TensorFlow 人脸识别项目实战
- 人脸识别问题概述
- 典型人脸相关数据集介绍
- 人脸检测算法介绍
- 人脸识别算法介绍
- 人脸检测工具介绍
- 解析FaceNet人脸识别模型
- 实战FaceNet人脸识别模型
- 测试与可视化分析
1、人脸识别问题概述
人脸识别,特指利用分析比较人脸视觉特征信息进行身份鉴別的计算机技术。广义的人脸识别实际包括构建人脸识别系统的一系列相关技术,包括人脸图像采集、人脸定位、人脸识别预处理、身份确认以及身份査找等;而狭乂的人脸识别特指通过人脸迸行身份确认或者身份査找的技术或系统。
人脸识别是一项热门的计算机技术研究领域,它属于生物特征识别技术,是对生物体(一般特指人)本身 的生物特征来区分生物体个体。生物特征识别技术所硏究的生物特征包括脸、指纹、手掌纹、虹膜、视网 膜、声音(语音)、体形、个人习惯(例如敲击键盘的力度和频率、签字)等,相应的识别技术就有人脸 识别、指纹识别、掌纹识别、虹膜识别、视网膜识别、语音识别(用语音识别可以进行身份识别,也可以 进行语音内容的识别,只有前者属于生物特征识别技术)、体形识别、键盘敲击识别、签字识别等。
人脸识别的技术困难
虽然人脸识别有很多其他识别无法比拟的优点,但是它本身也存在许多困难。人脸识别被认为是生物特征识别领域甚至人工智能领域最困难的硏究课题之一。人脸识别的困难主要是人脸作为生物特征的特点所带来的。人脸在视觉上的特点是
1.不同个体之间的区别不大,所有的人脸的结枃都相似,甚至人脸器官的结构外形都很相似。这样的特点对于利用人脸进行定位是有利的,但是对于利用人脸区分人类个体是不利的。
2.人脸的外形很不稳定,人可以通过脸部的变化产生很多表情,而在不同观察角度,人脸的视觉图像也 相差很大,另外,人脸识别还受光照条件(例如白天和夜晚,室内和室外等)、人脸的很多遮盖物 (例如口罩、墨镜、头发、胡须等)、年龄、拍摄的姿态角度等多方面因素的影响。
人脸识别的经典流程分为三个步骤:
1)人脸检测; 2)人脸对齐; 3)人脸特征表示。
基于传统机器学习的人脸识别一般分为高维人工特征提取(例如:LBP, Gabor等)和降维两个步骤。在深度学习流行之后,我们可以从原始图像空间直接学习判别性的人脸表示实现端到端的人脸识别模型。
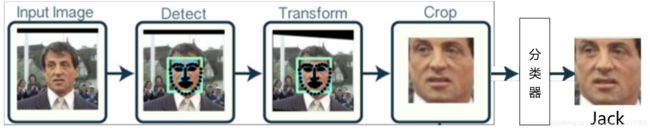
深度学习“引爆”人脸识别
过去几年,深度学习正在彻底改变人脸识别领域。由于GPU的计算效率不断提高,谷歌的研究人员在CPR( Computer Vision and Pattern Recognition)2015上发表了一篇开创性的论文: FaceNet。 FaceNet是一个解决人脸识别和人脸聚类问题的全新深度神经网络架
构,其在LFW( Labeled faces in the wild)人脸识别数据集上十折平均精度达到99.63%同时,它为使用深度学习创建下一代人脸识别系统打下了坚实基础

Schroff, F, Kalenichenko, D and Philbin, J, 2015. Facenet: a unified embedding for face recognition and clustering. In Proceedings of theIEEE conference on computer vision and pattern recognition(pp. 815-823)
