LSTM原理详解(pytorch 附带BiLSTM)
本文是自己在项目中用到的部分学习了之后的一些理解和整理,希望对你学习过程中有所帮助,有啥问题欢迎评论一起讨论。
目录
1、LSTM原理
2、BiLSTM原理
3、pytorch torch.nn.LSTM 源码理解
参考资料
1、LSTM原理
LSTM网络(Long short-term memory,长短期记忆网络)是一种特殊的RNN,能够学习长期依赖关系,它们是由Hochreiter&Schmidhuber(1997)[4]提出的,并在随后的工作中被许多人改进和推广。
LSTM由于其设计的特点,非常适合用于对时序数据的建模,如文本数据。
总的来说就是它的结构如下图所示,一个格格代表一个LSTM单元

主要由三个门构成: forget gate,input gate,output gate具体的计算公式如下:
Forget gate:
这个阶段主要是对上一个节点传进来的输入进行选择性忘记。简单来说就是会 “忘记不重要的,记住重要的”。

其中 为当前时刻的输入,
为当前时刻的输入, 为上一时刻输出的隐状态向量,σ表示sigmoid方程,其他都是一些可训练参数
为上一时刻输出的隐状态向量,σ表示sigmoid方程,其他都是一些可训练参数
Input gate:
这个阶段将这个阶段的输入有选择性地进行“记忆”
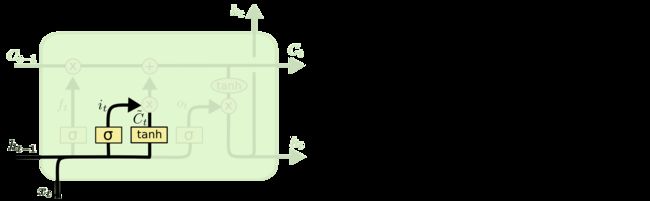

其中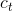 为细胞状态向量
为细胞状态向量
Output gate:
这个阶段将决定哪些将会被当成当前状态的输出。
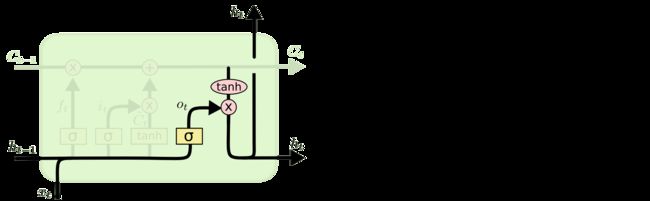
比如一句话[你,好,啊,我,是,X,X,X]输入到LSTM
时刻1:你 ==  通过计算 得到
通过计算 得到 ![]()
时刻2:好 == 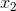 利用上一时刻得到的
利用上一时刻得到的![]() 通过计算公式得到
通过计算公式得到 ![]()
…….
在LSTM中,最后一个时刻LSTM单元的隐状态向量 可以当作文本句子的向量表示,可以认为包含了整个句子的信息。
可以当作文本句子的向量表示,可以认为包含了整个句子的信息。
详细可以去看这个博客:LSTM原理
2、BiLSTM原理
BiLSTM是Bi-directional Long Short-Term Memory的缩写,是由前向LSTM与后向LSTM组合而成。
下图能很好解释BiLSTM编码方式

就是通过前向![]() 依次对 [我,爱,中国] 编码 得到{
依次对 [我,爱,中国] 编码 得到{![]() }.
}.
后向的![]() 依次输入 [中国,爱,我] 得到三个向量{
依次输入 [中国,爱,我] 得到三个向量{![]() }。
}。
最后将前向和后向的隐向量进行拼接得到{[![]() ], [
], [![]() ],
], ![]() }
}
对于情感分类任务,一般采用的句子表示往往是[![]() ],因为包含了前向和后向的所有信息。如下图
],因为包含了前向和后向的所有信息。如下图
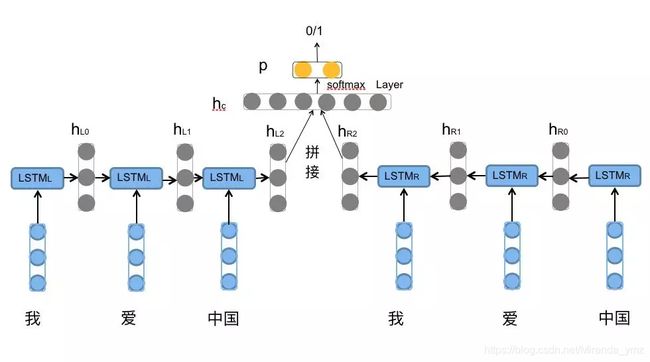
但BiLSTM,每个时间步的隐状态输出都可以作为当前词的一个融合了上下文的向量,因此可以利用每个时刻的隐状态输出(例如上文[![]() ],可认为当前词融合了上下文的向量),因此BiLSTM可以视为一种词级别的encoder方法,得到的output(ppytorch,中输出有
],可认为当前词融合了上下文的向量),因此BiLSTM可以视为一种词级别的encoder方法,得到的output(ppytorch,中输出有![]() )既可以用于词级别的输出拼接,也可以进行融合(比如attention加权求和、pooling)得到序列级的输出。(这个和后面的torch.nn.LSTM 结合起来理解)
)既可以用于词级别的输出拼接,也可以进行融合(比如attention加权求和、pooling)得到序列级的输出。(这个和后面的torch.nn.LSTM 结合起来理解)
3、pytorch torch.nn.LSTM 源码理解
官网上对LSTM的解释如下:

