【深度学习与tensorflow2.0实战】(网易云课堂)13-GAN
本文目录
- GAN原理
- 纳什均衡-D、G
- EM距离
- GAN实战
- **gan.py**
- dataset.py
GAN原理
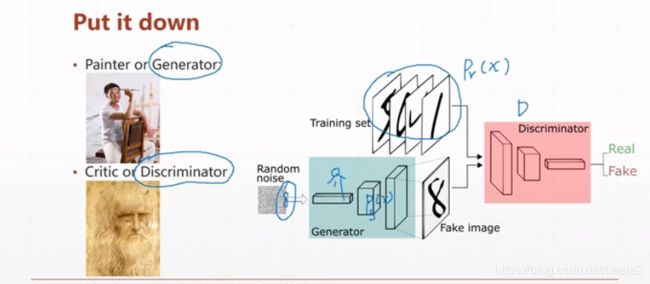

Having Fun
▪ https://reiinakano.github.io/gan-playground/
▪ https://affinelayer.com/pixsrv/
▪ https://www.youtube.com/watch?v=9reHvktowLY&feature=youtu.be
▪ https://github.com/ajbrock/Neural-Photo-Editor
▪ https://github.com/nashory/gans-awesome-applications
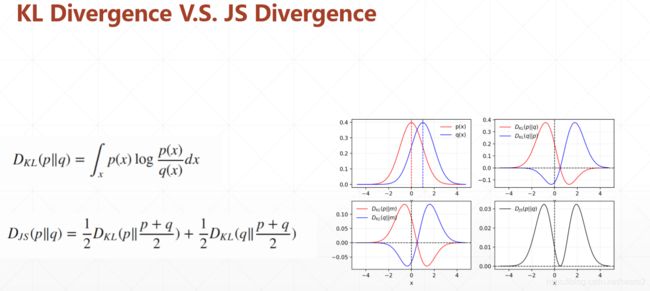
纳什均衡-D、G


图片变大
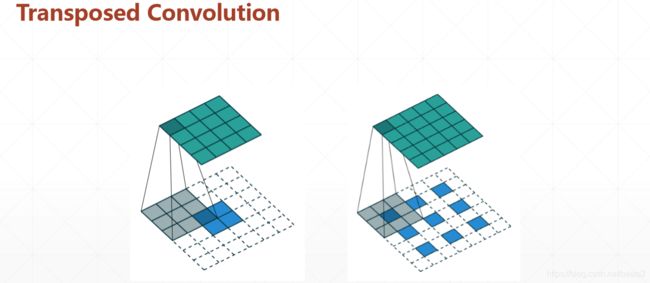
初始不会有overlap(重叠)
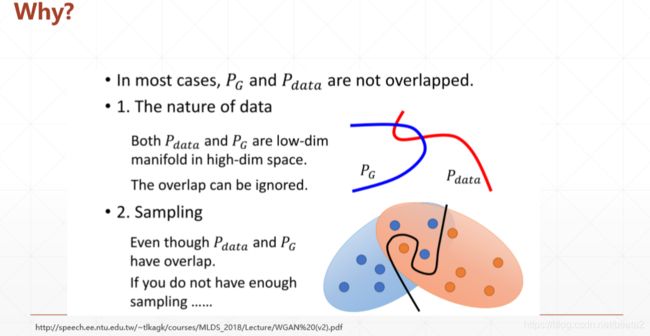

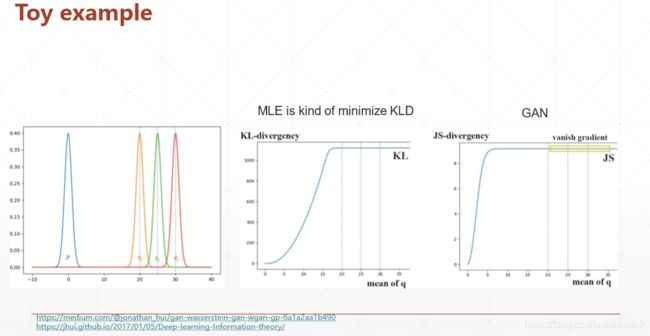


EM距离
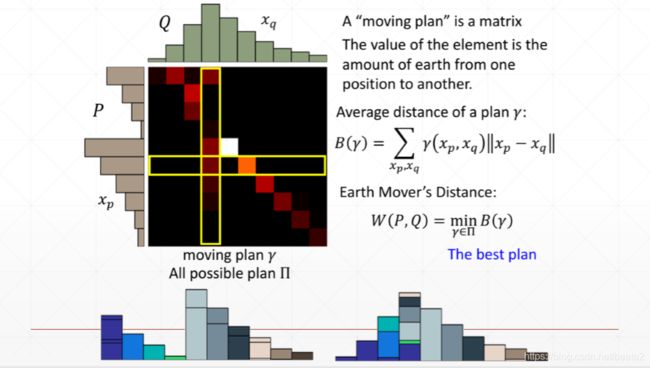
WD解决早期GAN不能convert的情况。梯度消失等问题




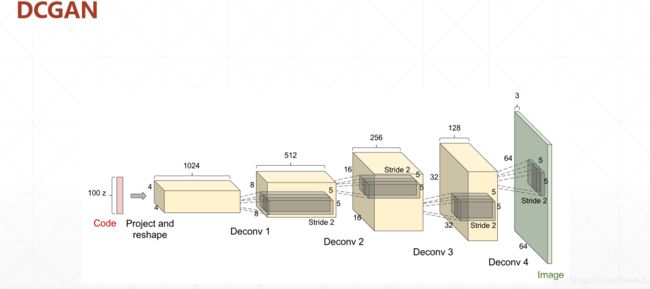
GAN实战

gan.py
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
class Generator(keras.Model):
def __init__(self):
super(Generator, self).__init__()
# z: [b, 100] => [b, 3*3*512] => [b, 3, 3, 512] => [b, 64, 64, 3]
self.fc = layers.Dense(3*3*512)
self.conv1 = layers.Conv2DTranspose(256, 3, 3, 'valid')
self.bn1 = layers.BatchNormalization()
self.conv2 = layers.Conv2DTranspose(128, 5, 2, 'valid')
self.bn2 = layers.BatchNormalization()
self.conv3 = layers.Conv2DTranspose(3, 4, 3, 'valid')
def call(self, inputs, training=None):
# [z, 100] => [z, 3*3*512]
x = self.fc(inputs)
x = tf.reshape(x, [-1, 3, 3, 512])
x = tf.nn.leaky_relu(x)
#
x = tf.nn.leaky_relu(self.bn1(self.conv1(x), training=training))
x = tf.nn.leaky_relu(self.bn2(self.conv2(x), training=training))
x = self.conv3(x)
x = tf.tanh(x)
return x
class Discriminator(keras.Model):
def __init__(self):
super(Discriminator, self).__init__()
# [b, 64, 64, 3] => [b, 1]
self.conv1 = layers.Conv2D(64, 5, 3, 'valid')
self.conv2 = layers.Conv2D(128, 5, 3, 'valid')
self.bn2 = layers.BatchNormalization()
self.conv3 = layers.Conv2D(256, 5, 3, 'valid')
self.bn3 = layers.BatchNormalization()
# [b, h, w ,c] => [b, -1]
self.flatten = layers.Flatten()
self.fc = layers.Dense(1)
def call(self, inputs, training=None):
x = tf.nn.leaky_relu(self.conv1(inputs))
x = tf.nn.leaky_relu(self.bn2(self.conv2(x), training=training))
x = tf.nn.leaky_relu(self.bn3(self.conv3(x), training=training))
# [b, h, w, c] => [b, -1]
x = self.flatten(x)
# [b, -1] => [b, 1]
logits = self.fc(x)
return logits
# 测试
def main():
d = Discriminator()
g = Generator()
x = tf.random.normal([2, 64, 64, 3])
z = tf.random.normal([2, 100])
prob = d(x)
print(prob)
