案例与解决方案汇总页:
阿里云实时计算产品案例&解决方案汇总
一. 背景介绍
菜鸟的物流数据本身就有链路复杂、实操节点多、汇总维度多、考核逻辑复杂的特点,对于实时数据的计算存在很大挑战。经过仓配ETL团队的努力,目前仓配实时数据已覆盖了绝大多数场景,但是有这样一类特殊指标:“晚点超时指标”(例如:出库超6小时未揽收的订单量),仍存在实时汇总计算困难。原因在于:流计算是基于消息触发计算的,若没有消息到达到则无法计算,这类指标恰好是要求在指定的超时时间计算出有多少未达到的消息。然而,这类指标对于指导实操有着重要意义,可以告知运营小二当前多少订单积压在哪些作业节点,应该督促哪些实操人员加快作业,这对于物流的时效KPI达成至关重要。
之前的方案是:由产品前端根据用户的请求查询OLAP数据库,由OLAP从明细表出结果。大促期间,用户请求量大,加之数据量大,故对OLAP的明细查询造成了比较大的压力。
二. 解决方案
2.1 问题定义
“超时晚点指标” 是指,一笔订单的两个相邻的实操节点node_n-1 、node_n 的完成时间 time_n-1、time_n,
当满足 : time_n is null && current_time - time_n-1 > kpi_length 时,time_flag_n 为 true , 该笔订单计入 超时晚点指标的计数。
如下图,有一笔订单其 node_1 为出库节点,时间为time_1 = '2018-06-18 00:00:00' ,运营对出库与揽收之间考核的时长 kpi_length = 6h, 那么当前自然时间 current_time > '2018-06-18 06:00:00' 时,且node_2揽收节点的time_2 为null,则该笔订单的 timeout_flag_2 = true , “出库超6小时未揽收订单量” 加1。由于要求time_2 为null,即要求没有揽收消息下发的情况下让流计算做汇总值更新,这违背了流计算基于消息触发的基本原理,故流计算无法直接算出这种“超时晚点指标”。

决问题的基本思路是:在考核时刻(即 kpi_time = time_n-1+kpi_length )“制造”出一条消息下发给流计算,触发汇总计算。继续上面的例子:在考核时刻“2018-06-18 06:00:00”利用MetaQ定时消息功能“制造”出一条消息下发给流计算汇总任务,触发对该笔订单的 time_out_flag_2 的判断,增加汇总计数。同时,还利用 Blink 的Retraction 机制,当time_2 由null变成有值的时候,Blink 可以对 time_out_flag_2 更新,重新计数。
2.2 方案架构
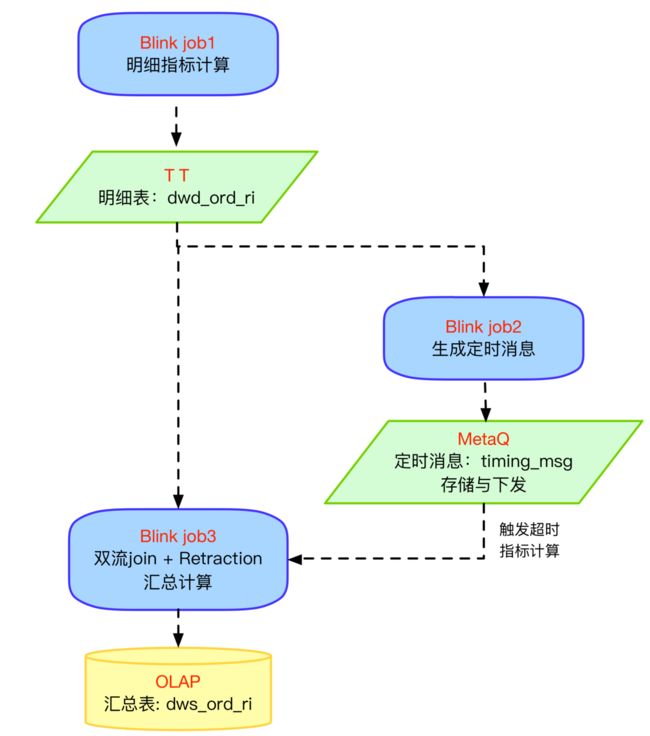
如上图所示:
Step1: Blink job1 接收来自上游系统的订单数据,做清洗加工,生成订单明细表:dwd_ord_ri,利用TT下发给Blink job2 和 Blink job3。
Step2:Blink job2 收到 dwd_ord_ri后,对每笔订单算出考核时刻 kpi_time = time_n-1+kpi_length,作为MetaQ消息的“TIMER_DELIVER_MS” 属性,写入MetaQ。MetaQ的定时消息功能,可以根据用户写入的TIMER_DELIVER_MS 在指定时刻下发给消费者,即上图中的Blink job3。
Step3:Blink job3 接收 TT、MetaQ 两个消息源,先做Join,再对time_flag判断,最后做Aggregate计算。同一笔订单,dwd_ord_ri、timing_msg任意一个消息到来,都会触发join,time_flag判断,aggregate重新计算一遍,Blink的Retraction可对结果进行实时更新。
2.3 实现细节
本方案根据物流场景中多种实操节点、多种考核时长的特点,从Blink SQL代码 和 自定义Sink两方面做了特殊设计,从而实现了灵活配置、高效开发。
(1) Blink job2 --- 生成定时消息
关键Blink SQL 代码如下。约定每条record的第一个字段为投递时间列表,即MetaQ向消费者下发消息的时刻List,也就是上面所说的多个考核时刻。第二个字段为保序字段,比如在物流场景中经常以订单code、运单号作为保序主键。该代码实现了对每个出库的物流订单,根据其出库时间,向后延迟6小时(21600000毫秒)、12小时(43200000毫秒)、24小时(86400000毫秒)由MetaQ向消费者下发三个定时消息。
create table metaq_timing_msg
(
deliver_time_list varchar comment '投递时间列表', -- 约定第一个字段为投递时间list
lg_code varchar comment '物流订单code', -- 约定第二字段为保序主键
node_name varchar comment '节点名称',
node_time varchar comment '节点时间',
