陆金所 CAT 优化实践
1 背景
CAT 介绍
CAT (Central Application Tracking)是一个实时监控系统,由美团点评开发并开源,定位于后端应用监控。应用集成客户端的方式上报中间件和业务数据,支持 Transaction、Event 和 Heartbeat 等数据类型 Metrics 报表,也支持调用链路 Trace,对于发现和定位应用问题有很大帮助。
CAT 服务端也可以认为是一个 Lamda 架构的报表系统,通过汇聚客户端上报的原始消息 MessageTree,实时计算出 Transaction、Event、Problem、heartbeat 等报表,保存在内存中;历史报表序列化后保存到本地并上传到 DB 存储,原始上报数据压缩和建立索引后上传至 hdfs。
陆金所的后端应用监控也主要基于 CAT, 是在前几年的一个版本上做二次开发,增加了新的报表。各类架构中间件大量使用 CAT 埋点,并一直在丰富各类场景,在各类问题发现和问题定位发挥了很大作用。
下图是应用的 Transaction 报表,集成了多个中间件打点:

下图是某一个 MessageTree,用户通过报表中 Sample 或者通过额外的 ES 索引等搜索到某个应用的 MessageTree,trace 到具体调用事件

遭遇性能问题
由于业务扩大,应用数量剧增,生产环境的机器数从半年前的 6000+ 增加到 10000+;另外新版本中间件增加了埋点量,随着应用升级,单个应用实例上传的 CAT 数据也在增加。
在 19 年 12 月份, 发现会出现偶尔某些 CAT 实例无响应的问题。由于当时手上有更紧急的问题处理,这些偶尔的崩溃往往通过重启来解决。直到 20 年 1 月份,开发同学开始抱怨 CAT 界面响应慢,“重启大法” 不再管用了,往往上个小时刚刚重启,下个小时就又挂了。
具体表现
生产上的 CAT 用的都是物理机, 配置是志强物理核心 E5 双路 CPU(CPU 8*2,超线程 32 核), 128G 内存, OS redhat 6.5。高峰时的 CAT 的 context switch 相当高,达到 120 万 / 秒, 系统负载偶尔到 20 以上,一次较大的 Full GC 往往耗时 3-5 秒;一次长时间的 GC 就可能造成 CAT 的端口无响应,只有重启才能解决。
临时治理
-
GC 方式从 CMS 改到了 G1,并调大了 heap 到 80G
-
宕机的实例总是那么几台,这是负载不均衡造成的,因此我们修改客户端上报数据的路由规则让负载更加均衡
-
申请紧急扩容,无奈年末硬件资源和人员都非常紧张,远水解决不了近渴
生产上的应用集群还在扩大,明年还有更多项目需要上线,硬件扩容不仅增加硬件成本,也会增加运维成本;直接 提升性能应该是最好的方案。
测试环境 CAT 也存在类似的容量问题, 我们有 3 台物理机来跑 CAT,但我们的测试环境一共有 15000 个应用实例。之前尝试过应用开启 CAT,但导致 CAT 崩溃,当前的策略是部分环境和应用开启 CAT 打点的方式,是能提供了部分的监控能力,但也对开发测试人员造成了不小的困扰。
对 CAT 做性能优化,一方面能解决生产容量不足的问题,另一方面也能协助规划测试环境的集群容量,大幅提升开发测试效率。
优化准备
性能优化不是没有方向的,其实我们在 2018 年就观察到 CAT 在业务高峰时刻的上下文切换特别高(>1mil/s。在 19 年的 Qcon 会议上,携程的梁锦华介绍了他们对 CAT 的性能优化工作, 服务端的优化集中在改进线程模型来降低上下文切换,改进内存模型来降低 GC。所以我们的优化也要覆盖这两个方向,另外,我们也要看下在 JVM、OS 配置层面能做哪些改进。
线程模型优化
目的是降低上下文切换带来的开销;
我们来看下什么是上下文切换,我们都知道现代 OS 基本是多任务的,CPU 资源在 OS 在不同的任务(线程)需求之间切换分配。为了确保正确性,每一次切换 OS 都需要保存上一次线程的运行状态,并加载下一个线程的状态,这些状态往往涉及 CPU 上的多种寄存器;另外,在切换到下一个的线程之后,还会造成内存访问效率的损失,这主要是不同线程运行时需要访问的数据不同,由此带来的多级缓存命中率下降而降低运行效率。
