Overfitting and underfitting in deep learning
在深度学习中,训练的过程中大家会经常遇到 Overfitting and underfitting这两种情况.
大家还记得去年NIPS上的大牛Ali Rahimi(阿里·拉希米)炮轰:机器学习已经成了炼金术!
 炼金术挺好的,炼金术没毛病,它自有它的地位,炼金术“管用”。
炼金术挺好的,炼金术没毛病,它自有它的地位,炼金术“管用”。
除了深度学习中各种参数的不确定性,还有Overfitting and underfitting,无疑人一些人觉得,高大上的深度学习背后的理论支撑实在是太少了.
炼金术带来了冶金、纺织、现代玻璃制造工艺、医疗等等领域的发明, 但是无论怎样,它能在实际中解决问题...
01.
有关过拟合和欠拟合,我们在机器学习入门的章节早就学过,大家看看下面的图片,应该很明白.
 过拟合和欠拟合问题.
过拟合和欠拟合问题.
但是,在深度学习的具体训练中 overfitting and underfitting的情景是如何表现出来的? 有何哪些因素有关?
我们就拿MNIST手写数字识别为例吧(貌似这个已经成了经典了).
MNIST有60,000个用于训练的28*28的灰度手写数字图片(0-9一共10个数字),10,000个测试图片,是我们初学时最常用例子. 具体可以参照我以前的那篇文章keras 数据集学习笔记.
我们先构建一个模型(original model):
# original model
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
这个模型很简单3层, 前2层都是16的全连接层.
在这个模型基础上,我们在设计一个更加简化的模型(Smaller model): 把前2层变成4.
# Smaller model
model = models.Sequential()
model.add(layers.Dense(4, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(4, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
我们跑一下训练比较一下这两个模型的validation loss:
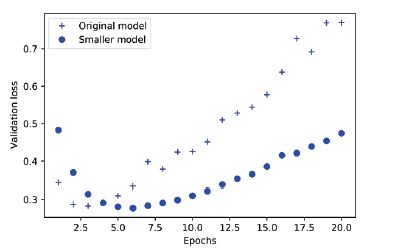
你可以看到,小的模型开始收敛的较快,在4epoch后,收敛比原始的模型变慢,最后开始进入 overfitting 状态.
我们再讲一个大的模型:(Bigger model)前2层变成512.
# Bigger model
model = models.Sequential()
model.add(layers.Dense(512, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
我们比较一下结果:

更大的模型差不多一开始就开始overfitting,后面就像是噪音一样不规则的跳动.
那么我们再看一下另外一项参数(trainning loss):

正如我们看到的,大的模型trainning loss很快接近0,但是随后也会有些波动,会逐渐增大,这一点和 validation loss的结果不同.
我们看到了模型的大小直接关系到训练的结果.但是没有公式可以套用,具体采用什么模型,还需要经验和在应用中的调整.