video analysis 论文阅读 P-GCN
Graph Convolutional Networks for Temporal Action Localization
作者从proposal之间的关系出发,首先构造一个action proposal图(将proposal作为节点,proposal之间的关系作为边),文中构造了两种边contextual edges和surrounding edges分别用于“提取上下文信息”和“描述不同action之间的相关性”。再用GCN建模学习强大的表示用于分类和定位。
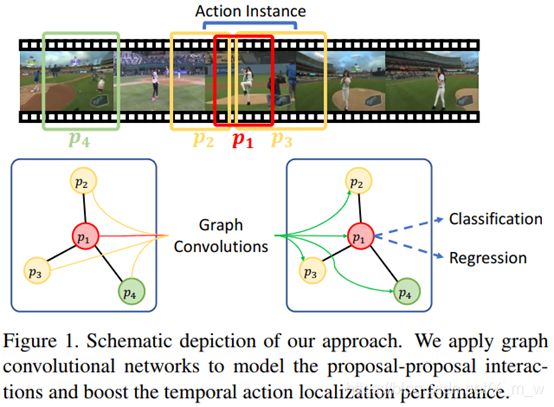
如图1,作者讲述了该方法的构想。对于已经生成的4个proposal,![]() 覆盖了同一个动作实例的不同部分,如果只针对
覆盖了同一个动作实例的不同部分,如果只针对![]() 进行预测,特征信息是不充分的,所以加入
进行预测,特征信息是不充分的,所以加入![]() 的特征,得到更多上下文的信息。另一方面,
的特征,得到更多上下文的信息。另一方面,![]() 描述背景信息(如运动场),它的内容可以帮助识别
描述背景信息(如运动场),它的内容可以帮助识别![]() 的动作标签。
的动作标签。
本文中将proposal作为节点并利用GCN建模proposal的关系,其中节点之间的边可以分为contextual edges(图1中的![]() )和surrounding edges(图1中的
)和surrounding edges(图1中的![]() )。虽然信息是从每一层的本地邻居聚合而来,但是如果GCNs的深度增加,在远程节点之间传递消息仍然是可能的。
)。虽然信息是从每一层的本地邻居聚合而来,但是如果GCNs的深度增加,在远程节点之间传递消息仍然是可能的。
主要贡献:
- 第一个利用proposal-proposal关系进行时间动作定位。
- 为了对提案之间的交互进行建模,将proposal作为节点,通过一些准则建立proposal之间的边,构建proposals图,然后应用GCNs在proposal之间做信息聚合。
3. Our Approach
3.1. Notation and Preliminaries
用![]() 表示一段未修饰的视频,其中高视频像素高H宽
表示一段未修饰的视频,其中高视频像素高H宽![]() 表示在时间t出的帧。用
表示在时间t出的帧。用![]() 表示动作proposal 分别表示开始和结束,
表示动作proposal 分别表示开始和结束,![]() 是用特征提取器(如I3D网络)从
是用特征提取器(如I3D网络)从![]() 提取的特征向量。
提取的特征向量。
用![]() 表示N个节点的图,节点
表示N个节点的图,节点![]() ,边
,边![]() ,邻接矩阵A
,邻接矩阵A![]() 。文中将每个proposal当作节点,将proposal之间的关系当作边,组成图
。文中将每个proposal当作节点,将proposal之间的关系当作边,组成图![]() 。
。
3.2. General Scheme of Our Approach
文章采用一个proposal图 表示proposal之间的关系,然后在图上应用GCN来开发关系并学习强大的proposal表示。在图卷积之后,每个节点聚合它邻近点的信息,以增强自身特征,最终帮助提高检测性能。
假定这些proposals通过一些方法(如TAG)预先得到的。文章目的是在给定一个输入视频V,通过探索proposal之间的关系来预测动作种类和时序位置:
![]()
其中F表示要学习的映射函数,模型P-GCN的整体架构如图2所示。
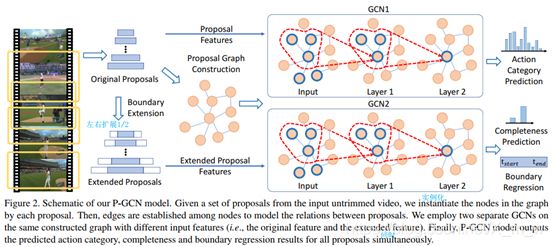
接下来主要讲解(1)如何构建图来表示proposal之间的关系;(2)如何使用GCN学习基于图的proposal表示,并帮助动作定位。
3.3. Proposal Graph Construction
每个视频的图![]() ,其节点是由动作proposal构成,关于边的构造,文章提出了两种边:contextual edges and surrounding edges。