一次上下文切换的直接开销在 1-5ns 级别,而带来的间接开销则可能到 1us 到数个 ms 之间,有兴趣的同学可以参考这两篇文章: Quantifying The Cost of Context Switch 、 Measuring context switching and memory overheads for Linux threads
内存优化
CAT 作为 APM 应用,每秒摄入的数据在几十到一百多 MB 级别,数据经过反序列化之后,还需要对内存报表做大量的更新操作,这个过程会创建特别多的临时对象,会造成频繁的 Young GC。CAT 内存中维护了当前小时的报表,每一个小时中中,常驻内存随着时间推移逐渐增大,造成可用内存减少,频繁触发 Full GC。
JVM/OS/ 网络设置优化
JVM 已经发布到版本 11,新版本带来了一部分免费的性能提升, 另外 GC 的方式和参数也可以调整。开启 OS 内存大页和调整网络参数等在理论上也能带来性能提升。
核心指标
作为一个实时数据摄入的报表系统,我们很快就确定了几个核心的性能指标:
-
服务端稳定性: 功能核心功能正常工作,服务端是否有 OOM、无响应甚至进程崩溃现象
-
服务端负载: 操作系统系统负载
-
摄入数据速率:主要考察单位时间(1 小时)消费消息数量和数据大小
-
服务端消息丢失量:因为来不及处理而丢弃的消息数量
-
客户端失败消息数量:客户端由于发送速率低于生产速率造成的消息丢弃量
2 第一轮优化
下图描述了 CAT 的消息处理和线程模型,Netty Worker 线程生成 MessageTree 后,offer 到每个 Analyzer 专有队列(Blocking Queue)中,由 Analyzer 线程从队列中拉去后处理并生成对应的内存报表。
不难理解这里的设计初衷是让每个 Analyzer 独立使用其队列,实现了 Analyzer 处理的隔离,慢的 Analyer 不会影响那些快的 Analzyer。

对于某些重要且计算量较大的 Analyzer(例如图中 Transaction Analyzer),使用了多个队列,并根据客户端应用名的 hash 来均衡多个队列任务;CAT 内部自建报表合并机制来合并多份报表。
如果某一个 Analyzer 的队列满了导致无法推送,Netty 线程则会直接丢弃该消息,并统计丢弃次数。
下面的代码描述了插入消息队列的过程:
public void distribute(MessageTree tree) {
String domain = tree.getDomain(); // domain 就是上传消息的应用名
for(Entry> entry: m_tasks.entrySet())
{
List tasks = entry.getValue(); // PeriodTask 封装了消息队列
int index = 0;
int length = tasks.size(); // 多个 Analyzer 队列
if (length > 1) {
index = Math.abs(domain.hashCode()) % length;
}
PeriodTask task = tasks.get(index);
if(!task.enqueue(tree)) {
// 记录的消息丢失
}
}
} Analyzer 拉取并消费消息的代码如下:
while(true)
// 无限循环拉取数据,最大 5ms 超时
MessageTree message = m_queue.poll(5, TimeUnit.MILLISECONDS);
if(message != null) {
process(message)
}
}现在一共有 22 个 Analyzer,略微有点多,我们也不能删除现有的 Analyzer,因为不少系统已经依赖 CAT 的各类报表来协助监控。
通过线下 profiling 并结合研究代码,我们发现:
-
队列的 offer 和 poll 占用了超过 7% 的 CPU 处理时间
-
从线程 dump 来看,Analyzer 线程经常处于 LockSupport.parkNanos 调用上
-
由于部分 Analyzer 有多个线程,Analyzer 线程总数量约 30 个,其线程 CPU 占用又不太高 (<30%)
-
