斯坦福Machine Learning with Graphs 学习笔记(第二讲)
作者:于媛,十三鸣
本文长度为3300字,建议阅读10+分钟
本文为大家介绍常用的网络属性和经典的网络模型。
[ 导读 ]在研究网络的时候,我们往往需要从结构层面对网络进行分析,网络属性可视为对网络结构的静态刻画,而网络模型则能帮助我们从动态的网络生成的过程了解网络结构。这节我们主要介绍一些常用的网络属性和一些经典的网络模型。
目录
一、网络属性(Network Properties)
二、Erdös-Renyi Random Graph Model
三、Small-World Model
四、Kronecker Graph Model
五、Stochastic Kronecker Graph Model
一、网络属性(Network Properties)
1. 度分布(degree distribution)P(k)
度分布指的是对一个图(网络)中顶点(节点)度数的总体描述。对于随机图,度分布指的是图中顶点度数的概率分布。
Nk表示度数为k的节点, N表示网络中度的总数,则度分布为:
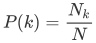
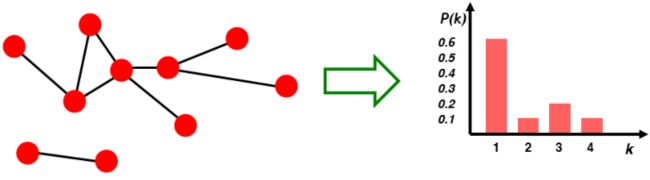
通常我们用直方图的形式来表示图的度分布,如下图:
2. 路径(path) Pn
路径指一个顶点序列,使得从它的每个顶点有一条边到该序列中下一顶点。一条道路可能是无穷的,但有限道路一定会有一个最先的顶点(称为起点)和最后的顶点(称为末点),即路径的端点。同时,路径也可以经过一个点多次,比如:ACBDCDEG。
3. 距离(distance)h
两个节点间最短的路径称为这一对节点的距离。注意如果两个点不相连,则规定距离是无限大或者是0。
在有向图中,距离必须是带方向的。举例说明,在有向图中,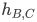 和
和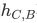 不同,因为可能出现B、C直接连接,但是从C到B需要经过A节点的情况。
不同,因为可能出现B、C直接连接,但是从C到B需要经过A节点的情况。
4. 直径(diameter)
图的直径是整个图中节点间距离的最大值。对于一个连通图或者强连通的有向图,平均路径长度公式是:
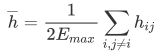
其中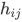 代表从节点 i 到节点 j 的距离,
代表从节点 i 到节点 j 的距离,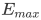 表示最大边数(
表示最大边数(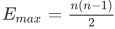 其中 n 表示节点数)
其中 n 表示节点数)
注意:我们计算平均路径的前提条件是节点对都是可达的,否则不能纳入计算(不可达的节点对的距离为无穷大),这个方法也适用于强连通图。
5. 集聚系数(clustering coefficient)C
集聚系数描述一个无向图中的顶点之间结集成团的程度。具体指是节点的邻接点间相互连接的程度。对于节点 ,集聚系数可以表示成:
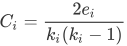
其中 ,式子中ei表示节点 i 的邻居之间的边数,ki表示节点 i 的度(即节点 i 的邻居数),分母ki(ki-1)中的 表示邻居间的最大边数。
,式子中ei表示节点 i 的邻居之间的边数,ki表示节点 i 的度(即节点 i 的邻居数),分母ki(ki-1)中的 表示邻居间的最大边数。
集聚系数计算实例如下:
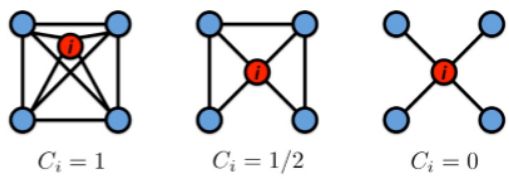
具体计算过程分别为:
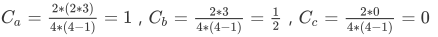
很多时候也可用平均集聚系数(Average clustering coefficient)来表示一个网络的集聚系数:
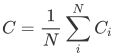
平均集聚系数的计算实例如下:
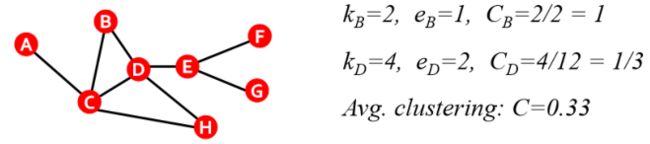
6. 连通元件(connected components)S
连通元件又称为元件、分量或分支,是一个无向子图,在元件中的任何两个顶点都可以经由该图上的边抵达另一个顶点,且没有任何一边可以连到其他子图的顶点。
找到连通元件的算法:
从任意一点开始进行广度优先遍历(BFS);
对访问过的节点进行标记;
如果所有节点都被访问过了,整个网络就是都是连通的;
否则找到一个未被访问的节点重新进行广度优先遍历。
了解了这些基本的网络属性之后,要如何应用它们呢?接下来,我们结合网络模型,应用上述网络属性进行具体分析,加深对网络属性和网络构成的认识。
这里主要介绍三个常用的随机网络模型:ER随机图模型(Erdös-Renyi Random Graph Model)、小世界模型(Small-World Model)和Kronecker图模型(Kronecker Graph Model)。
二、Erdös-Renyi Random Graph Model
“随机”的概念频繁应用于各类模型的构建,网络模型的构建同样关注这一概念。ER随机图模型作为网络模型中的经典模型,在提出后的很长一段时间,都是研究网络的重要数学工具。
随机图模型可由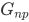 表示,具体定义如下:
表示,具体定义如下:
:该网络包含n个节点,任一边(u,v)出现的概率为p,且为独立同分布。
值得注意的是,随机图模型生成的过程是随机的,因此 并不能指定一个唯一的图。
接下来,结合上一部分介绍的网络属性对进行分析。
1. 度分布P(k)
的度分布服从二项分布(binomial distribution),P(k)可表示如下:

2. 集聚系数系数Ci
结合集聚系数的计算公式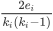 ,首先确定节点 i 邻接点间的边数ei,ei的期望可表示为
,首先确定节点 i 邻接点间的边数ei,ei的期望可表示为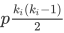 。随后可得
。随后可得 集聚系数期望值
集聚系数期望值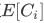 如下:
如下:
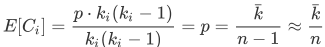
其中,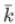 为的平均度。从上述公式不难发现,随机图的集聚系数并不高。此外,若在不改变的前提下,通过不断增加节点来提升图的规模,随着图规模的增大,集聚系数将不断降低。
为的平均度。从上述公式不难发现,随机图的集聚系数并不高。此外,若在不改变的前提下,通过不断增加节点来提升图的规模,随着图规模的增大,集聚系数将不断降低。
3. 路径长度 Path length
路径长度的计算可结合图的广度优先遍历(BFS)进行思考。首先引入扩展性a,a 计算公式如下:
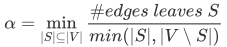
对扩展性为 a,规模为 n 的网络,存在长度为O((log n/a))的路径。
随机图具有很好的扩展性,因此BFS访问所有节点需要对数步O(log n)。
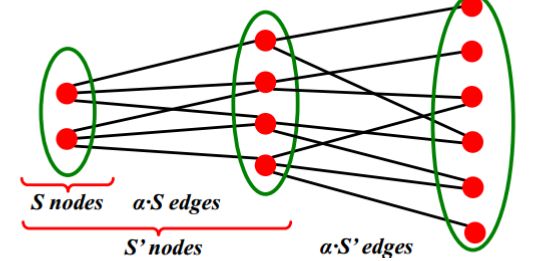
结合上述特性,可知对随机图而言,存在网络图规模很大,但平均最短路径仍然很短的现象,具体情况可参考下图。
4. 连通元件
随机图模型的结果随 p 值大小的变化可总结如下图:

课程中还对比了随机图模型与真实网络结构在上述四类属性上的差异,可总结为如下四点:
随机图模型低平均路径长这一点与真实世界网络模型契合;
度分布情况存在差异;
大多数真实网络中的巨型组件不会通过相变出现;
随机图模型集聚系数极低,缺乏局部结构。
综合来看,真实网络的结构和随机图模型还有很大差距,那为什么还要研究随机图模型?主要原因如下:
随机图模型是后续课程的基础,也是重要的参考模型;
随机图模型有助于我们通过比较更深入地认识真实网络数据;
随机图模型能帮助我们理解随机过程对网络结构能够产生多大程度的影响。
三、Small-World Model
小世界模型最经典的特征是既具有规则网络的高聚集性,又具有类似随机网络的小直径。相较随机图模型,小世界模型能够更好地反映真实网络的情况。
在介绍随机网络时提到,随机网络无法解释真实网络中存在的一些情况:局部集聚(较高的集聚系数)和三元闭合(朋友的朋友是朋友)。从网络结构来看,随机网络与真实网络的一大差异便是过低的集聚系数,所以在随机网络模型基础上进行改进时,需要要着重考虑的便是——如何在保留小网络直径这一特点的同时提高集聚系数,使得构建的模型能够对网络局部结构进行更好的刻画。