x_hat = g(z)
print(x_hat.shape)
if __name__ == '__main__':
main()
dataset.py
# 加载数据集
import multiprocessing
import tensorflow as tf
def make_anime_dataset(img_paths, batch_size, resize=64, drop_remainder=True, shuffle=True, repeat=1):
@tf.function
def _map_fn(img):
img = tf.image.resize(img, [resize, resize])
img = tf.clip_by_value(img, 0, 255)
img = img / 127.5 - 1
return img
dataset = disk_image_batch_dataset(img_paths,
batch_size,
drop_remainder=drop_remainder,
map_fn=_map_fn,
shuffle=shuffle,
repeat=repeat)
img_shape = (resize, resize, 3)
len_dataset = len(img_paths) // batch_size
return dataset, img_shape, len_dataset
def batch_dataset(dataset,
batch_size,
drop_remainder=True,
n_prefetch_batch=1,
filter_fn=None,
map_fn=None,
n_map_threads=None,
filter_after_map=False,
shuffle=True,
shuffle_buffer_size=None,
repeat=None):
# set defaults
if n_map_threads is None:
n_map_threads = multiprocessing.cpu_count()
if shuffle and shuffle_buffer_size is None:
shuffle_buffer_size = max(batch_size * 128, 2048) # set the minimum buffer size as 2048
# [*] it is efficient to conduct `shuffle` before `map`/`filter` because `map`/`filter` is sometimes costly
if shuffle:
dataset = dataset.shuffle(shuffle_buffer_size)
if not filter_after_map:
if filter_fn:
dataset = dataset.filter(filter_fn)
if map_fn:
dataset = dataset.map(map_fn, num_parallel_calls=n_map_threads)
else: # [*] this is slower
if map_fn:
dataset = dataset.map(map_fn, num_parallel_calls=n_map_threads)
if filter_fn:
dataset = dataset.filter(filter_fn)
dataset = dataset.batch(batch_size, drop_remainder=drop_remainder)
dataset = dataset.repeat(repeat).prefetch(n_prefetch_batch)
return dataset
def memory_data_batch_dataset(memory_data,
batch_size,
drop_remainder=True,
n_prefetch_batch=1,
filter_fn=None,
map_fn=None,
n_map_threads=None,
filter_after_map=False,
shuffle=True,
shuffle_buffer_size=None,
repeat=None):
"""Batch dataset of memory data.
Parameters
----------
memory_data : nested structure of tensors/ndarrays/lists
"""
dataset = tf.data.Dataset.from_tensor_slices(memory_data)
dataset = batch_dataset(dataset,
batch_size,
drop_remainder=drop_remainder,
n_prefetch_batch=n_prefetch_batch,
filter_fn=filter_fn,
map_fn=map_fn,
n_map_threads=n_map_threads,
filter_after_map=filter_after_map,
shuffle=shuffle,
shuffle_buffer_size=shuffle_buffer_size,
repeat=repeat)
return dataset
def disk_image_batch_dataset(img_paths,
batch_size,
labels=None,