不同类型的 Analyzer 只会处理满足特定条件的 MessageTree,但是 Netty Worker 线程在做 queue.offer 动作时没有判断 MessageTree 能否被该 Analyzer 处理,Analyzer 获取到部分 MessageTree 之后又丢弃
回到系统设计模式上来, 一组线程生成 MessageTree,并采用 BlockingQueue 发送到另一组线程来处理,这是典型的消息传递场景。提到跨线程的消息传递,我们不能不提到大名鼎鼎的 Disruptor 的 RingBuffer 模型。
Disruptor 框架是 LMAX Exchange 开发的高性能队列模型,该框架充分利用了 Java 语言中的 volatile 语义,创新性地使用了 RingBuffer 数据结构,实现了在线程之间快速消息传递,支持批量消费。吞吐量和延时性能都高于 Java 标准库中的 BlockingQueue,其性能关系是:
Disruptor > ArrayBlockingQueue > LinkedBlockingQueue
由于篇幅关系,我们就不在这里详细介绍 Disruptor 内部原理了,有兴趣的小伙伴请参考 Disruptor 介绍。
线程模型尝试和调整
MessageTree 做预过滤是必须要做的,这部分很快做完了,但在线程模型的改动上我们经过了几次尝试:
尝试一
考虑到 Disruptor 做线程间的消息传递效率,我们将 BlockingQueue 简单替换成了 Disruptor 实现。效果不是很明显,总体的 CPU 使用并没有下降多少。
由于 Disruptor 需要 Event 对象放入 RingBuffer,封装 MessageTree 的类定义如下:
class MessageTreeEvent {
MessageTree message;
} 尝试二
为降低 Analyzer 线程数, 我们想到将多个 Analyzer 线程合并,在 Disruptor 框架下需使用同一个 RingBuffer。于是我们将一个 MessageTree 映射到多个 MessageTreeEvent,并通过1个全局的的 RingBuffer,分发给一个线程池来处理。考虑到 Ringbuffer 中 MessageTreeEvent 数量增加,我们将 RingBuffer 大小调整到 262144 (1<<18)
新的 MessageTreeEvent 定位如下:
class MessageTreeEvent {
MessageTree message;
String analyzerId;
}如果 22 个 Analyzer 都采用这个方法,并假设 MessageTree 速率为每秒 5 万,那么最大就有 22 * 5w/s = 110w/s 速率的消息需要通过 Ringbuffer。这个数字乍一看非常大,但如果对照性能 Disruptor 测试结果, 这个速率对于 Disruptor 框架来说压力不大。

我们挑选了大概 10 个 Analyzer 加入这个大的 RingBuffer 来处理,但无论如何如何增大 buffer 消息丢弃情况还是有点多,特别是较为重要的 Transaction/Problem 等 Analyzer 的消息。
尝试三
考虑到不同的 Analyzer 重要程度不同,我们的尽量保证核心 Analyzer 能正常工作,那些不太重要的 Analyzer 丢一点消息是可以接受的。于是我们给 Analyzer 引入了优先级概念,
enum AnalyzerLevel {
HIGH(1),
MID(GLOBAL_REPORT_QUEUE_SIZE/16),
LOW(GLOBAL_REPORT_QUEUE_SIZE/4);
public final int requiredCapacity;
AnalyzerLevel(int requiredCapacity) {
this.requiredCapacity=requirecapacity;
}
}下面是往 RingBuffer 插入数据的代码, 也体现了 disruptor 的优点,hasAvailableCapacity 这个方法与 BlockingQueue 的 size 相比,其内部实现是无锁的。
RingBuffer ringBuffer = disruptor.getRingBuffer();