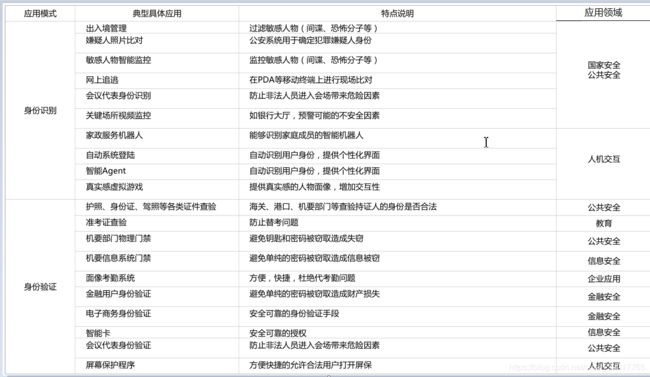
人脸识别应用一安防
人脸识别应用一安检

人脸识别应用一个人相册管理
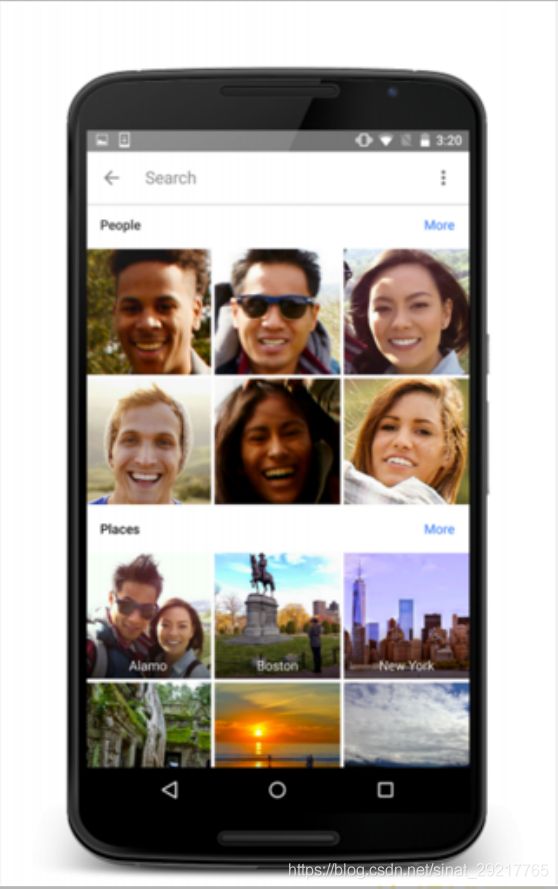
人脸识别应用一支付

人脸识别应用-KYC

2、典型人脸相关数据集介绍
LFW( Labeled Face in the Wild)
2007年以来,LFW数据库成为事实上的真实条件下的人脸识别问题的测试基准。LFW数据集包括来源于因特网的5749人的13233张人脸图像,其中有1680人有两张或以上的图像。
 http://vis-www.cs.umass.edu/lfw/
http://vis-www.cs.umass.edu/lfw/
LFW的标准测试协议包括6000对人脸的十折确认任务,每折包括300对正例和300对反例采用十折平均精度作为性能评价指标。自从LFW发布以来,性能被不断刷新。
2013年之前,主要技术路线为人造或基于学习的局部描述子+测度学习
2014年之后,主要技术路线为深度学习。
- 2014年以来,深度学习+大数据(海量的有标注人脸数据)成为人脸识别领域的主流技术路线,其中两个重要的趋势为:网络变大变深( VGGFacel6层, FaceNet22层);
- 数据量不断增大( Deep Face400万, FaceNet2亿),大数据成为提升人脸识别性能的关键。
Youtube faces db
You Tube faces是一个面部视频数据库,旨在硏究视频中非约束环境下的人脸识别问题。 该数据集包含3,425个视频,1,595个不同的人。所有视频都是从 You Tube下载的。每个主题平均有2.15个视频。剪辑最短的视频为48帧,最长的为6,070帧,视频平均长度为81.3帧。

CASIA-Webface
CASIA- Web Face数据库包含10k+人和约500张图片,用于非约束环境下人脸识别的科学硏究。数据库中的面部图像由中国科学院( CASIA)自动化研究所从互联网上爬取。官方允许该数据库进行教育或非商业用途的免费使用。但由于数据库中的图像可能受版权保护,官方没有在他们的网站上公开发布。如果是研究使用,可以在官方网站上申请访问权限。下图即为申请样式表:
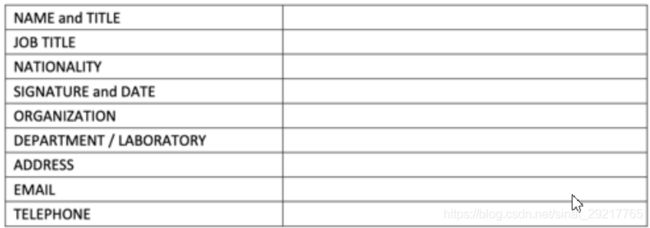 http://www.cbsr.ia.ac.cn/english/casia-webFace/casia-webfAce_AgreEmeNtS.pdf
http://www.cbsr.ia.ac.cn/english/casia-webFace/casia-webfAce_AgreEmeNtS.pdf
人脸识别数据集
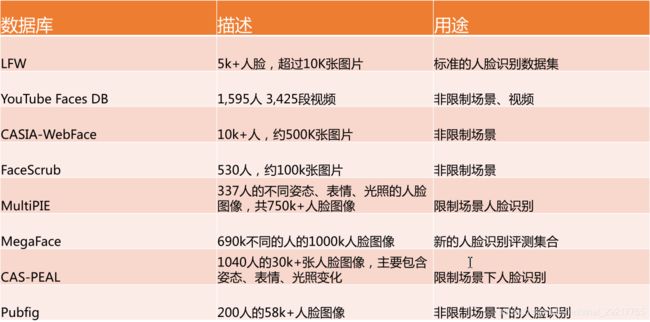
FDDB: Face Detection Data Set and Benchmark
