的方法中不是对所有训练样本都是必须的。
分别是字符的类别和位置。值得注意的是,在我们的方法中不是对所有训练样本都是必须的。
我们首先将多边形转换为水平最小外接矩形。然后根据【8、40、32】(Fast R-CNN 、Faster R-CNN、RPN)为RPN和Fast R-CNN生成目标。对于mask分支,用ground truth需要生成两种目标map,C(可能不存在)和RPN生成的候选框一样:一个用于文本实例分割的全局map和一个用于字符语义分割的字符map。给定一个正的候选框r,我们首先用【8、40、32】中的匹配机制获得最匹配的水平矩形。字符的对应得多边形也可以进一步获得。接下来,匹配得多边形和字符边界框平移,resize来对齐proposal和H*W得目标map,如下边公式:
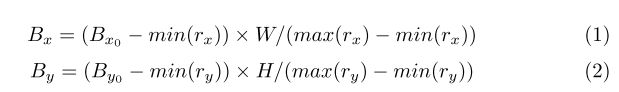
这里![]() 是多边形和所有字符边界框更新后和原始得顶点。
是多边形和所有字符边界框更新后和原始得顶点。![]() 是候选框r得顶点。
是候选框r得顶点。
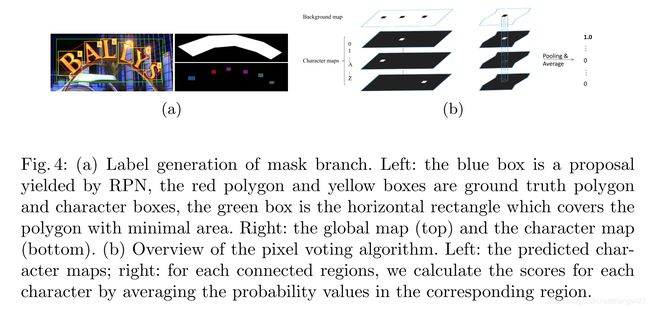
这之后,可以通过在初始为0的mask上画标准多边形,用1填充多边形区域,生成目标全局map。字符map生成如图4a所示。我们首先收缩所有的字符边界框,通过固定它们的中心点,将边缩短为原来的四分之一。然后,在收缩后字符边界框里边的像素值设为它们对应的类别索引值,那些在收缩字符边界框外边的设为0。如果没有字符边界框标注,则所有值设为-1。
3.3、优化
如在3.1部分讨论的,我们的模型包括多个任务,我们自然的定义一个多任务loss函数:
![]()
这里![]() 是RPN和Fast R-CNN的loss函数,与【40】和【8】中的等价。Mask loss
是RPN和Fast R-CNN的loss函数,与【40】和【8】中的等价。Mask loss ![]() 包括全局文本实例分割loss
包括全局文本实例分割loss ![]() 和字符分割loss
和字符分割loss ![]()
![]()
这里![]() 是一个平均二值交叉熵loss,
是一个平均二值交叉熵loss,![]() 是一个带权值得空间soft-max loss。在本文工作中,
是一个带权值得空间soft-max loss。在本文工作中,![]() 根据经验设置为1.0
根据经验设置为1.0
Text instance segmentation loss 文本实例分割任务得输出是一个单一得map。N为全局map中得像素点数,![]() 是像素标签
是像素标签![]() ,
,![]() 是输出像素,我们定义
是输出像素,我们定义![]() 如下:
如下:

这里S(x)是一个sigmoid函数。
Character segmentation loss 字符分割得输出包括37个map,对应37类(36类字符和背景类)。T为类别数,N是每个map中得像素点数。输出Map X可以看作是N*T得矩阵。以这种形式,权值空间soft-max loss可以定义为如下:
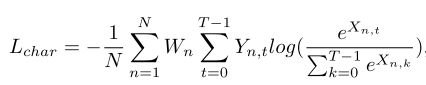
这里Y是X对应得ground truth。权重W用于平衡正样本(字符类)和背景类得损失值。背景像素得数量为![]() ,背景类得索引值为0,权值可以计算如下:
,背景类得索引值为0,权值可以计算如下:

注意在推理时,sigmoid函数和soft-max函数分别用于生成全局map和字符分割map。
3.4、Inference
不同于训练过程mask分支得输入RoIs来自RPN,在推理阶段,我们用Fast R-CNN的输出作为proposals来生成预测全局map和字符map,因为Fast R-CNN的输出更准确。
明确地,推理过程如下:首先,输入一张测试图片,我们获得如【40】那样Fast R-CNN的输出,用NMS过滤冗余候选框;然后,保留的候选框送入到mask分支生成global maps 和character maps;最后,通过在global map上直接计算文本区域的轮廓来获得预测多边形,用我们提出的像素投票算法在character map上生成字符序列。
Pixel Voting 我们用我们提出的像素投票算法将预测的字符map解码为字符序列。我们首先二值化背景map,值是从0到255,阈值为192.然后我们根据在二值化map中的连接区域获得所有字符区域。我们针对所有字符map计算每个区域的均值。这个值可以看作是区域字符类别概率。具有最大均值的字符类分配给该区域。这之后,我们根据英文的书写习惯将所有字符从左至右组合起来。
Weighted Edit Distance Edit 编辑距离可以用一个给定的词典找预测序列最匹配的单词。但是,可能同时有很多个单词匹配最小编辑距离,算法不能决定哪个是最好的。上边提到的问题的主要原因是在原始编辑距离算法中的所有操作(删除、插入、代替)都很相同的成本,实际是不合理的。
受【51】启发,我们提出了权值编辑距离算法。如图5所示,不同于编辑距离,不同的操作对应相同的成本,我们提出的权值编辑距离的代价依赖于通过像素投票生成的字符概率![]() 。数学上,两个字符串a和b之间的权值编辑距离,它们的长度分别是|a|和|b|可以用
。数学上,两个字符串a和b之间的权值编辑距离,它们的长度分别是|a|和|b|可以用![]() 描述,这里
描述,这里
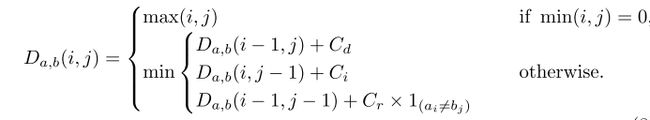
这里![]() 是指示函数,当
是指示函数,当![]() 时等于0,否则为1;
时等于0,否则为1;![]() 是a的第i个字符和b的第j个字符之间的距离;
是a的第i个字符和b的第j个字符之间的距离;![]() 分别是删除、出入和替换的成本。相比之下,这些成本在标准编辑距离中都设为1。
分别是删除、出入和替换的成本。相比之下,这些成本在标准编辑距离中都设为1。

4、实验
为了验证提出算法的有效性,我们进行了实验,在三个公开数据集上和其他最优的算法进行对比:一个水平方向的文本集ICDAR2013,一个多方向文本集ICDAR2015和一个弯曲文本集合Total-Text。
4.1、数据集
SynthText 是【12】中提出的人造数据集,包括80k张图片。在这个数据集中的大多数文本实例是多方向的,并且用旋转边界框标注了单词和字符级别,和文本序列一样。
ICDAR2013是在ICDAR 2013 Robust Reading Competition的挑战2中提出的数据集,比赛主要是自然场景图片中的水平文本检测和识别。
ICDAR2015是在ICDAR 2015 Robust Reading Competition的挑战4中提出的。和关注特定场景的聚焦文本的ICDAR2013相比,ICDAR2015更关心偶然场景中的文本检测和识别。所有的训练图片都是用单词级别的四边形标注的,同时有对应的文本。值得注意的是,在我们的训练阶段只用到单词的定位标注信息。
Total-Text是在【4】中提出的一个复杂场景文本数据集。除了水平文本和多方向文本,Total-Text也包括了大量的弯曲文本。Total-Text包括1255张训练图片和300张测试图片。所有的图片是用多边形标注的以及单词级别的文本。值得注意的是,我们在训练阶段只用了定位标注。
4.2、实现细节
Training 不同于之前的用两个独立的模型(检测器和识别器)或交替训练策略的文本spotting方法,我们模型的所有子网络可以同时进行端对端的训练。整个训练过程包括两个阶段:在SynthText上的预训练和在真实世界数据上的微调。
在预训练阶段,我们将mini-batch设为8,所有输入图像的短边resize到800,同时保持图像的纵横比。RPN和Fast R-CNN的batch size设为每张图256和512,同时正负样本比为1:3。Mask分支的batch size为16。
在微调阶段,由于缺少真实样本,采用了数据增强和多尺度训练策略。明确的,对于数据增强,我们在一定的角度范围内[-15°,15°]随机旋转输入图片。一些其他的增强tricks,如随机修改色度、亮度、对比度,也是根据【33】SSD中的使用的。对于多尺度训练,输入图像的短边随机resize到三个尺度(600,800,1000)。此外,根据【27】,额外的针对字符检测的来自【56】的1162张图像也作为训练样本。图像的mini-batch保持为8,在每个mini-batch中,对于SynthText, ICDAR2013, ICDAR2015, Total-Text和额外的图像,这些不同数据集的样本比例设为4:1:1:1:1。RPN和Fast R-CNN的batch size保持和预训练阶段一致,mask分支的在微调时设为64。
我们用SGD优化我们的模型,权值衰减为0.0001以及momentum为0.9。在预训练阶段,我们训练模型170k次迭代,初始学习率为0.005。然后在120k次迭代时学习率衰减到十分之一。在微调阶段,初始学习率为0.001,然后在40次迭代时减少到0.0001.微调过程在80k次迭代终止。
Inference 在推理阶段,输入图像的尺度依赖不同的数据集。NMS后,1000个候选框送到Fast R-CNN中。错误预警和冗余候选框分别被Fast R-CNN和NMS过滤。保留下来的候选框输入到mask分支来生成全局文本map和字符map。最后,文本实例边界框和序列用预测map生成。
我们在Caffe2中实现我们的模型,在正规的工作平台Nvidia Titan Xp GPUs进行所有的实验。模型可以并行训练,在单一的GPU上评估。