CRF
1 基本知识点
(1)什么是马尔科夫随机过程和马尔科夫链
马尔科夫过程,是指下一个时间点的值只与当前值有关系,与以前没有关系,即未来决定于现在而不是过去。这种在已知 “现在”的条件下,“未来”与“过去”彼此独立的特性就被称为马尔科夫性,具有这种性质的随机过程就叫做马尔科夫过程,其最原始的模型就是马尔科夫链。
(2)什么是马尔科夫随机场
马尔可夫随机场(Markov Random Field)包含两层意思。
第一满足马尔可夫性质。
第二随机场:当给每一个位置中按照某种分布随机赋予相空间的一个值之后,其全体就叫做随机场。我们不妨拿种地来打个比方。其中有两个概念:位置(site),相空间(phase space)。“位置”好比是一亩亩农田;“相空间”好比是种的各种庄稼。我们可以给不同的地种上不同的庄稼,这就好比给随机场的每个“位置”,赋予相空间里不同的值。所以,俗气点说,随机场就是在哪块地里种什么庄稼的事情。
马尔可夫随机场:拿种地打比方,如果任何一块地里种的庄稼的种类仅仅与它邻近的地里种的庄稼的种类有关,与其它地方的庄稼的种类无关,那么这些地里种的庄稼的集合,就是一个马尔可夫随机场。
所以自己的理解马尔科夫随机场就是一个图模型中任意一条线中相邻的节点的值满足马尔科夫性质,
也就是空间上的马尔科夫链。
(3)什么是条件随机场
条件随机场,是给定随机变量X条件下,随机变量Y的马尔科夫随机场。重点强调的是隐变量Y满足马尔科夫随机场。
CRF是一个无向图的概率模型,顶点代表变量,顶点之间的边代表两个变量之间依赖关系。常用的是链式CRF结构,如此可以表达长距离依赖性,和交叠特征的能力。所有特征可以进行全局归一化,得到全局最优解
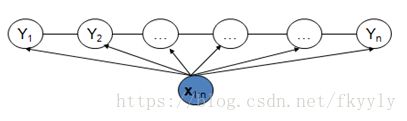
上图显示CRF模型解决了标注偏置问题,去除了HMM中两个不合理的假设。当然,模型相应得也变复杂了
1 CRF模型具有以下特点:
(1)CRF在给定了观察序列的情况下,对整个的序列的联合概率有一个统一的指数模型,它具备一个比较吸引人的特性就是其损失函数的凸面性;
(2)CRF具有很强的推理能力,并且能够使用复杂、有重叠性和非独立的特征进行训练和推理,能够充分地利用上下文信息作为 特征,还可以任意地添加其他外部特征,使得模型能够获取的信息非常丰富;
(3)CRF解决了MEMM中的标记偏置问题,这也正是CRF与MEMM的本质区别所在—-最大熵模型在每个状态都有一个概率模型,在每个状态转移时都要进行归一化。如果某个状态只有一个后续 状态,那么该状态到后续状态的跳转概率即为1。这样,不管输入为任何内容,它都向该后续状态跳转。而CRFs是在所有的状态上建立一个统一的概率模型,这 样在进行归一化时,即使某个状态只有一个后续状态,它到该后续状态的跳转概率也不会为1。
2 具体计算过程:
- step1. 先预定义特征函数 ,
- step2. 在给定的数据上,训练模型,确定参数
- step3. 用确定的模型做
序列标注问题或者序列求概率问题。
了解CRF的同学肯定都知道CRF是判别模型,给定一个句子s,要求出句子的标记,就是找出一个标记序列l,使得P(l|s)概率最大。
这里n是所有可能的标记序列数量,以中文切词为例,假设切分标记为B、E、M、S,待切分的句子长度为m,那标记序列的数量就是4的m次方。
那么只要我们能求出是每个标记序列l的概率 P(l|s),然后取概率最大的l,也就求出了最终的标记序列。
假设我们在训练阶段已经得到了每个特征对应的权重值,那么对于待标记的句子s,我们可以通过以下公式计算出每个标记序列l的得分:

(公式上第一个求和对应特征数,第二个求和对应句子长度即词的数量)
最终,我们可以通过指数函数和归一化,将分数转换成概率,公式如下

上述算法的很容易理解,但是通过枚举所有可能的标记序列,计算时间长,所以我们在几乎所有介绍CRF的资料上,都是用维特比算法求解。
3 CRF特征说明
对于CRF,可以为他定义两款特征函数:转移特征(隐藏层与隐藏层间)&状态特征(隐藏层)。 我们将建模总公式展开:
其中:
- 为i处的转移特征,对应权重 ,每个 都有J个特征,转移特征针对的是前后token之间的限定。
- 举个例子:
- sl为i处的状态特征,对应权重μl,每个tokeni都有L个特征
- 举个例子:
特征表达方式:有两种,转移特征,两个状态之间的。另一种是状态特征。CRF学习的过程就是描述一些特征配置:当前词语是xx,上个词xx,满足这种配置的,特征函数输出就是1,不然是0.然后这些特征每个都有一个权重,要学习的就是这些权重。
4 学习训练过程
一套CRF由一套参数λ唯一确定(先定义好各种特征函数)。其实就是学习特征的权值。
其学习方法(目标函数)可以使用极大似然估计或者正则化的极大似然估计。 具体优化实现算法有改进的迭代尺度法IIS、梯度下降法以及拟牛顿法、IIS、BFGS、L-BFGS等等。各位应该对各种优化方法有所了解的。其实能用在log-linear models上的求参方法都可以用过来。
已知训练数据集,由此可知经验概率分布
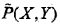
可以通过极大化训练数据的对数似然函数来求模型参数。
训练数据的对数似然函数为
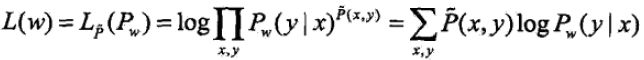
当Pw是一个由

给出的条件随机场模型时,对数似然函数为
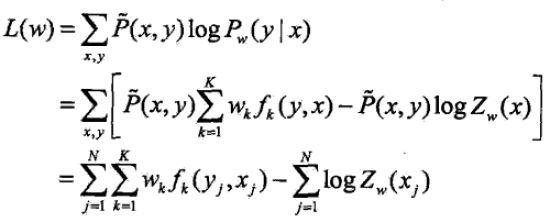
5 序列标注过程,预测过程,维特比算法
还是跟HMM一样的,用学习好的CRF模型,在新的sample(观测序列 )上找出一条概率最大最可能的隐状态序列 。
只是现在的图中的每个隐状态节点的概率求法有一些差异而已,正确将每个节点的概率表示清楚,路径求解过程还是一样,采用viterbi算法。
啰嗦一下,我们就定义i处的局部状态为 ,表示在位置i处的隐状态的各种取值可能为I,然后递推位置i+1处的隐状态,写出来的DP转移公式为:
这里没写规范因子 是因为不规范化不会影响取最大值后的比较。
具体还是不展开为好。
维特比算法就是:按照递推公式整条链计算完之后,就知道最后一个词最可能是哪个标签,以及如果去掉这个标签的话上一个词的标签是什么,以此类推。
条件随机场的预测问题是给定条件随机场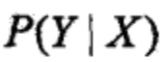 和输入序列(观测序列)x,求条件概率最大的输出序列(标记序列)
和输入序列(观测序列)x,求条件概率最大的输出序列(标记序列)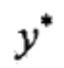 ,即对观测序列进行标注。条件随机场的预测算法是著名的维特比算法。
,即对观测序列进行标注。条件随机场的预测算法是著名的维特比算法。
由式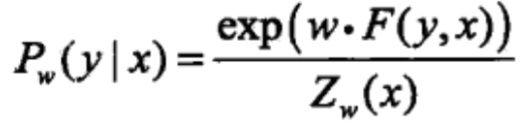 可得:
可得:
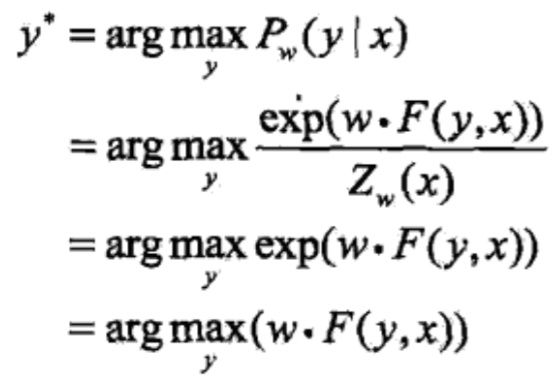
于是,条件随机场的预测问题成为求非规范化概率最大的最优路径问题
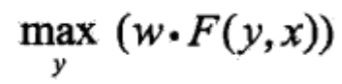
这里,路径表示标记序列。其中,
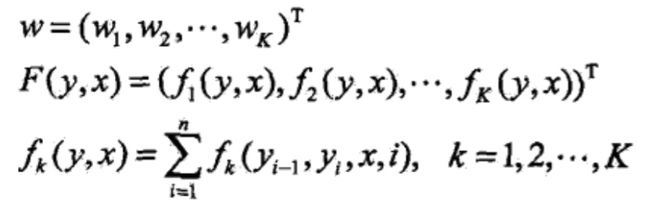
注意,这时只需计算非规范化概率,而不必计算概率,可以大大提高效率。为了求解最优路径,将写成如下形式:
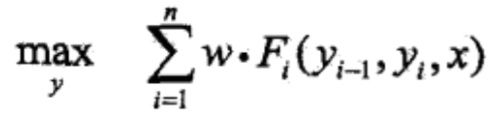
其中,
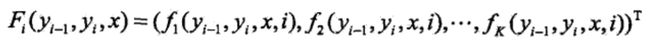
是局部特征向量。
下面叙述维特比算法。首先求出位置1的各个标记j=1,2,…,m的非规范化概率:
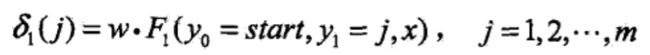
一般地,由递推公式,求出到位置》。的各个标记/=l,2,。。。,m的非规范化概率的最大值,同时记录非规范化概率最大值的路径
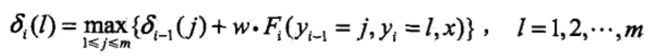