人脸检测数据集和基准测试(FDDB)是一个面部区域数据集,用于硏究非约束环境下人脸检测问题。FDDB从LFW数据集选取了5171张人脸和2845张图片,由马萨诸塞大学( University of Massachusetts, UMASS)维护
 http://vis-www.cs.umass.edu/fddb/index.html
http://vis-www.cs.umass.edu/fddb/index.html
WIDER FACE: A Face Detection Benchmark
WIDER FACE数据集是由汤晓鸥团队发布的人脸检测基准数据集。其从公开数据集WDER中选取了32,203个图像并标记了393,703个面部,其比例、姿势和遮挡度具有高度可变性。数据集共分为61个类。每一类别的训练、验证和测试集比例都是4:1:5。基准测试的评估指标与 PASCAL VOC数据集采用的相同。
 http://shuoyang1213.me/WIDERFACE/
http://shuoyang1213.me/WIDERFACE/
Large-scale CelebFaces Attributes( CelebA) Dataset CelebFaces Attributes Dataset( Celeb)是一个大型人脸属性数据集,拥有超过10,177个名人的202,599张面部图像,每张图像都有5个特征点标注和40个属性注释。同时,此数据集中的图像还覆盖了巨大的姿势变化和杂乱背景。
 http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html
http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html
人脸检测数据集
3.人脸检测算法介绍
人脸检测算法简介
自动人脸检测技术是所有人脸影像分析衍生应用的基础,这些扩展应用细分有人脸识别、人脸验证、人脸跟踪、人脸属性识别,人脸行为分析、个人相册管理、机器人人机交互、社交平台的应用等。
人脸检测的目标是找出图像中所有的人脸对应的位置,算法的输出是人脸外接矩形在图像中的坐标,可能还包括姿态如倾斜角度等信息。虽然人脸的结构是确定的,由眉毛、眼睛、鼻子和嘴等部位组成,近似是一个刚体,但由于姿态和表情的变化,不同人的外观差异,光照,遮挡的影响,准确的检测处于各种条件下的人脸是一件相对困难的事情。
经典人脸检测算法流程
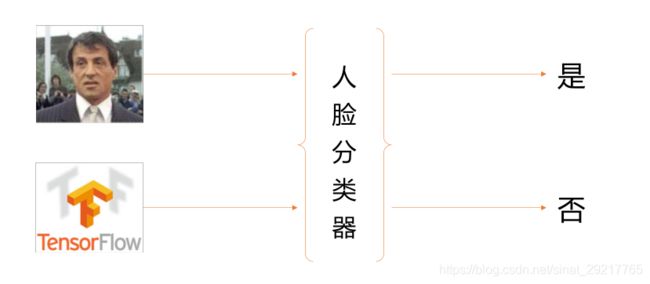
用大量的人脸和非人脸样本图像进行训陈练,得到一个解决二分类问题的分类器,也称为人脸检测模板。这个分类器接受固定大小的输入图片,判断这个输入图片是否为人脸,即解决是和否的问题。人脸二分类器的原理如下图所示:
人脸检测一研究进展
人脸检测算法研究分为3个发展阶段:
1.基于模版匹配的算法
2.基于 Ada boost的框架
3.基于深度学习的算法
基于模板匹配的人脸检测算法
早期的人脸检测算法使用了模板匹配技术,即用一个人脸模板图像与被检测图像中的各个位置进行匹配确定这个位置处是否有人脸,即针对图像中某个区域进行人脸-非人脸二分类的判别.