由上文应该指导他给的公式的意思了,就是每一层里,对于输入序列的每个元素的计算过程如下,(也就是一个LSTM单元的计算过程)
对于多层的LSTM ,第l-th层的输入![]() 是
是![]() 是上一层t时刻隐状态向量。
是上一层t时刻隐状态向量。
就像下图所示:个人认为这幅图能够很好的理解代码
 图 a
图 a
先说一下torch.nn.LSTM的参数:
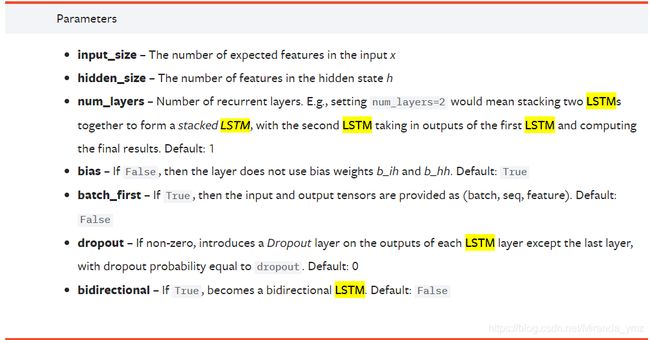
input_size:为每个时刻的输入向量X的维度
hidden_size : 为隐状态向量维度
num_layers: 为RNN层数
bidirectional:为是否为BiLSTM
LSTM 的输入为(input,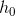 ,
,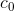 )
)
input 的大小为(seq_len,batch,input_size):
seq_len 为输入的文本序列的长度,一般文本中的单词会用词向量表示,
batch 就是批处理大小
input_size 就可以认为是词向量的维度(在建立LSTM的时候就设置了这个参数)。
(关于词向量,大家自己百度吧。在pytorch 中可以使用nn.Embedding(vocab_size,embedding_dim) 一般在大家会把文本序列使用词字典映射成序号,比如[你,好,啊],词字典中{你:1},{好:10},{啊:5},那文本序列可以表示为[1,10,5],vocab_size 就是词字典的大小,embedding_dim 就是词向量的维度,一般会设为256,512.)
的大小为(num_layers*num_directions,batch,hidden_size) 初始隐状态向量,如果没给的话默认为0
的大小为(num_layers*num_direction,batch,hidden_size) 初始细胞向量,没给的话默认为0
至于里面num_layers*num_direction 看那个上图图a应该可以理解到,每一层都可以设置一个初始 , ,如果是BiLSTM,num_direction = 2。为什么为2,就是正向LSTM和反向LSTM都需要。
LSTM 的输出为(onput,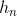 ,
,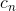 )
)
output 的大小为(seq_len,batch,num_direction*hidden_size):
output包含最后一层中每个时刻的隐状态向量,如果是BiLSTM,num_direction=2。包含可以看图a理解output
![]() 的大小为(num_layers*num_directions,batch,hidden_size) 就是每一层最后一个时刻LSTM单元的隐状态向量 集合
的大小为(num_layers*num_directions,batch,hidden_size) 就是每一层最后一个时刻LSTM单元的隐状态向量 集合
的大小为(num_layers*num_directions,batch,hidden_size) 就是每一层最后一个时刻LSTM单元的细胞向量 集合
(注意:其实一直说时刻,其实时刻就是序列长度,t=seq_len)
再贴一个简单的LSTM,这里使用的是BiLSTM,最后采用的是output,这里可以参考2、BiLSTM的最后一段
class LSTM(BasicModule):
def __init__(self,opt):
super(LSTM,self).__init__()
self.opt = opt
self.embed = nn.Embedding(opt.vocab_size,opt.embedding_dim)
self.content_lstm = nn.LSTM(input_size=opt.embedding_dim,
hidden_size=opt.hidden_size,
num_layers=opt.num_layers,
bias=True,
batch_first=False,
bidirectional=True)
self.fc = nn.Sequential(
nn.Linear(opt.hidden_size,opt.linear_hidden_size),
nn.BatchNorm1d(opt.linear_hidden_size),
nn.ReLU(inplace=True),
nn.Linear(opt.linear_hidden_size,opt.num_classes)
)
def forward(self, content):
content = self.embed(content)
content_out,(hidden_state,cell_state) = self.content_lstm(content.permute(1, 0, 2)) #(seq,batch,num_dirction*hidden_size) #256*2
return content_out.permute(1,2,0) #8,512*2,484
参考资料:
[1] LSTM细节分析理解(pytorch版)https://zhuanlan.zhihu.com/p/79064602
[2] LSTM原理http://colah.github.io/posts/2015-08-Understanding-LSTMs/
[3] torch.nn.LSTM https://pytorch.org/docs/stable/nn.html?highlight=lstm#torch.nn.LSTM
[4] Long short-term memory https://www.mitpressjournals.org/doi/abs/10.1162/neco.1997.9.8.1735
[5] 人人都能看懂的LSTM https://zhuanlan.zhihu.com/p/32085405
[6] BiLSTM介绍及代码实现 https://www.jiqizhixin.com/articles/2018-10-24-13
上述提到的论文可用这个链接存储 链接:https://pan.baidu.com/s/1FUCmVXMosVL9ALv9zT0LVw
提取码:r8ga