简介
分组(group by)一般是指三个过程
- 分割(Splitting)将数据按照某个标准分组
- 应用(Applying)对每个分组分别使用函数
- 组合(Combining)将结果组合成数据框
groupby对象
import pandas as pd
import numpy as np
df = pd.DataFrame({'A' : ['foo', 'bar', 'foo', 'bar',
'foo', 'bar', 'foo', 'foo'],
'B' : ['one', 'one', 'two', 'three',
'two', 'two', 'one', 'three'],
'C' : np.random.randn(8),
'D' : np.random.randn(8)})
gb.groupby('A')
print(df.groupby('A'))
at 0x00000000042F3470>
In [26]: gb.<TAB>
gb.agg gb.boxplot gb.cummin gb.describe gb.filter gb.get_group gb.height gb.last gb.median gb.ngroups gb.plot gb.rank gb.std gb.transform
gb.aggregate gb.count gb.cumprod gb.dtype gb.first gb.groups gb.hist gb.max gb.min gb.nth gb.prod gb.resample gb.sum gb.var
gb.apply gb.cummax gb.cumsum gb.fillna gb.gender gb.head gb.indices gb.mean gb.name gb.ohlc gb.quantile gb.size gb.tail gb.weight 分组迭代Iterating through groups
In [41]: grouped = df.groupby('A')
In [42]: for name, group in grouped:
....: print(name)
....: print(group)
....:
bar
A B C D
1 bar one -0.042379 -0.089329
3 bar three -0.009920 -0.945867
5 bar two 0.495767 1.956030
foo
A B C D
0 foo one -0.919854 -1.131345
2 foo two 1.247642 0.337863
4 foo two 0.290213 -0.932132
6 foo one 0.362949 0.017587
7 foo three 1.548106 -0.016692获得一个分组get_group
In [44]: grouped.get_group('bar')
Out[44]:
A B C D
1 bar one -0.042379 -0.089329
3 bar three -0.009920 -0.945867
5 bar two 0.495767 1.956030使用多种函数agg()
相同的函数
In [56]: grouped = df.groupby('A')
In [57]: grouped['C'].agg([np.sum, np.mean, np.std])
Out[57]:
sum mean std
A
bar 0.443469 0.147823 0.301765
foo 2.529056 0.505811 0.966450不同的函数
In [60]: grouped.agg({'C' : np.sum,
....: 'D' : lambda x: np.std(x, ddof=1)})
....:
Out[60]:
C D
A
bar 0.443469 1.490982
foo 2.529056 0.645875转变数据框transformation
转变函数(transform)中需要返回一个和分组块(group chunk)同样大小的结果,比如我们需要标准化每一个分组的数据:
In [66]: index = pd.date_range('10/1/1999', periods=1100)
In [67]: ts = pd.Series(np.random.normal(0.5, 2, 1100), index)
In [68]: ts = ts.rolling(window=100,min_periods=100).mean().dropna()
In [71]: key = lambda x: x.year#使用年来分组
In [72]: zscore = lambda x: (x - x.mean()) / x.std()#标准化
In [73]: transformed = ts.groupby(key).transform(zscore)#使用索引的年份来分组,然后标准化各组数据
In [80]: compare = pd.DataFrame({'Original': ts, 'Transformed': transformed})# 做出图形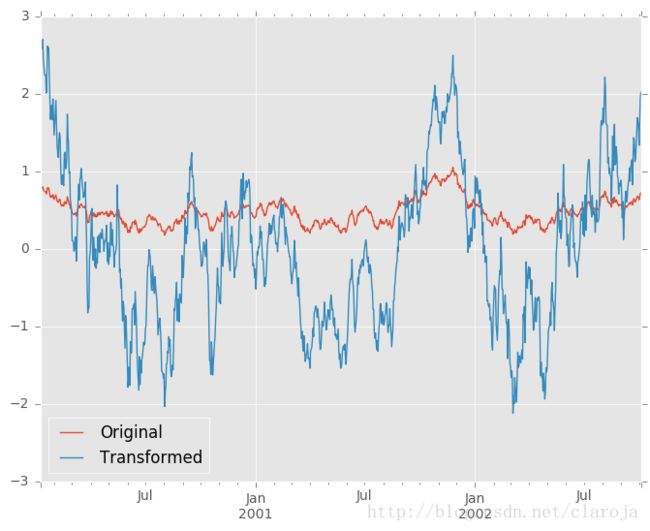
过滤Filtration
filter方法返回一个子集(subset)。比如我们只想要组长度大于2的分组:
In [105]: dff = pd.DataFrame({'A': np.arange(8), 'B': list('aabbbbcc')})
In [106]: dff.groupby('B').filter(lambda x: len(x) > 2)
Out[106]:
A B
2 2 b
3 3 b
4 4 b
5 5 b灵活运用apply
In [123]: df
Out[123]:
A B C D
0 foo one -0.919854 -1.131345
1 bar one -0.042379 -0.089329
2 foo two 1.247642 0.337863
3 bar three -0.009920 -0.945867
4 foo two 0.290213 -0.932132
5 bar two 0.495767 1.956030
6 foo one 0.362949 0.017587
7 foo three 1.548106 -0.016692
In [124]: grouped = df.groupby('A')
# could also just call .describe()
In [125]: grouped['C'].apply(lambda x: x.describe())
Out[125]:
A
bar count 3.000000
mean 0.147823
std 0.301765
min -0.042379
25% -0.026149
50% -0.009920
75% 0.242924
...
foo mean 0.505811
std 0.966450
min -0.919854
25% 0.290213
50% 0.362949
75% 1.247642
max 1.548106
Name: C, dtype: float64