动手学数据分析1
动手学数据分析1
全部参考 datawhale-动手学数据分析
1. 载入数据
数据集下载 https://www.kaggle.com/c/titanic/overview
1.1 导入numpy和pandas
import pandas as pd
import numpy as np
print(pd.__version__) # 查看Pandas版本
1.0.3
1.2 读入数据
df = pd.read_csv('train.csv') # 相对路径载入数据
df = pd.read_csv('C:\\Users\\li\\Desktop\\动手学数据分析-组队学习版\\动手学数据分析-组队学习版\\第一单元项目集合\\train.csv') # 绝对路径载入数据

【提示】相对路径载入报错时,尝试使用os.getcwd()查看当前工作目录。
【思考】知道数据加载的方法后,试试pd.read_csv()和pd.read_table()的不同,如果想让他们效果一样,需要怎么做?了解一下’.tsv’和’.csv’的不同,如何加载这两个数据集?
- read_csv函数功能: 从文件、URL、文件新对象中加载带有分隔符的数据,默认分隔符是逗号。
- read_table函数: 从文件、URL、文件型对象中加载带分隔符的数据,默认分隔符为制表符("\t")
【总结】加载的数据是所有工作的第一步,我们的工作会接触到不同的数据格式(eg:.csv;.tsv;.xlsx),但是加载的方法和思路都是一样的,在以后工作和做项目的过程中,遇到之前没有碰到的问题,要多多查资料吗,使用googel,了解业务逻辑,明白输入和输出是什么。
1.3 逐块读取数据
df = pd.read_csv('train.csv', chunksize=1000) # 每1000行为一个数据模块,逐块读取
# df 类型: 
【思考】什么是逐块读取?为什么要逐块读取呢?
- read_csv中有个参数chunksize,通过指定一个chunksize分块大小来读取文件,返回的是一个可迭代的对象TextFileReader。
- 方便读取其中的一部分数据或对文件进行逐块处理。
1.4 更改表头
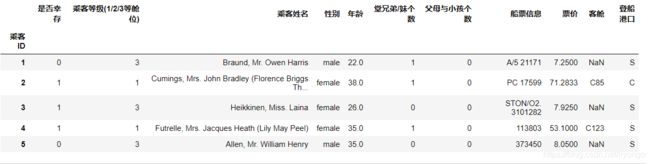
将数据中英文表头改为中文
PassengerId => 乘客ID
Survived => 是否幸存
Pclass => 乘客等级(1/2/3等舱位)
Name => 乘客姓名
Sex => 性别
Age => 年龄
SibSp => 堂兄弟/妹个数
Parch => 父母与小孩个数
Ticket => 船票信息
Fare => 票价
Cabin => 客舱
Embarked => 登船港口
#写入代码
df = pd.read_csv('train.csv') # 在使用pandas的read_csv方法时,它默认会自动加上一列行号。index_col=0 去掉默认行号
df.columns = ['乘客ID', '是否幸存', '乘客等级(1/2/3等舱位)', '乘客姓名', '性别', '年龄', '堂兄弟/妹个数','父母与小孩个数','船票信息','票价','客舱','登船港口']
df = df.set_index('乘客ID') # 重新设 乘客ID 为索引,去掉默认会自动加上一列行号
df.head()
df.to_csv('train_Chinese.csv',encoding='utf_8_sig')
【思考】所谓将表头改为中文其中一个思路是:将英文额度表头替换成中文。还有其他的方法吗?
df.rename(columns=('PassengerId': '乘客ID', 'Survived': '是否幸存', 'Pclass': '乘客等级(1/2/3等舱位)', 'Name': '乘客姓名', 'Sex': '性别','Age':'年龄','SibSp':'堂兄弟/妹个数','Parch':'父母与小孩个数','Ticket':'船票信息','Fare':'票价','Cabin':'客舱','Embarked':'登船港口' }, inplace=True)
df = pd.read_csv('train.csv', names=['乘客ID','是否幸存','仓位等级','姓名','性别','年龄','兄弟姐妹个数','父母子女个数','船票信息','票价','客舱','登船港口'],index_col='乘客ID',header=0)
2 初步观察数据
2.1 查看数据基本信息
print(df.index) # 查看索引
print(df.columns) # 查看表头
print(df.shape) # 查看行列数
# 查看列类型
cols = df.columns
for col in cols:
print(col+' : '+ str(df[col].dtype))

# 查看数据集是否存在缺失值 (统计缺失值个数)
# print(df.apply(lambda x:np.sum(x.isnull())))
df.isna().sum()

df.info()

【提示】有多个函数可以这样做,你可以做一下总结
2.2 查看表格前几行或后几行数据
df.head(3) # 观察表格前3行的数据

df.tail(3) # 观察表格后3行的数据

2.3 判断数据是否为空
# df.isna().head()
df.isnull().head()

【总结】上面的操作都是数据分析中对于数据本身的观察
3 保存数据
df.to_csv('train_chinese.csv',encoding='utf_8_sig')