,其节点是由动作proposal构成,关于边的构造,文章提出了两种边:contextual edges and surrounding edges。
contextual edges. 对于proposal ![]() ,如果
,如果![]() ,其中
,其中![]() 是设置的阈值。
是设置的阈值。![]() 表示proposal之间的相关性,由tIoU度量定义:
表示proposal之间的相关性,由tIoU度量定义:
![]() (2)
(2)
其中![]() 表示交集,
表示交集, ![]() 表示并集,可以看出这两种proposal之间是有高重叠度的。
表示并集,可以看出这两种proposal之间是有高重叠度的。
surrounding edges. 对于“不同却相近”的动作(包括background)也可以提供帮助。首先通过![]() 检索出“不同的(相离较远)”proposal,在计算如下的距离:
检索出“不同的(相离较远)”proposal,在计算如下的距离:
![]() (3)
(3)
然后通过![]() 选出“相近的”proposal,其中
选出“相近的”proposal,其中![]() 表示
表示![]() 的中心坐标。这样信息将跨不同的action实例传递,从而为检测提供更多的时间线索。
的中心坐标。这样信息将跨不同的action实例传递,从而为检测提供更多的时间线索。
3.4. Graph Convolution for Action Localization
基于以上的图,搭建一个K层的图卷积。对于第k层(1≤k≥K):
![]() (4)
(4)
其中A是邻接矩阵;![]() 是待学习的参数矩阵;
是待学习的参数矩阵;![]() 是在k层所有proposal的隐藏特征;
是在k层所有proposal的隐藏特征;![]() 是输入特征。
是输入特征。
在每个卷积层之后应用一个激活函数(ReLU)。此外,实验发现,通过进一步将隐藏特征与输入特征在最后一层连接起来,更有效:
![]() (5)
(5)
||表示连接操作。通过之前的工作发现,使用两个GCN——一个用原始的proposal特征![]() 做分类用;另一个用扩展后的特征
做分类用;另一个用扩展后的特征![]() 做定位用。对于proposal分别在左右边界扩宽1/2长度得到扩展后的特征
做定位用。对于proposal分别在左右边界扩宽1/2长度得到扩展后的特征![]()
第一个GCN如公式6,在![]() 之上用全连接层和softmax操作预测动作标签。
之上用全连接层和softmax操作预测动作标签。
![]() (6)
(6)
第二个GCN如公式7,8,在![]() 顶层之上用两个FC层,一个用来预测边界,另一个预测完整性。
顶层之上用两个FC层,一个用来预测边界,另一个预测完整性。
![]() (7)
(7)
![]() (8)
(8)
如果提案不完整,tIoU较低,且包含基本事实,则可能会导致分类分数较高,因此,仅使用分类分数对提案进行mAP测试排序时,就会出现错误;进一步应用完整性评分可以避免这个问题。
Adjacency Matrix. 这里通过给边分配特定的权值来得到邻接矩阵。例如利用余弦相似度来估计边的权值:
![]() (9)
(9)
计算邻接矩阵依靠特征向量,也可以在余弦计算之前,用一个可学习的线性映射函数将特征向量映射到embedding 空间。
3.5. Efficient Training by Sampling
通常一个视频会产生很多proposal,这样会很占内存和计算,为了加快训练,考虑之前的几个方法基于邻近点采样。这里采用了SAGE method
SAGE方法在自顶向下的通道中逐层均匀采样每个节点的固定大小的邻域,换句话说第(k-1)层的节点是通过采样该节点在第k层的邻近点得到的。在所有层的所有节点被采样后,SAGE以自底向上的方式执行信息聚合。这里指定聚合函数为Eq.(4)的采样形式:
![]() (10)
(10)
节点j是属于节点i的邻近点,![]() 是采样大小且远小于总结点数。并且我们还对式(10)中的节点i强制加入其自身特征。在测试时不进行采样,为了更好的可读性,算法1描述了我们方法的算法流程。
是采样大小且远小于总结点数。并且我们还对式(10)中的节点i强制加入其自身特征。在测试时不进行采样,为了更好的可读性,算法1描述了我们方法的算法流程。

实验:见原文