ElasticSearch第十篇:multi_match多字段查询以及wildcard模糊查询
1.multi_match
multi_match查询提供了一个简便的方法用来对多个字段执行相同的查询,即对指定的多个字段进行match查询,其有三种类型,
best_fields,most_fields以及cross_fields,默认为best_fields。
比如使用同一个查询关键字同时在company和place中查询:
GET 51job/_doc/_search
{
"query": {
"multi_match" : {
"query" : "鹏开罗湖",
"fields": ["company", "place"],
"type": "best_fields",
"tie_breaker": 0.3,
"minimum_should_match": "30%"
}
}
}结果如下:

将company字段和place字段里包含"鹏开罗湖"的文档全部查询出来了。
multi_match查询中,查询字段名称的模糊匹配:
博主的es库里没有可模糊匹配的字段,编一个。
字段名称可以用模糊匹配的方式给出(使用*号匹配):任何与模糊模式正则匹配的字段都会被包括在搜索条件中,例如可以使用以下方式同时匹配 book_title 、 chapter_title 和 section_title (书名、章名、节名)这三个字段:
GET 51job/_doc/_search
{
"query": {
"multi_match" : {
"query" : "鹏开罗湖",
"fields": "*_title",
"type": "best_fields",
"tie_breaker": 0.3,
"minimum_should_match": "30%"
}
}
}multi_match查询中,提升单个字段的权重:
可以使用 ^ 字符语法为单个字段提升权重,在字段名称的末尾添加 ^boost ,其中 boost 是一个浮点数:
GET 51job/_doc/_search
{
"query": {
"multi_match" : {
"query" : "鹏开罗湖",
"fields": ["company", "place^2"],
"type": "best_fields",
"tie_breaker": 0.3,
"minimum_should_match": "30%"
}
}
}其中一个搜索结果的评分如下(翻了2倍):
{
"_index" : "51job",
"_type" : "_doc",
"_id" : "C0eg-3MBrm2PQExGCcDA",
"_score" : 13.262653,
"_source" : {
"id" : 27,
"job" : "中级Java开发工程师",
"company" : "上海吉联新软件股份有限公司",
"place" : "深圳-罗湖区",
"salar" : "1-1.5万/月",
"data" : "12-13"
}
}
2.wildcard模糊查询
查询job字段中以中级Java开发工程师开头,以任意字符结尾的文档,其中使用*来匹配
GET 51job/_doc/_search
{
"query": {
"wildcard" : {
"job" : "中级Java开发工程师*"
}
}
}查询结果如下:
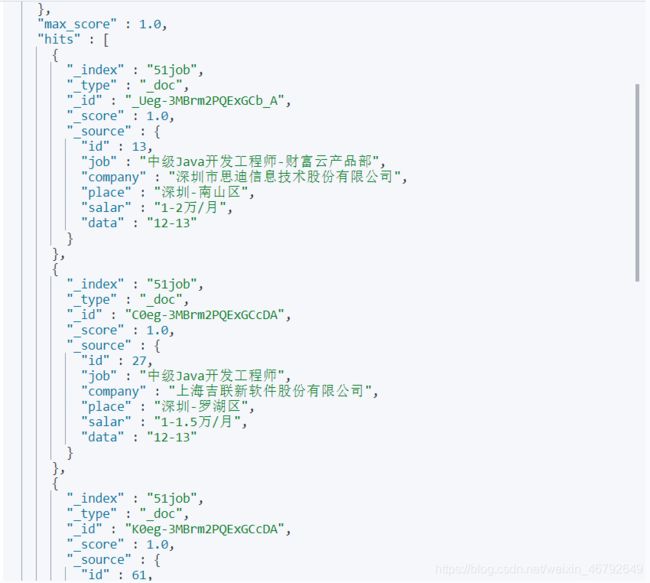
结果跟预期一样,但是如果数据量很大时,使用这个模糊查询效率很低,建议先分词建立倒排索引再分词查询。