早期有代表性的成果是 Rowley等人提出的方法[1]。他们用神经网络进行人脸检测,用20×20的人脸和非人脸图像训陈练了一个多层感知器模型。论文门]中的方法用于解决近似正面的人脸检测问题,原理如下图所示
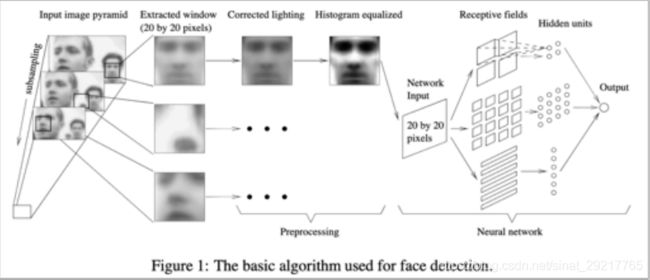 [1] Henry A Rowley, Shumeet Baluja, Takeo Kanade. Neural network-based face detection. 1998, IEEE Transactions on Pattern Analysis and Machine Intelligence
[1] Henry A Rowley, Shumeet Baluja, Takeo Kanade. Neural network-based face detection. 1998, IEEE Transactions on Pattern Analysis and Machine Intelligence
Rowley等人提出的方法[2]解决了多角度人脸检测问题,整个系统由两个神经网络构成,第一个网络用于估计人脸的角度,第二个用于判断是否为人脸。角度估计器输出一个旋转角度,然后用整个角度对检测窗进行旋转,然后用第二个网络对旋转后的图像进行判断,确定是否为人脸。系统结构如下图所示
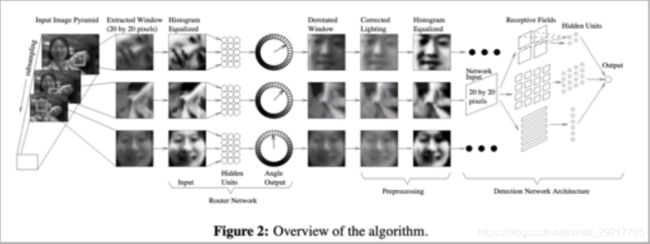 [2] Henry A Rowley, Shumeet Baluja, Takeo Kanade. Rotation invariant neural network-based face detection. 1998, computer vision and pattern recognition
[2] Henry A Rowley, Shumeet Baluja, Takeo Kanade. Rotation invariant neural network-based face detection. 1998, computer vision and pattern recognition
基于 Adaboost框架的人脸检测算法
Boost算法是基于PAC( Probably Approximately Correct)学习理论而建立的一套集成学习( EnsembleLearning)算法。俗话说“三个臭皮匠,顶个诸葛亮"”。 Boost的核心思想便是利用多个简单的弱分类器,构建出高准确率的强分类器。
在2001年, Viola和 Jones设计了一种人脸检测框架(Ⅵ框架)[3]。它使用简单的Har-like特征和级联的Adaboost分类器构造检测器,检测速度较之前的方法有2个数量级的提髙,并且保持了很好的精度。
在深度学习岀现以前工业界的方案都是基于Ⅵ算法。但Ⅵ算法仍存在一些问题 1.Har-like特征是一种相对简单的特征,其稳定性较低 2.弱分类器采用简单的决策树,容易过拟合。因此,该算法对于解决正面的人脸效果好,对于人脸的遮挡,姿态,表情等特殊且复杂的情况效果一般 3.基于VJ- cascade的分类器设计,进入下一个 stage后,之前的信息都丢弃了。分类器评价一个样本不会基于它在之前 stage的表现,鲁棒性差。
[3]P Viola and MJones Rapid object detection using a boosted cascade of simple features. In Proceedings IEEE Conf on Computer Vision and Pattern Recognition, 2001
基于深度学习的人脸检测算法 CNN在图像分类问题上取得成功之后很快被用于人脸检测问题,在精度上大幅度超越之前的 Ada boost框架。在此之前,滑动窗口+卷积对窗口图像进行分类的计算量巨大,无法做到实时检测。当前,已经有一些快速、高效的基于深度学习的算法,我们介绍重点介绍 Cascade cnn[4]和 MTCNN[5]
Cascade cnn可以认为是传统技术和深度网络相结合的一个代表,和V人脸检测器一样其包含了多个分类器,这些分类器采用级联结构进行组织。不同的地方在于, CascadeCNN采用卷积网络作为每一级的分类器
[4]Haoxiang Li, Zhe Lin, Xiaohui Shen, Jonathan Brandt, Gang Hua. A convolutional neural network cascade for face detection 2015, computer vision and pattern recognition [5] Kaipeng Zhan, Zhanpeng Zhang, Zhifeng L, Yu Qiao Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks 2016, IEEE Signal Processing Letters
Cascade cnn Cascade cnn检测流程:构建多尺度的人脸图像金字塔,12-ne密集的扫描整幅图像(不同的尺寸), 快速的剔除掉超过90%的检测窗口;剩下窗口送入12- calibration-net调整尺寸和位置,使其更靠近潜在 的人脸图像附近。接着采用非极大值抑制(NMS)合并高度重叠的检测窗口,保留下来的候选检测窗口将 会被归一化到24x24作为24-net的输入,进一步剔除掉剩下来的近90%的检测窗口。接着通过24 calibration-net矫正检测窗口,并应用NMS进一步合并减少检测窗口的数量。将通过之前所有层级的检 测窗口对应的图像区域归一化到48×48送入48-net进行分类得到进一步过滤的人脸候选窗口。然后利用 NMS进行窗口合并,送入48- calibration-net矫正检测窗口作为最后的输出
(未完待续)