if(ringBuffer.hasAvailableCapacity(m_analyzer.getLevel().requiredCapacity)) {
long seq=ringBuffer.next();
try {
// 准备 MessageTreeEvent 对象
MessageTreeEvent event = ringBuffer.get(sequence);
event.message = messageTree;
event.analyzerName = m_analyzerName;
} finally {
ringBuffer.publish(seq) ;
}
} else {
// 丢弃并记录
} 我们又引入了分组的概念,将 Analyzer 分为 2 组,每一组使用一个 RingBuffer,每一个 RingBuffer 使用 2 个线程来消费。CAT 一共 22 个 Analyzer,我们将 15 个 Analyzer 改造到了新的线程模型 。
Disruptor 消费和启动代码如下:
// int threadsPerRingBuffer = 2
WorkHandler [] handlers = new WorkHanlder[threadsPerRingBuffer];
for(int index = 0; index < threadsPerRingBuffer; index ++) {
handlers[index] = createHanlder(index); // 创建多个消费线程对等
}
disruptor.handleEventWithWokerPool(handlers); // 设置 disruptor 的消费者
disruptor.start(); // 启动
private WorkHanlder createHandler(int threadIdx) {
return WorkerHanlder () {
public void onEvent(MessageTreeEvent event) {
String analyzerName = event.analyzerName;
getAnalyzer(threadIdx).process(event.message);
}
};
} 另外, 有了之前合并线程成功的经验, 在仔细检查代码时和检查线程栈时,发现 Netty 的 worker 线程数为 24, 确实有点多。我们逐步降低,测试表明 Netty work 线程数为 2 时仍然一切正常,从 top -H 的输出来看,在 100MB/ 秒的网络摄入流量下,Netty Worker 线程的 CPU 也就在 70% 左右,未见客户端发送失败的情况。
最终的线程模型如下:
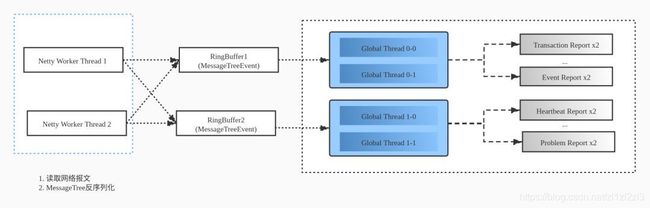
JVM 设置改动
在 JVM 和 GC 方式的选择上,我们选用了 open Jdk 11 和 G1 的方式,在测试环境,这个组合的运行稳定,GC 的延时较低, CAT 的页面响应也比较快。
优化工作做了 2 周, 快到了过年的时间,我们先找了 2 台机器验证,验证通过后更新到了所有实例。
改造效果
我们将测试环境 4500 台机器左右的流量导入到一台机器, 在修改前,这台 CAT 机器刚起来 1 分钟后就会陷入无响应状态。
改造后测试环境的这台服务器顺利跑了起来, 在小时消息量 0.94 亿,消息大小 210G 情况下 “top -H” 输出如下, 可以看到 Netty work 线程 (图中 epollEventLoopG)的占用不高,4 个全局的 Analyzer 线程 (图中 Cat-Global 开头线程) 的占用也不太高,无消息丢失。


在生产环境中也找出一台机器,通过配置路由规则,让其承载较大流量,这台机器在不同负载情况下表现如下:
 注:我们区分了核心消息(优先级为 High 的 Analyzer)与非核心消息丢失。
注:我们区分了核心消息(优先级为 High 的 Analyzer)与非核心消息丢失。
G1GC 在生产环境表现稳定,一次 young G1GC 平均耗时约 200ms,未见 Old GC。
上下文切换下降了一半以上,CPU 负载也下来了很多 ,没有出现超过负载 20+ 的情况,应该可以安稳过年了!