drop_remainder=True,
n_prefetch_batch=1,
filter_fn=None,
map_fn=None,
n_map_threads=None,
filter_after_map=False,
shuffle=True,
shuffle_buffer_size=None,
repeat=None):
"""Batch dataset of disk image for PNG and JPEG.
Parameters
----------
img_paths : 1d-tensor/ndarray/list of str
labels : nested structure of tensors/ndarrays/lists
"""
if labels is None:
memory_data = img_paths
else:
memory_data = (img_paths, labels)
def parse_fn(path, *label):
img = tf.io.read_file(path)
img = tf.image.decode_png(img, 3) # fix channels to 3
return (img,) + label
if map_fn: # fuse `map_fn` and `parse_fn`
def map_fn_(*args):
return map_fn(*parse_fn(*args))
else:
map_fn_ = parse_fn
dataset = memory_data_batch_dataset(memory_data,
batch_size,
drop_remainder=drop_remainder,
n_prefetch_batch=n_prefetch_batch,
filter_fn=filter_fn,
map_fn=map_fn_,
n_map_threads=n_map_threads,
filter_after_map=filter_after_map,
shuffle=shuffle,
shuffle_buffer_size=shuffle_buffer_size,
repeat=repeat)
return dataset
gan_train.py
import os
import numpy as np
import tensorflow as tf
from tensorflow import keras
from scipy.misc import toimage
import glob
from gan import Generator, Discriminator
from dataset import make_anime_dataset
def save_result(val_out, val_block_size, image_path, color_mode):
def preprocess(img):
img = ((img + 1.0) * 127.5).astype(np.uint8)
# img = img.astype(np.uint8)
return img
preprocesed = preprocess(val_out)
final_image = np.array([])
single_row = np.array([])
for b in range(val_out.shape[0]):
# concat image into a row
if single_row.size == 0:
single_row = preprocesed[b, :, :, :]
else:
single_row = np.concatenate((single_row, preprocesed[b, :, :, :]), axis=1)
# concat image row to final_image
if (b+1) % val_block_size == 0:
if final_image.size == 0:
final_image = single_row
else:
final_image = np.concatenate((final_image, single_row), axis=0)
# reset single row
single_row = np.array([])
if final_image.shape[2] == 1:
final_image = np.squeeze(final_image, axis=2)
toimage(final_image).save(image_path)
def celoss_ones(logits):
# [b, 1]
# [b] = [1, 1, 1, 1,]
loss = tf.nn.sigmoid_cross_entropy_with_logits(logits=logits,
labels=tf.ones_like(logits))
return tf.reduce_mean(loss)
def celoss_zeros(logits):
# [b, 1]
# [b] = [1, 1, 1, 1,]
loss = tf.nn.sigmoid_cross_entropy_with_logits(logits=logits,
labels=tf.zeros_like(logits))
return tf.reduce_mean(loss)
def d_loss_fn(generator, discriminator, batch_z, batch_x, is_training):