规则网络(上图左)在集聚系数和网络直径这两个属性上与随机网络(上图右)完全相反。小世界网络模型的构建则正是以此为基础,具体构建流程如下:
初始化:构建一个低维规则栅格网络,该网络具有高集聚系数;
重连:以固定概率 对连边进行重连,通过重连构建连接远部的近路。
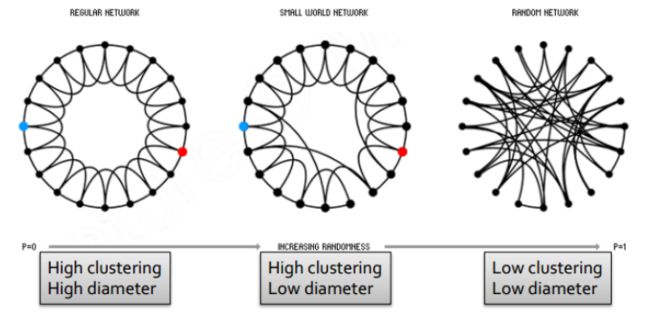
小世界网络的构建可以理解为在规则栅格网络和随机网络间进行内插,具体过程如上图所示。
想要进一步了解小世界网络模型,可以阅读Watts和Strogatz(1998年)、Newman和Watts(1999年)的两篇论文。
[1] Watts, D.J. and Strogatz, S.H. (1998) Collective dynamics of “small-world” networks. Nature, 393,
440-442.
[2] Newman, M.E.J. and Watts, D.J. (1999) Renormalization group analysis of the small-world network
model. Physics Letters A, 263, 341-346.
四、Kronecker Graph Model
Kronecker图模型就是产生大型真实网络的模型,这种模型的核心思想就是递归生成图。该模型特点是图的整体和该图的一个部分类似,也就是自相似(self-similarity)由于有这种特点,我们可以利用Kronecker积来对自身进行迭代。
下面是典型的Kronecker图模型的生成过程:
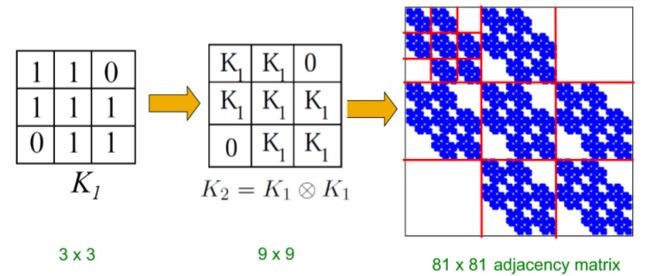
Kronecker积的定义:对于矩阵A(形状是N*M)和矩阵B(形状是K*L),那么这两个矩阵Kronecker积就是一个形状是N*KxM*L的矩阵:

也就是说,两个图的Kronecker积可以利用两个图的邻接矩阵的积得到。
举例来说假设有图A和图B,他们的邻接矩阵分别是Ma(形状是1x2)和Mb(形状是3x4)
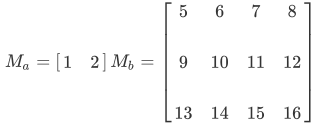
所以Kronecker积是:


通过上面我们看出的确存在子矩阵和原来矩阵成倍数关系的,所以存在递归子问题。
这样就可以通过上述方法得到Kronecker图模型。
五、Stochastic Kronecker Graph Model
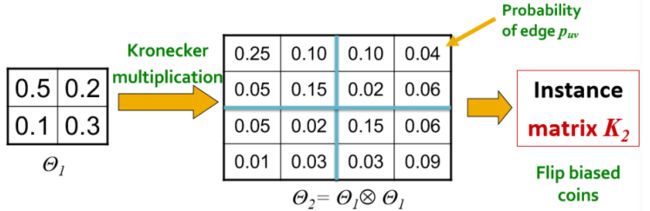
接下来介绍随机Kronecker图模型,这个模型和Kronecker图模型的区别就是在于初始化并不是用邻接矩阵,而是用概率矩阵来代替。
构建的算法流程是:
初始化一个 的概率矩阵;
计算概率矩阵 的 次Kronecker幂;
对于 的每个概率 就是边 的概率;
最后产生的概率矩阵就是随机Kronecker图。
有没有更快的产生随机Kronecker图的方法呢?
主要就是利用不同角度产生图的方法来进行生成,不断把每个单位的概率矩阵(初始化一个概率矩阵)放到象限中规定的行列((u,v))中,然后不断计算乘积对u,v不断更新然后产生的新坐标((x,y))就是图G对应行列的概率。

具体细节可以参考论文:
Kronecker Graphs: An Approach to Modeling Networks:
http://www.jmlr.org/papers/v11/leskovec10a.html
总结
本节介绍的网络属性和网络模型是网络研究的基础,熟练地掌握和应用能够提升对网络结构尤其是一些特殊网络结构的敏感度,有助于后续研究的深入。
作者简介:于媛,十三鸣
转自:数据派THU 公众号;
版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。
END
合作请加QQ:365242293
数据分析(ID : ecshujufenxi )互联网科技与数据圈自己的微信,也是WeMedia自媒体联盟成员之一,WeMedia联盟覆盖5000万人群。