未解决的问题
春节前的一轮优化主要覆盖线程模型优化与 JVM 设定, 内存优化还没做。
生产环境中 CAT 在日常的高峰流量中 CPU 负载依然超过 10,并随着小时报表在内存中积累,10 分钟后的 CPU 负载明显攀升 (如下图)

结合测试环境中 CAT 进程的堆 dump,"jmap -histo $pid" 的输出的分析中,我们发现还存在如下几个问题:
-
CPU 使用率还是有点高,承载较大流量是出现核心消息丢失
-
上下文切换较高,平时负载在 40 万 / 秒, 高峰时间到 50 多万 / 秒
-
临时对象较多,例如 SimpleDateFormat/DecimalFormat 等对象
-
LinkedHashMap 中的内存使用效率较低
-
驻留内存中简单对象数量太多
详细优化过程先从内存优化部分说起
3 内存优化
有效内存使用率概念
关于内存使用效率,和大家分享下 Java 中对象的大小概念
-
Shallow Size: 包含当前对象 Header 和对象直接拥有的内部数据,以下面的对象 s 为例,除了对象 Header 之外,包含 1 个数组引用、1 个 Map 引用、1 个 double 和 1 个 int, 其内部数据大小是 8*3+4 = 28 byte
在 64 位 JVM 未开启指针压缩情况下加上对象 Header 16 byte 并保持 8 byte 的对齐,最终 Shallow Size 大小 28 + 16 + 4 = 48 byte
class Sample {
int[] intArray; // reference size 8
Map map; // reference size 8
double doubleValue; // double size 8
int intValue; // int size 4
}
Sample s = new Sample(); 希望了解更多 java 对象内存布局的朋友可以使用 open jdk jol 工具 ,下面是利用 jol 打印上述对象 layout 的代码
import org.openjdk.jol.info.ClassLayout;
import org.openjdk.jol.vm.VM;
public class ObjectLayoutMain {
public static void main(String[] args) throws Exception {
System.out.println(VM.current().details());
System.out.println(ClassLayout.parseClass(Sample.class).toPrintable());
}
}以下是使用 “-Xms40g -Xmx40g” 的 vm 参数在 64 位 jvm11 下的输出
# Running 64-bit HotSpot VM.
# Objects are 8 bytes aligned.
# Field sizes by type: 8, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]
# Array element sizes: 8, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]
org.jacky.playground.jol.Sample object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 16 (object header) N/A
16 8 double Sample.doubleValue N/A
24 4 int Sample.intValue N/A
28 4 (alignment/padding gap)
32 8 int[] Sample.intArray N/A
40 8 java.util.Map Sample.map N/A
Instance size: 48 bytes注: 设置堆内存大于 32G 会关闭引用压缩 ,兴趣的同学可以自己跑一下看应用压缩或者是 32 位 JVM 下的输出。
-
Retain Size: 内存中的对象存在引用关系,消除循环后可以认为是一个个对象树。对象的 Retain Size 是该对象对应的对象树的大小。与对象的 Shallow Size 相比,Retain Size 是一个相对动态的值,随着其下层对象具体值变化而变化。内存有效使用率定义如下:
内存使用率 = 实际数据占用大小 / Retain Size
