Spring学习笔记——IOC和DI
什么是IOC?
所谓控制反转,是将我们代码里面需要实现的创建对象,以及创建对象所依赖的对象的创建的过程,全部交由容器来进行实现。这样我们就不必使用new关键字来进行创建对象,从而降低了耦合度。
那么什么是DI呢?
2004年,Martin Fowler探讨了同一个问题,既然IOC是控制反转,那么到底“哪些方面的控制被反转了呢?”,经过详细的分析和讨论后,他得出了答案:“获得依赖对象的这个过程被反转了”。控制被反转之后,获得依赖对象由自身管理变为了由IOC容器主动注入。于是,他给控制反转取了一个更合适的名称:“依赖注入(Dependency Injection)”。他的这个答案,实际上就给出了IOC的实现方法:注入。所谓依赖注入,就是由IOC容器在运行期间,动态的将某种依赖注入到对象之中。不是对象从容器中查找依赖,而是容器在对象初始化时不等对象请求就主动将依赖传递给它。
那么如何理解Spring中的ioc和DI呢?
先来谈谈对IOC的理解。
- Spring中的IOC承担的作用,举个例子,现在我们有三个东西:人、房屋中介、房屋。人想要去租或者买一个房子的时候,首先需要找到房屋中介,在房屋中介处登记你的联系方式,当你需要房子的时候,房屋中介就会给你打电话说,房子已经安排上了,你提个包就去住吧。如果中介给我们的房子选不符合我们的预期,我们就会打电话向他投诉并抛出异常。整个过程不再由我自己控制,而是有中介这样一个类似容器的机构来控制。
- 上例中的人、房屋中介、房子就分别对应了Spring中的对象、IOC容器、以及依赖。就像房屋中间不仅登记了人的信息,同时也登记了空闲房间(依赖对象)的信息,Spring中的IOC容器中需要创建的对象和被依赖的对象也必须全部配置。这样才能在你需要依赖的时候,动态的将对象送过去。所有的类的创建、销毁都由 spring来控制,也就是说控制对象生存周期的不再是引用它的对象,而是spring。对于某个具体的对象而言,以前是它控制其他对象,现在是所有对象都被spring控制,所以这叫控制反转。
那么接下来我们来了解一下IOC实现的底层原理
- IOC底层主要使用的技术有
- xml配置文件
- Dom4j访问xml配置文件
- 工厂模式
- 反射
IOC的底层原理
在说IOC的底层原理之前,我们先来谈谈我们为什么要用IOC来管理对象。
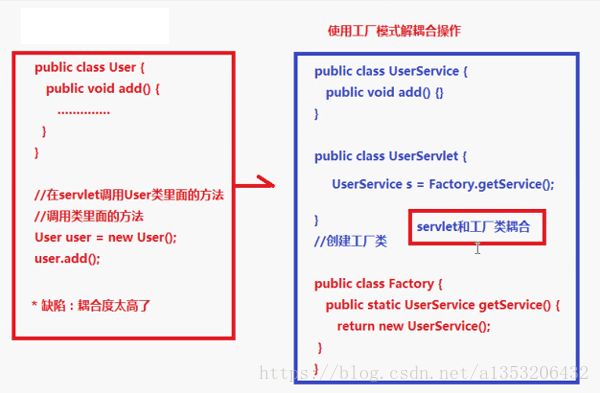
传统的创建对象都是通过new来对对象进行创建,但是这种硬编码的方式的耦合度太高,如上图红框部分,若是对User类进行修改,那么在其调用的地方也需要对其进行修改。我们这里只有两个类,所以修改起来并没有什么困难,但是当做一个大项目其中拥有很多类,并且类与类之间的相互引用特别多的时候,这种方式的维护代价就非常高了。
后来我们又使用工厂模式来进行一定程度的解耦,但是工厂又会和调用工厂的对象耦合在一起,还是有一定的缺陷。

- 先创建xml配置文件,配置创建对象类。
- 创建工厂类,我们依旧使用getService()方法来获得User对象,但是这里获得对象的方式与上面的工厂不同。这里首先使用classValue来获得bean中的class属性,即类的路径(和其所在的包),然后通过反射的方式来获得User的对象。
下面我我们通过具体的Demo来看理解Spring。
先创建一个User类,
package cn.itcast.ioc;
public class User {
private String username;
public void add() {
System.out.println("add.....");
}
}再xml文件中配置(使用了上述底层原理中的1xml配置文件)
然后再通过工厂的接口ApplicationContext来获取对象
package cn.itcast.ioc;
public class TestIoc {
@Test
public void TestUser() {
//1加载springp配置文件,根据配置文件创建对象
ApplicationContext context =
new ClassPathXmlApplicationContext("bean1.xml");
//2得到配置创建的对象
Userservice service = (Userservice)context.getBean("userService");
service.add();
}
}
输出结果为add。。。。。
ApplicationContext是BeanFactory的一个子接口,BeanFactory 可以理解为含有 bean 集合的工厂类。BeanFactory 包含了种 bean 的定义,以便在接收到客户端请求时将对应的 bean 实例化。
BeanFactory 还能在实例化对象的时生成协作类之间的关系。此举将bean 自身与 bean 客户端的配置中解放出来。BeanFactory 还包含了 bean 生命周期的控制,调用客户端的初始化方法(initialization methods)和销毁方法(destruction methods)。
这就对应了上面IOC理解中的一句话:
这样才能在你需要依赖的时候,动态的将对象送过去。所有的类的创建、销毁都由 spring来控制,也就是说控制对象生存周期的不再是引用它的对象,而是spring。
Spring通过反射的具体使用如下
public static Object newInstance(String className) {
Class cls = null;
Object obj = null;
try {
cls = Class.forName(className);
obj = cls.newInstance();
} catch (ClassNotFoundException e) {