)
WITH
(
type = 'custom',
class = 'com.alibaba.xxx.xxx.udf.MetaQTimingMsgSink',
tag = 'store',
topic = 'blink_metaq_delay_msg_test',
producergroup = 'blinktest',
retrytimes = '5',
sleeptime = '1000'
);
insert into metaq_timing_msg
select
concat_ws(',',
cast( (UNIX_TIMESTAMP(store_out_time)*1000 + 21600000) as varchar), --6小时
cast( (UNIX_TIMESTAMP(store_out_time)*1000 + 43200000) as varchar), --12小时
cast( (UNIX_TIMESTAMP(store_out_time)*1000 + 86400000) as varchar) --24小时
) as deliver_time_list,
lg_code,
'wms' as node_name,
store_out_time as node_time
from
(
select
lg_code,
FIRST_VALUE(store_out_time) as store_out_time
from srctable
group by lg_code
)b
where store_out_time is not null ;
(2) Blink 自定义Sink --- MetaQTimingMsg Sink
Blink的当前版本还不支持 MetaQ的定时消息功能的Sink,故利用 Blink的自定义Sink功能,并结合菜鸟物流数据的特点开发了MetaQTimingMsg Sink。关键代码如下(实现 writeAddRecord 方法)。
@Override
public void writeAddRecord(Row row) throws IOException {
Object deliverTime = row.getField(0);
String[] deliverTimeList = deliverTime.toString().split(",");
for(String dTime:deliverTimeList){
String orderCode = row.getField(1).toString();
String key = orderCode + "_" + dTime;
Message message = newMessage(row, dTime, key);
boolean result = sendMessage(message,orderCode);
if(!result){
LOG.error(orderCode + " : " + dTime + " send failed");
}
}
}
private Message newMessage(Row row,String deliverMillisec,String key){
//Support Varbinary Type Insert Into MetaQ
Message message = new Message();
message.setKeys(key);
message.putUserProperty("TIMER_DELIVER_MS",deliverMillisec);
int arity = row.getArity();
Object[] values = new Object[arity];
for(int i=0;i list, Message message, Object o) {
.... // 针对物流订单code的hash算法
return list.get(index.intValue());
}
},orderCode);
if(!result.getSendStatus().equals(SendStatus.SEND_OK)){
LOG.error("" + orderCode +" write to metaq result is " + result.getSendStatus().toString());
isSendSuccess = false;
}
return isSendSuccess;
}
} (3)Blink job3 --- 汇总计算
关键Blink SQL 代码如下,统计了每个仓库的“出库超6小时未揽收物理订单”、“出库超12小时未揽收物理订单”、“出库超24小时未揽收物理订单”的汇总值。代码中使用了“stringLast()”函数处理来自dwd_ord_ri的每条消息,以取得每个物流订单的最新出库揽收情况,利用Blink Retraction机制,更新汇总值。
create view dws_store_view as
select
t1.store_code,