更多内存效率理论请参考:Building Memory-efficient Java Applications: Practices and Challenges
优化实践
现状
从 CAT 的 heap dump 中我们看到最大的对象主要是当前小时的各种 Report 对象, 这些 Report 大量使用了多层级的 Map 结构,如下图 (图中的数字是经验估计数量)。可以看到 Map 对象非常多, 特别是层次往下的那些对象。
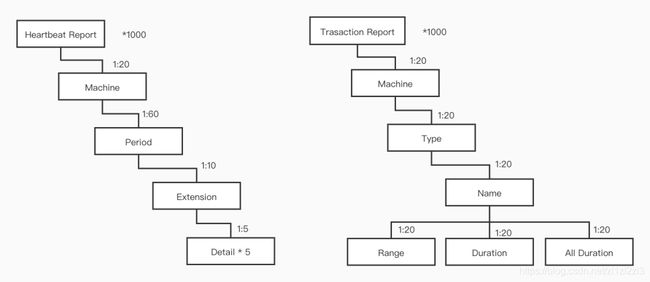
现有代码采用 java 标准库中的 LinkedHashMap 来表示这些层次结构,这也就产生了大量 LinkedHashMap 以及子对象 LinkedhashMap$Entry,从下面堆 dump 的内存文件分析看到这几个 package 的对象在内存占用按照类型排行上非常靠前:
-
heartbeat.model.event.*
-
transaction.model.event.*
-
event.model.entity.*
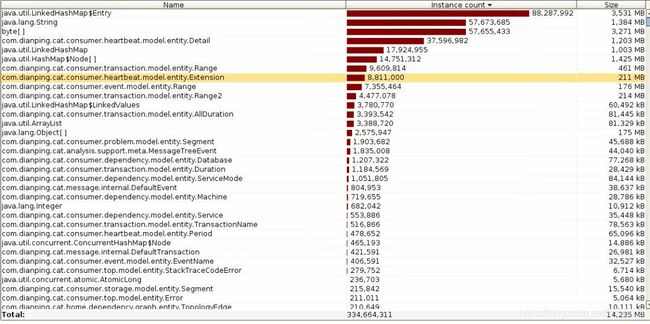 内存使用概览
内存使用概览
开放地址 HashMap 实现
我们发现对于那些靠近叶子节点的报表对象,采用 LinkedHashMap 在大多数时候有点多余,因为不需要记录插入顺序,可以简化成 HashMap,下面是这两者 Entry/Node 节点类的定义比较:
//java.util.Hash
static class Node implements Map.Entry {
final int hash;
final K key;
V value;
Node next;
}
//java.util.LinkedHashMap
static class Entry extends HashMap.Node {
Entry before, after; // 额外的 before & after 引用
Entry(int hash, K key, V value, Node next) {
super(hash, key, value, next);
}
} 是不是还能进一步优化呢?答案是可以,而且改动很小
很多 Java 技术栈的同学对标准库中利用链表法实现的 HashMap 比较熟悉, 但大学学过《数据结构》课程的同学可能还记得另一种 Hash 的实现 开放地址 Hash 。与链表法开一个链表来解决冲突的方式不同, 开放地址 Map 通过在线性表中重新计算一个新位置来解决。
实测大小对比:
下述测试代码生成一个包含大小为 size 的数组,其保存大小从 0 到 size-1 的 HashMap
import org.agrona.collections.Int2ObjectHashMap;
import java.util.*
private static Map[] populate(int size, boolean useOpenMap) {
List> result = new ArrayList<>();
for (int i = 1; i <= size; i++) {
Map m = useOpenMap ? new Int2ObjectHashMap<>() : new LinkedHashMap<>();
for (int j = 0; j < i; j++) {
m.put(j, new Range());
}
result.add(m);
}
return result.toArray(new Map[]{});
}
public static class Range { // retain size=56
int id = 0;
int count = 0;
int fails = 1;
double sum = 1.0;
double avg = 1.0;
double max = 1;
} 运行结果整理如下, 可以看到切换到 Int2ObjectHashMap 的实现就能轻松节省 30% 以上内存,如果值类型的 shallow 更小,节省还会更多。

值得说明的是:
-
在 CPU 性能测试中,开放地址的 Map 的 get/put 都比 HashMap 性能略差,但绝对值差距很小
-
开放地址的 Map 在删除时需要在将这个位置 mark 成已删除,会造成空间浪费,但在 CAT 计算中无删除操作
对象消除
在上一个图中,可以注意到 heartbeat.model.event.Detail 对象数量非常之多,其占用内存就超过 1G!
