cuda低占用率下性能优化
转载:http://blog.sina.com.cn/s/blog_70684c2a0100vjhj.html
这两天看到Vasily Volkov牛人的ppt,对如何更有效的使用GPU做通用计算提出了增加线程级并行以外的另一种方法---增加指令级并行,受益匪浅。刚好也没找到中文版本,就翻译过来与大家交流下,有错误请各位牛人指正,所有的实验结果和图片均出自原ppt。请参考《Better Performance at Lower Occupancy》后面两个案例有时间会放上来...
-------------------------------------------------------------------------------------------------
为提升GPU的效率,常用的方法是提升设备占用率(occupancy),包括在每个流处理器上运行更多的线程和为每个线程块设定更多的线程。人们常常认为这是隐藏延迟的唯一方法,但我们的实验结果证明最大化占用率反而可能会降低性能:
大矩阵相乘,单精度浮点(SGEMM)

1024点复数到复数快速傅里叶变换(FFT),单精度浮点:

两个常见谬误:
1. 多线程是GPU上隐藏延迟的唯一方法
2. 共享内存和寄存器一样快
整个报告分成五部分:
1. 使用更少线程隐藏计算延迟
2. 使用更少线程隐藏内存访问延迟
3. 使用更少线程来加速
4. 案例研究:矩阵相乘
5. 案例研究:FFT
1. 使用更少线程隐藏计算延迟
计算的延迟
延迟:执行操作所需时间。一次计算操作需要约20个时钟周期,一次内存访问操作需要400+个时钟周期:

以上代码中计算z时,由于z对x的依赖性,在计算x的延迟期内(约20cycle),该操作无法执行。但y的计算由于没有依赖性,因而可以与x的计算重叠(即在20cycle内执行)。
计算的吞吐量
延迟的概念常常与吞吐量的概念混淆,比如“计算比内存操作快100倍----每个warp(G80)只需花费4个时钟周期,而内存操作要花费400个时钟周期”这句话就是错误的,因为前者是比率,而后者是时间。
吞吐量:每个时钟周期完成多少条指令。
计算:1.3Tflop/s = 480 ops/cycle(指令每周期)(指令为乘加运算)
访问显存:177GB/s ≈ 32 ops/cycle (指令为32位装载)
隐藏延迟:在延迟等待时做其他的操作。这样可以运行更快,但上限为峰值。那么怎样达到峰值呢?
使用里特尔定律(Little’s law),即所需并行度=延迟*吞吐量
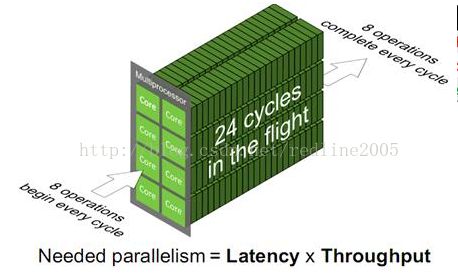
那么当前设备的并行度怎样呢?
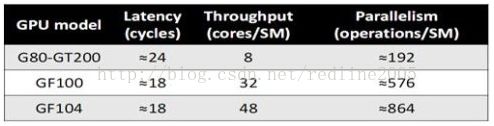
(延迟随指令的不同而变化)
由于指令的延迟固定,如果没有足够的并行度,就不可能达到100%的吞吐量,也就是说没有足够多的运行中指令,那么就存在空闲指令周期。
怎样得到足够的并行度?
线程级并行(TLP):通常做法是使用足够的线程来提供需要的并行度,比如:在G80上每个SM执行192个线程。

指令级并行(ILP):但你同样可以在单个线程内利用指令间的并行性来达到足够的并行度。
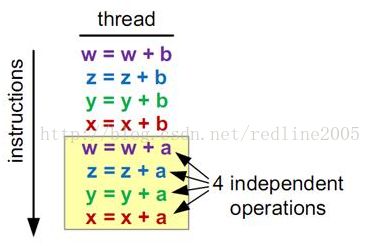
你可以在GPU上同时使用ILP和TLP
这个规则适用于所有可以运行CUDA的GPU。
比如在G80上,如果没有ILP,你可以通过25%的GPU占用率达到100%的峰值;或者,在每个线程中有三条指令可以同时进行的情况下,通过8%的GPU占用率达到峰值。
而在GF104上,如果要达到66%以上的峰值性能,你则必须应用IPL,因为:每个SM中有48个核,单条指令每次广播给16个核。而为了使每个核都有指令执行,单个时钟周期内必须分发3条指令,但事实上每个SM中只有2个warp调度器,无法分发3条指令。所以NV在这里提供了ILP,每个warp在同一指令周期内却可以分发两条以上的指令,这就给我们提供了使每个核都有指令执行的方法。
我们用实验来证明:
1.不用ILP来运行大量计算指令