max(t1.store_name) as store_name,
count(case
when length(trim(t1.store_out_time)) = 19
and t1.tms_collect_time is null
and NOW()-UNIX_TIMESTAMP(t1.store_out_time,'yyyy-MM-dd HH:mm:ss') >= 21600
then t2.lg_code end
) as tms_not_collect_6h_ord_cnt, ---出库超6小时未揽收物流订单量
count(case
when length(trim(t1.store_out_time)) = 19
and t1.tms_collect_time is null
and NOW()-UNIX_TIMESTAMP(t1.store_out_time,'yyyy-MM-dd HH:mm:ss') >= 43200
then t2.lg_code end
) as tms_not_collect_12h_ord_cnt,---出库超6小时未揽收物流订单量
count(case
when length(trim(t1.store_out_time)) = 19
and t1.tms_collect_time is null
and NOW()-UNIX_TIMESTAMP(t1.store_out_time,'yyyy-MM-dd HH:mm:ss') >= 86400
then t2.lg_code end
) as tms_not_collect_24h_ord_cnt ---出库超6小时未揽收物流订单量
from
(
select
lg_code,
coalesce(store_code,'-1') as store_code,
store_name,
store_out_time,
tms_collect_time
from
(
select
lg_code,
max(store_code) as store_code,
max(store_name) as store_name,
stringLast(store_out_time) as store_out_time,
stringLast(tms_collect_time)as tms_collect_time,
from dwd_ord_ri
group by lg_code
) a
) t1
left outer join
(
select
lg_code,
from timing_msg
where node_name = 'wms'
group by lg_code
) t2
on t1.lg_code = t2.lg_code
group by
t1.store_code
;三. 方案优势
3.1 配置灵活
我们从“Blink SQL 代码” 和“自定义MetaQ” 两个方面设计,用户可以根据具体的业务场景,在Blink SQL的一个view里就能实现多种节点多种考核时间的定时消息生成,而不是针对每一个实操节点的每一种定时指标都要写一个view,这样大大节省了代码量,提升了开发效率。例如对于仓库节点的出库超6小时未揽收、超12小时未揽收、超24小时未揽收,这三个指标利用上述方案,仅需在Blink job2的中metaq_timing_msg的第一个字段deliver_time_list中拼接三个kpi_length,即6小时、12小时、24小时为一个字符串即可,由MetaQTimingMsg Sink自动拆分成三条消息下发给MetaQ。对于不同的节点的考核,仅需在node_name,node_time填写不同的节点名称和节点实操时间即可。
3.2 主键保序
如2.3节所述,自定义的Sink中 实现了MetaQ的 MessageQueueSelector 接口的 select() 方法,同时在Blink SQL 生成的MetaQ消息默认第二个字段为保序主键字段。从而,可以根据用户自定义的主键,保证同一主键的所有消息放在同一个通道内处理,从而保证按主键保序,这对于流计算非常关键,能够实现数据的实时准确性。
3.3 性能优良
让专业的团队做专业的事。个人认为,这种大规模的消息存储、消息下发的任务本就应该交给“消息中间件”来处理,这样既可以做到计算与消息存储分离,也可以方便消息的管理,比如针对不同的实操节点,我们还可以定义不同的MetaQ的tag。
另外,正如2.2节所述,我们对定时消息量做了优化。考虑到一笔订单的属性字段或其他节点更新会下发多条消息,我们利用了Blink的FIRST_VALUE函数,在Blink job2中同一笔订单的的一种考核指标只下发一条定时消息,大大减少了消息量,减轻了Blink的写压力,和MetaQ的存储。
四. 自我介绍
马汶园 阿里巴巴 -菜鸟网络—数据部 数据工程师
菜鸟仓配实时研发核心成员,主导多次仓配大促实时数据研发,对利用Blink的原理与特性解决物流场景问题有深入思考与理解。

本文作者:付空
本文为云栖社区原创内容,未经允许不得转载。