Pytorch 入门之--简单循环网络RNN
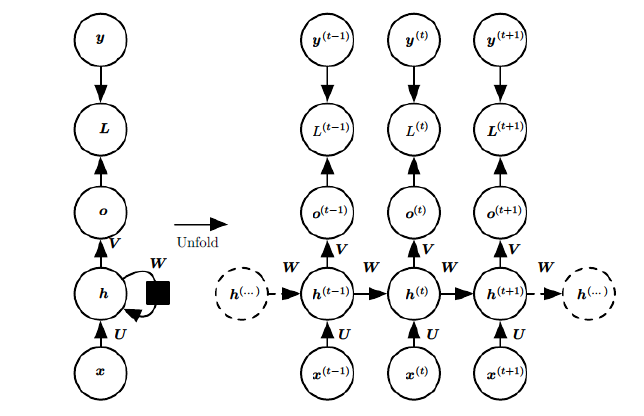
循环神经网络已经被广泛应用在语音识别、语言模型以及自然语言生成等任务上。RNN不仅能够处理序列输入,也能够得到序列输出,这里的序列指的是向量的序列。
循环神经网络的参数学习可以通过随时间反向传播算法[Werbos, 1990] 来学习。随时间反向传播算法即按照时间的逆序将错误信息一步步地往前传递。当输入序列比较长时,会存在梯度爆炸和消失问题[Bengio et al., 1994, Hochreiter and Schmidhuber, 1997, Hochreiteret al., 2001],也称为长期依赖问题。为了解决这个问题,人们对循环神经网络进行了很多的改进,其中最有效的改进方式引入门控机制。
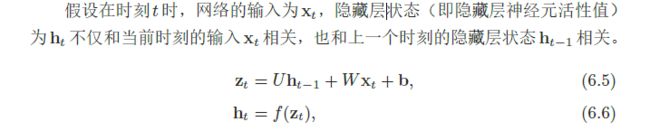

--- 以上摘自邱锡鹏nndl-book
GitHub------nndl-book
简单循环网络实现分类--代码实例如下:
import torch
from torch import nn, optim
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
# 定义超参数
batch_size = 100
learning_rate = 1e-3
num_epoches = 20
# 下载训练集 MNIST 手写数字训练集
train_dataset = datasets.MNIST(
root='./data', train=True, transform=transforms.ToTensor(), download=True)
test_dataset = datasets.MNIST(
root='./data', train=False, transform=transforms.ToTensor())
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 定义 Recurrent Network 模型
class Rnn(nn.Module):
def __init__(self, in_dim, hidden_dim, n_layer, n_class):
super(Rnn, self).__init__()
self.n_layer = n_layer
self.hidden_dim = hidden_dim
#self.lstm = nn.LSTM(in_dim, hidden_dim, n_layer, batch_first=True)
self.lstm = nn.LSTM( # if use nn.RNN(), it hardly learns
input_size=in_dim,
hidden_size=hidden_dim, # rnn hidden unit
num_layers=n_layer, # number of rnn layer
batch_first=True, # input & output will has batch size as 1s dimension. e.g. (batch, time_step, input_size)
)
self.classifier = nn.Linear(hidden_dim, n_class)
def forward(self, x):
# h0 = Variable(torch.zeros(self.n_layer, x.size(1),
# self.hidden_dim)).cuda()
# c0 = Variable(torch.zeros(self.n_layer, x.size(1),
# self.hidden_dim)).cuda()
out, _ = self.lstm(x)
out = out[:, -1, :]
out = self.classifier(out)
return out
model = Rnn(28, 128, 2, 10) # 图片大小是28x28
use_gpu = torch.cuda.is_available() # 判断是否有GPU加速
if use_gpu:
model = model.cuda()
# 定义loss和optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# 开始训练
for epoch in range(num_epoches):
print('epoch {}'.format(epoch + 1))
print('*' * 10)
running_loss = 0.0
running_acc = 0.0
for i, data in enumerate(train_loader, 1):
img, label = data
b, c, h, w = img.size()
assert c == 1, 'channel must be 1'
img = img.squeeze(1)
# img = img.view(b*h, w)
# img = torch.transpose(img, 1, 0)
# img = img.contiguous().view(w, b, -1)
if use_gpu:
img = Variable(img).cuda()
label = Variable(label).cuda()
else:
img = Variable(img)
label = Variable(label)
# 向前传播
out = model(img)
loss = criterion(out, label)
running_loss += loss.data[0] * label.size(0)
_, pred = torch.max(out, 1)
num_correct = (pred == label).sum()
running_acc += num_correct.data[0]
# 向后传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 300 == 0:
print('[{}/{}] Loss: {:.6f}, Acc: {:.6f}'.format(
epoch + 1, num_epoches, running_loss / (batch_size * i),
running_acc / (batch_size * i)))
print('Finish {} epoch, Loss: {:.6f}, Acc: {:.6f}'.format(
epoch + 1, running_loss / (len(train_dataset)), running_acc / (len(
train_dataset))))
model.eval()
eval_loss = 0.
eval_acc = 0.
for data in test_loader:
img, label = data
b, c, h, w = img.size()
assert c == 1, 'channel must be 1'
img = img.squeeze(1)
# img = img.view(b*h, w)
# img = torch.transpose(img, 1, 0)
# img = img.contiguous().view(w, b, h)
if use_gpu:
img = Variable(img, volatile=True).cuda()
label = Variable(label, volatile=True).cuda()
else:
img = Variable(img, volatile=True)
label = Variable(label, volatile=True)
out = model(img)
loss = criterion(out, label)
eval_loss += loss.data[0] * label.size(0)
_, pred = torch.max(out, 1)
num_correct = (pred == label).sum()
eval_acc += num_correct.data[0]
print('Test Loss: {:.6f}, Acc: {:.6f}'.format(eval_loss / (len(
test_dataset)), eval_acc / (len(test_dataset))))
print()
# 保存模型
torch.save(model.state_dict(), './rnn.pth')