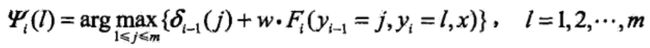
直到 时终止。这时求得非规范化概率的最大值为
时终止。这时求得非规范化概率的最大值为
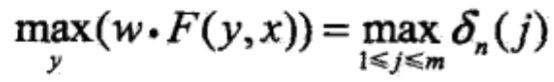
及最优路径的终点
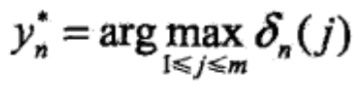
由此最优路径终点返回,
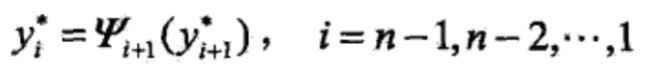
求得最优路径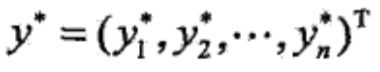 。
。
综上所述,得到条件随机场预测的维特比算法:
算法(条件随机场预测的维特比算法)
输入:模型特征向量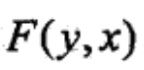 和权值向量
和权值向量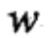 ,观测序列
,观测序列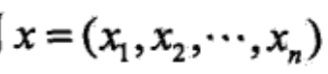
输出:最优路径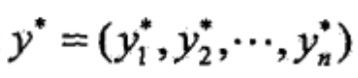 。
。
(1)初始化
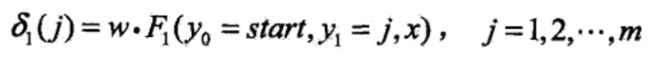
(2)递推。对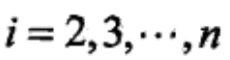
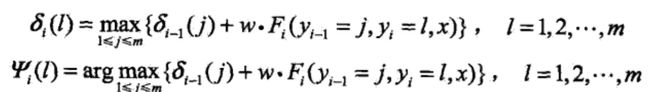
(3)终止
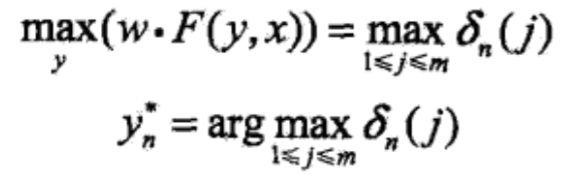
(4)返回路径
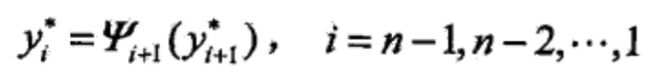
求得最优路径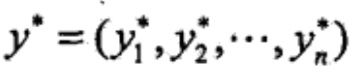 。
。
6 序列求概率过程
跟HMM举的例子一样的,也是分别去为每一批数据训练构建特定的CRF,然后根据序列在每个MEMM模型的不同得分概率,选择最高分数的模型为wanted类别。只是貌似很少看到拿CRF或者MEMM来做分类的,直接用网络模型不就完了不……
7 CRF和hmm的区别是:
(1)CRF没有那两个假设
(2)hmm生成式模型,crf判别式模型
为了建一个条件随机场,我们首先要定义一个特征函数集,每个特征函数都以整个句子s,当前位置i,位置i和i-1的标签为输入。然后为每一个特征函数赋予一个权重,然后针对每一个标注序列l,对所有的特征函数加权求和,必要的话,可以把求和的值转化为一个概率值![]()
1)HMM是假定满足HMM独立假设。CRF没有,所以CRF能容纳更多上下文信息。
2)CRF计算的是全局最优解,不是局部最优值。
3)CRF是给定观察序列的条件下,计算整个标记序列的联合概率。而HMM是给定当前状态,计算下一个状态。
4)CRF比较依赖特征的选择和特征函数的格式,并且训练计算量大
8 CRF与逻辑回归的比较
观察公式:
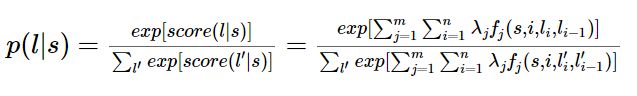
是不是有点逻辑回归的味道?
事实上,条件随机场是逻辑回归的序列化版本。逻辑回归是用于分类的对数线性模型,条件随机场是用于序列化标注的对数线性模型。
https://www.jianshu.com/p/55755fc649b1
https://blog.csdn.net/QFire/article/details/81065256
http://www.hankcs.com/ml/conditional-random-field.html
https://www.cnblogs.com/lijieqiong/p/6673692.html
https://blog.csdn.net/xueyingxue001/article/details/51499087/
http://www.mamicode.com/info-detail-2307425.html