throw new RuntimeException(e);
} catch (InstantiationException e) {
throw new RuntimeException(e);
} catch (IllegalAccessException e) {
throw new RuntimeException(e);
}
return obj;
}
Spring中对bean标签的管理:
Spring里边是通过配置文件来创建对象的,即其有IOC控制反转机制,每一个bean的实例化就是在创建一个对象。bean实例化有三种实现方式:
1.使用无参的构造方法来进行创建bean(最常用)
使用这种方法要求bean必须包含有无参的构造方法
2.使用静态工厂来创建bean
工厂实现:
public class Bean2Factory {
//静态方法,返回Bean2对象
public static Bean2 getBean2() {
return new Bean2();
}
}配置实现
3.使用实例工厂来创建bean
工厂实现
public class Bean3Factory{
public Bean3 getBean3(){
return new Bean3();
}
}配置实现
Bean标签的常用属性
1.id属性:起名称,id属性值任意命名
id属性值不能包含中文,不能包含特殊符号,根据id值得到配置对象,起到唯一标识符的作用
2.class属性:创建对象所在类的全路径
3.name属性:功能和id属性一样,都可以根据id或name得到对象,但id的属性值中不可以包含特殊符号,name中可以包含特殊符号(现已不常用)
4.scope属性:(前两个掌握,后两个了解)
* singleton :默认值,单例的.(即全局只会创建一个实例对象)
* prototype :多例的.
* request :WEB 项目中,Spring 创建一个Bean 的对象,将对象存入到request 域中.
* session :WEB 项目中,Spring 创建一个Bean 的对象,将对象存入到session 域中.
* globalSession :WEB 项目中,应用在Porlet 环境.如果没有Porlet 环境那么globalSession 相当
于session.*(登陆一次之后别的同类网页不需要再次登陆,单点登陆)
属性注入
在spring中只支持set方法和有参构造函数进行属性注入
有参构造函数注入
public class PropertyDemo {
private String username;
public PropertyDemo(String username) {
this.username = username;
}
public void test1() {
System.out.println("demo......."+username);
}
}在bean中配置
name的值必须要和需要注入的属性的名称相同,如需注入username,则name的值就是username
使用set方法注入属性
public class Book {
private String bookname;
public void setBookname(String bookname) {
this.bookname = bookname;
}
public void demobook() {
System.out.println(bookname);
}
}
配置
name的属性值是类里面定义的属性的名称,value属性用于设置具体的值
注入对象类型的属性(重点)
比如我现在创建了一个service类,我需要向service类中注入dao,即在service中得到dao对象
实现过程
创建UserService类
public class UserService{
private UserDao userDao;
public void setUserDao(UserDao userDao){
this.userDao = userDao;
}
public void add(){
System.out.println("My name is van");
}
}创建UserDao类
public class UserDao {
public void add() {
System.out.println("dao.........");
}
}在xml中配置

使用set方法注入基本数据类型时,property标签中使用的是value属性,而注入对象时则使用的就是ref属性了,且ref的值必须要和被注入对象在xml中配置的bean的id值相同。
两种注入方式的对比:
设值注入(set)有如下优点:
与传统的JavaBean的写法更相似,程序开发人员更容易理解、接受。通过setter方法设定依赖关系显得更加直观、自然;
对于复杂的依赖关系,如果采用构造注入,会导致构造器过于臃肿,难以阅读。Spring在创建Bean实例时,需要同时实例化其依赖的全部实例,因而导致性能下降。而使用设值注入,则能避免这些问题。
尤其在某些成员变量可选的情况下,多参数的构造器更加笨重。
构造注入优势如下:
构造注入可以在构造器中决定依赖关系的注入顺序,优先依赖的优先注入;
对于依赖关系无需变化的Bean,构造注入更有用处。因为没有setter方法,所有的依赖关系全部在构造器内设定,无须担心后续的代码对依赖关系产生破坏;
依赖关系只能在构造器中设定,则只有组件的创建者才能改变组件的依赖关系,对组件的调用者而言,组件内部的依赖关系完全透明,更符合高内聚的原则。
Notes建议采用设值注入为主,构造注入为辅的注入策略。对于依赖关系无须变化的注入,尽量采用构造注入;而其他依赖关系的注入,则考虑采用设值注入。
文章内容如有雷同,可能是我们看的教学视频是同一个啦~~~