对应到业务逻辑,每一个 Detail 都是描述应用 heartbeat 的某一个属性,例如 "SystenLoad"、“PhysicalFreeMemory”、"GC Count" 等,这些 Details 存在如下几个特点:
-
Key 大量重复, Key 去重后数量很少,同一个应用的 CAT 客户端在不同时间、不同实例的 heartbeat 中的 Key 都一样;还有部分 Key 是 CAT 客户端自带的,这部分 Key 对所有应用都一样
-
Detail 的定义非常简单,m_label 总是为 null,可以直接去掉
class Detail {
String m_id;
double m_value;
String m_label; // 总为 null, 可以消除
}-
Detail 对象保存在 Extension 对象中,其中的 key 与 value 中 id 值相同
class Extension {
Map m_detais = new LinkedHashMap<>();
} 从上面的几个特点,我们可以将这里的 key 对象映射成 int,一个 detail 对象的有效数据就是一个 int 和一个 double 对象,总的有效大小为 12byte。
我们来找两个例子来计算下内存使用效率:
这是一个非典型场景, m_details 中 key 数量为 122,比较多

我们来计算上面 m_details hashmap 的内存使用效率:
-
Retained size 17632
-
有效大小 122 * 12
-
内存有效率 122 * 12 / 17632 = 8.3%
下面这个 m_details,key 数量较小,内存使用效率: (12 *2)/472=5.1%

在使用 eclipse collection 的 LongDoubleMap 替代后,上述两例的使用效率分别提高到 46.1 和 15.8%。
其他内存优化
考虑到线程安全问题,SimpleDateFormat 和 DecimalFormat 等对象在使用时创建新实例,使用线程安全的实现来代替即可。
4 继续线程优化
为了可以更方便地调整全局线程 /ringBuffer,并始终保持不同线程之间负载和优先级的均衡,我们引入了 Analyzer 动态分组。
Analyzer 动态分组
我们对大约 20 个 Analyzer 按照重要正度和计算复杂度综合考虑排序,用于 Analyzer 分组。

动态分组保证那些计算量大且优先级又高的 Analyzer 不集中竞争计算资源, 实现规则如下
effectiveRingBufferIndex = analyzer.getGlobalIndex() % ringbufferCount 我们将剩下的几个 Analyzer 合并到了全局线程组,对 Netty Worker 数、全局线程数和每个 RingBuffer 的消费线程数做了配置化。默认开启 2 个 Netty Worker 线程,3 个全局线程 /ringBuffer,考虑到维护多份报表的内存开销较大,每个 RingBuffer 的消费线程数默认设置为 1。优化后的典型的线程配置如下:

另外继续增加了 Ringbuffer 大小到 524288 (2^19) ,当然我们也清楚增加缓存大小有两个坏处:
-
最大处理延时增加,考虑到 CAT 的处理能力,这个影响最大不超过 5 秒,业务上可以接受
-
buffer 增大导致内存使用增加,由于 CAT 进程都是动辄几十 G 的堆,额外的百万个 buffer 对象带来的影响微乎其微
其他优化与尝试
-
对 ConcurrentHashMap 做 null 检查后使用 synchronize 改到使用 ConcurrentMap.computeIfAbsent
CAT 启动或者跨小时的时候会集中创建 bucket,采用 null 检查 + synchronize 的方法会造成集中的线程堵塞
ConcurrentMap m_buckets = new ConcurrentHashMap();
// 改造前
bucket=m_buckets.get(path);