# 1. treat real image as real
# 2. treat generated image as fake
fake_image = generator(batch_z, is_training)
d_fake_logits = discriminator(fake_image, is_training)
d_real_logits = discriminator(batch_x, is_training)
d_loss_real = celoss_ones(d_real_logits)
d_loss_fake = celoss_zeros(d_fake_logits)
loss = d_loss_fake + d_loss_real
return loss
def g_loss_fn(generator, discriminator, batch_z, is_training):
fake_image = generator(batch_z, is_training)
d_fake_logits = discriminator(fake_image, is_training)
loss = celoss_ones(d_fake_logits)
return loss
def main():
tf.random.set_seed(22)
np.random.seed(22)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
assert tf.__version__.startswith('2.')
# hyper parameters
z_dim = 100
epochs = 3000000
batch_size = 512
learning_rate = 0.002
is_training = True
img_path = glob.glob(r'C:\Users\Jackie Loong\Downloads\DCGAN-LSGAN-WGAN-GP-DRAGAN-Tensorflow-2-master\data\faces\*.jpg')
dataset, img_shape, _ = make_anime_dataset(img_path, batch_size)
print(dataset, img_shape)
sample = next(iter(dataset))
print(sample.shape, tf.reduce_max(sample).numpy(),
tf.reduce_min(sample).numpy())
dataset = dataset.repeat()
db_iter = iter(dataset)
generator = Generator()
generator.build(input_shape = (None, z_dim))
discriminator = Discriminator()
discriminator.build(input_shape=(None, 64, 64, 3))
g_optimizer = tf.optimizers.Adam(learning_rate=learning_rate, beta_1=0.5)
d_optimizer = tf.optimizers.Adam(learning_rate=learning_rate, beta_1=0.5)
for epoch in range(epochs):
batch_z = tf.random.uniform([batch_size, z_dim], minval=-1., maxval=1.)
batch_x = next(db_iter)
# train D
with tf.GradientTape() as tape:
d_loss = d_loss_fn(generator, discriminator, batch_z, batch_x, is_training)
grads = tape.gradient(d_loss, discriminator.trainable_variables)
d_optimizer.apply_gradients(zip(grads, discriminator.trainable_variables))
# train G
with tf.GradientTape() as tape:
g_loss = g_loss_fn(generator, discriminator, batch_z, is_training)
grads = tape.gradient(g_loss, generator.trainable_variables)
g_optimizer.apply_gradients(zip(grads, generator.trainable_variables))
if epoch % 100 == 0:
print(epoch, 'd-loss:',float(d_loss), 'g-loss:', float(g_loss))
z = tf.random.uniform([100, z_dim])
fake_image = generator(z, training=False)
img_path = os.path.join('images', 'gan-%d.png'%epoch)
save_result(fake_image.numpy(), 10, img_path, color_mode='P')
if __name__ == '__main__':
main()