将N_ITERATIONS设定为一个很大的数,选择合适的UNROLL,并保证a,b,c都存储在寄存器中。执行一个block(即只使用一个SM),选择不同的线程块大小,检测所能达到的性能:
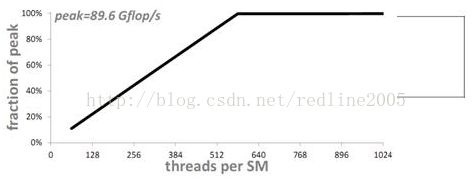
GPU为GTX480,理论峰值为1.3Tflop/s,一个SM就是89.6Gflop/s(1.3T/15, GTX480中有15个SM)
可以看到,如果没有ILP,一个SM上需要576个线程才能达到100%的利用率
2. 引入指令级并行
实验ILP=2时,即每个线程执行2条相互独立的指令,
那么如果使用更多线程是在GPU上隐藏延迟的唯一方法,则我们应该得到相同的性能曲线,事实上:
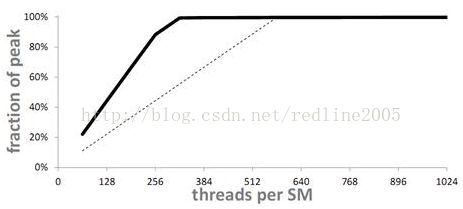
虚线标出的是原本曲线,可以看出:
当ILP=2时,只需要320个线程就能达到100%的利用率
加入更多的指令级并行:
当ILP=3时,每个线程3条独立指令:
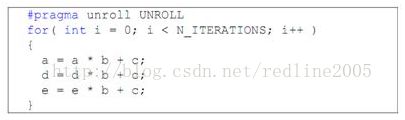
得到的结果是:

即当ILP=3时,只需要256个线程就可以达到100%利用率。
不幸的是,当ILP超过4时,就不会再扩展了(lz:猜想每个warp在一个时钟周期内最多就只能分发4条指令了)
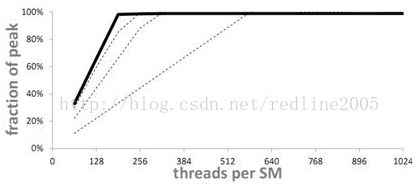
当ILP=4时,需要192个线程就能达到100%的利用率。
总结:可以通过两种方法隐藏计算延迟
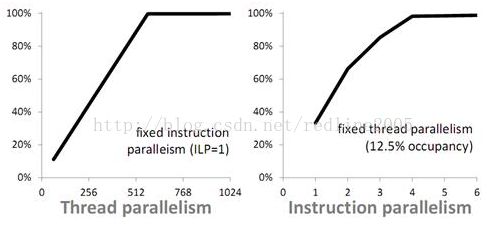
这条同样适用于其他GPU,比如G80架构

谬误:提升占用率是隐藏延迟的唯一方法?错误,提升ILP是另一种方法。
谬误:占用率是衡量GPU利用率的标准?错误,它只是一个影响因素。
谬误:“为完全隐藏计算延迟,流处理器必须在计算能力为1.x的设备上运行至少192个线程,或者在计算能力为2.0的设备上运行384个线程”(出自CUDA Best Practices Guide)。错误,在G80-GT200上通过64个线程,在GF100上通过192个线程同样可以达到目的。
上一部分是用IPL隐藏指令延迟,这一部分是用ILP隐藏显存访问延迟。
----------------------------------------------------------------------
2.使用更少线程隐藏内存访问延迟
隐藏内存访问延迟,使用相同的说明方式,但针对内存操作。
所需并行度 =延迟 * 吞吐量

所以隐藏内存延迟意味着保持100KB的数据读取速率,当然如果kernel是计算限制(compute bound)的,则这个数值可以变小。
那么,多少线程可以达到100KB呢,有多种方法:
1. 使用更多的线程
2. 使用指令级并行(每个线程进行更多次存储访问)
3. 使用位级(bit-level)并行(使用64/128位方式存储访问)
每个线程做更多的工作,则线程数量可以更少:每个线程取回(fetch)4 Byte,需要25000个线程,取回100B,仅需要1000个线程。
经验验证:
每个线程拷贝一个浮点数:

运行多个线程块,通过动态分配共享内存来控制SM占用率。
每个线程拷贝单个浮点数(GTX480)

只能通过最大化占用率来隐藏延迟吗?不,也可以每个线程做更多的并行工作。

注意,线程并不会被存储访问阻塞,它只会因为数据依赖性而阻塞。
每个线程拷贝2个浮点数

虚线部分为原曲线,所以我们可以减少占用率了。

注意,本地数组会尽量分配在寄存器中,以下是每个线程拷贝4个浮点数

可以看到,仅仅25%的占用率就足够了,那么我们究竟能做到什么程度?
以下是拷贝8个浮点数:

每个线程拷贝8个float2型数据,

每个线程拷贝8个float4型数据

只通8%的占用率就达到了87%的pin带宽!
每个线程拷贝14个float4型数据
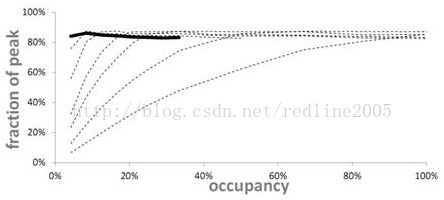
只通过4%的占用率就达到了峰值的84%。
有两种方法来隐藏内存访问开销

谬误:“低占用率常常会影响GPU隐藏内存延迟的能力,从而导致性能下降。”(CUDA Best Practices Guide)。我们刚才看到,仅仅4%的占用率就可以达到峰值的84%,注意这已经超过了cudaMemcpy所能达到的最好性能(71%)。
谬误:“一般来说,需要更多的warps,如果对片下内存的访问指令比例。。。”(CUDA Programming Guide)错,我们刚才看到了,在一个内存访问密集型的kernel中,每个SM仅仅只有4个warps就可以达到87%的内存性能峰值。
前两部分是有关ILP隐藏计算和访存延迟,从而在GPU低占用率的情况下达到高并行度和吞吐率。下一部分是讨论在共享内存(shared memory)和寄存器(register)之间的权衡,作者从吞吐率的角度上说明使用共享内存达不到最好性能,最好降低占用率从而尽可能多的使用寄存器。
----------------------------------------------------------------------------------------------
3.使用更少线程运行更快
使用更少线程意味着每个线程拥有更多的寄存器。

每个线程的寄存器数:
GF100:在100%占用率时有20个,在33%占用率时63个,为3倍。
GT200:在100%占用率时有16个,在12.5%占用率时约有128个,为8倍
那么每个线程有更多的寄存器是不是更好呢?
只有寄存器的速度才能足够达到峰值。考虑这样一个计算: a*b+c:2个flops,12B输入,4B输出,则对于1.3Tflop/s的计算峰值,需要8.1TB/s的带宽,寄存器可以满足这样的要求,我们来看看共享内存(shared memory)能不能达到?
只有 4B*32banks*15SMs*half 1.4GHz = 1.3TB/s
需要的带宽和可以达到的带宽比较:

lz:可以看出共享内存的带宽是全局内存(显存)的7.6倍,而寄存器是共享内存的6倍,至少需要8TB/s的带宽才能让GPU的计算达到峰值,寄存器可以做到(废话,做不到这个计算峰值就根本不存在了)。
谬误:“事实上,对一个warp中的所有线程来说,如果线程间没有bank conflicts,访问共享内存和访问寄存器一样快。”(CUDA Programming Guide)
不,在Fermi架构中,共享内存的带宽比寄存器慢6倍以上。(非Fermi为3倍)
运行更快可能需要更低的占用率:
1. 必须使用寄存器才能接近峰值
2. 不同存储的带宽差距越大,越多的数据就必须从寄存器中读取
3. 而使用越多的寄存器意味着越低的占用率
这常常可以通过每个线程计算更多的输出来完成。
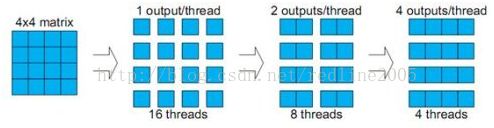
对线程来说,越多的数据存放于寄存器意味着越少次数的共享内存访问。越少的线程,但每个线程做越多的工作,使得低占用率不成问题。
从Tesla到Fermi是一种倒退吗?
共享内存带宽和计算带宽的差距增加了:

使用快速的寄存器会有帮助,但寄存器的数目被严格限制:
G80-GT200: 每个线程最多128个寄存器
Fermi:每个线程最多64个寄存器