if(bucket == null) {
synchronize(m_buckets) {
bucket= createBucker(); // 慢操作
m_buckets.put(path, bucket);
}
} // 改造后
bucket=m_buckets.computeIfAbsent(path,path -> createBucket());-
缩减 CAT 集群内部请求的线程数量,增加其 buffer 大小,并使用连接池来管理连接
-
增加磁盘写入线程数量和 buffer 来缓解测试环境磁盘写入较慢的问题
-
测试环境 OS 的电源管理从 on-demand 改成 performance 模式,与生产对齐
-
测试环境尝试开启内存大页,效果不太明显,生产环境也需要运维协助配置,暂放弃
5 效果
单机性能
为了验证优化效果,我们对某一台机器又加大了流量,比较了不同负载的表现

注:1.74 亿消息量是人为加大负载,每秒网络流量 114MB(402GB/3600) ,已打满千兆线路。
下图为小时消息量 1.45 亿下的系统表现:

可以看到上下文切换、CPU 的使用率和 GC 都非常平稳,核心消息丢失为 0;非核心消息丢失略高。可考虑增加全局处理线程数到4甚至5来缓解极端负载下的非核心消息丢失。
容量评估
基于最新的单机性能和总的生产数据量,现有生产环境集群还有约 50% 的冗余容量,未来 2 年都无需扩容。
测试环境的 CAT 容量也评估了出来,现有 3 台 CAT 支撑 15000 个测试应用实例有点勉强,正在申请额外 3 台服务器,这样就能支持所有的测试集群,并留有部分冗余。
6 思考
超线程
超线程(Hyper Thread,HT)给 OS 提供了更多的可用核心,但这些核心是毕竟是硬件虚拟出来的,目的是更好地使用 CPU 多余的计算和缓存资源,提供更高的吞吐量。
简单地认为开启 HT 可以免费获得一倍的可用线程并计算能力能翻倍是不可取的,物理核心和虚拟核心会竞争使用计算和缓存资源,在某些情况下甚至会降低吞吐量。
在计算密集的场景下,HT 的虚拟核心是不能计算在可用核心里面的,因为虚拟 CPU 的计算能力有限。这可能也是我们生产环境 CPU 飙到 20 左右就会出现计算能力严重不足,带来端口无响应等问题。
Java 内存使用效率
Java 有很好的面向对象的特性,在书写程序时带来了很多便利,但也带来了运行时刻的内存负担,每个对象都有个很大的 Header,有时 Header 甚至超过了本身数据的大小。
这有两个比较好的解决方案值得期待:
Java 语言支持 struct 类型
Java 语言 struct 类型需求很早就被提了出来,struct 类型和原生类型一样,不属于对象范畴,没有对象 Header 的内存成本。近年放在 valhalla 项目中, 19 年 5 月份发布了原型版,有兴趣的同学可以看下。
java 与原生语言混合编程
Oracle 的 graalvm 项目,支持 Java 语言与其他原生语言混合编程,在 Java 应用的性能瓶颈的部分采用 C 或者 Rust 语言来实现。该项目已经开源,已经取得了一定的进展,可在官网下载社区版的 graalvm 的 JDK。
7 总结
两轮性能优化各耗时 2 周,回顾整个优化过程,我们制定了大体的方向,找到核心的性能指标,大量查找资料,从原理验证做起,并结合线下环境的逐步验证,直到目标达成为止。
在优化过程中,我们也学习了 CAT 本身设计巧妙的地方,例如异步化的实时数据处理、支持水平扩容、高效的序列化 / 反序列化和集群数据路由等。在此感谢美团点评的朋友把这个项目开源出来,让大量的开发者收益。
性能优化是一个综合的话题,并没有什么圣杯,只需在工作中勤摸索、常思考、积极与他人交流并敢于尝试总能有收获。我们把这次优化经历写出来,希望能抛砖引玉,也欢迎各位同行指正。
8 作者介绍
蔡健,陆金所应用架构师。2008 年复旦大学硕士毕业后加入大摩, 2016 年加入陆金所,负责 Java 架构中间件和应用监控;职业理念是专注,并对新技术时刻充满热情。
方超,陆金所应用架构师。十年工作经验。热爱生活和技术。