MXnet代码实战之CNN
介绍
CNN指的是卷积神经网络,这个介绍网上资料多的很,我就不介绍了,我这里主要是针对沐神教程的CNN代码做一个笔记。理解有不对的地方欢迎指出。
卷积神经网络里面最重要也是最基本的概念就是卷积层、池化层、全连接层、卷积核、参数共享等。
图:
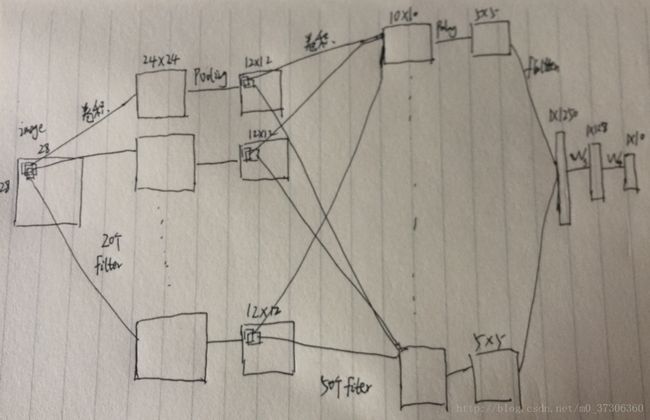
这个图是对下面代码的一个描述,对于一张图片,首先处理成28*28(这里一张图片只有一个通道)。通过第一层卷积层,得到20个通道的输出(每个输出为24*24),所以第一层的卷积核是X*X的(这里我写X只是想说明卷积核的size,后面也是这个意思),有20个这样的卷积核。再通过第一个池化层,得到20个12*12的输出。第二层卷积层:输入有20个通道,输出有50个通道,所以这里有50个filter(卷积核),每一个filter是X*X*20,可以想象成立体的,意思是这一层的卷积核是立体的卷积核,每一个卷积核都会去卷前面12*12*20的输入,每一个卷积核卷完得到一个输出(这里输出为10*10),所以要得到50个10*10的输出需要50个这样的filter。通过第二个池化层得到50个5*5的输出。然后就是flatten层,意思是把它们拉开成一条向量,所以就是5*5*50=1250啦。后面又接了二个全连接层,最终输出为1*10,正好对应10类(有多少类别都就通过全连接层处理成多少类)。其实这个就是常用的LeNet。
从0开始实现CNN
代码:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
#Author: yuquanle
#2017/10/28
#沐神教程实战之CNN
# 其实就是简单的LeNet雏形
#本例子使用FashionMNIST数据集
from mxnet import nd
from mxnet import gluon
# 处理输入数据
def transform_mnist(data, label):
# change data from height x weight x channel to channel x height x weight
return nd.transpose(data.astype('float32'), (2,0,1))/255, label.astype('float32')
def load_data_fashion_mnist(batch_size, transform=transform_mnist):
"""download the fashion mnist dataest and then load into memory"""
mnist_train = gluon.data.vision.FashionMNIST(
train=True, transform=transform)
mnist_test = gluon.data.vision.FashionMNIST(
train=False, transform=transform)
train_data = gluon.data.DataLoader(
mnist_train, batch_size, shuffle=True)
test_data = gluon.data.DataLoader(
mnist_test, batch_size, shuffle=False)
return (train_data, test_data)
# 载入数据
batch_size = 256
train_data, test_data = load_data_fashion_mnist(batch_size)
import mxnet as mx
# 优先使用GPU运算
try:
ctx = mx.gpu()
_ = nd.zeros((1,), ctx=ctx)
except:
ctx = mx.cpu()
weight_scale = .01
# output channels = 20, kernel = (5,5)
W1 = nd.random_normal(shape=(20,1,5,5), scale=weight_scale, ctx=ctx)
b1 = nd.zeros(W1.shape[0], ctx=ctx)
# output channels = 50, kernel = (3,3)
W2 = nd.random_normal(shape=(50,20,3,3), scale=weight_scale, ctx=ctx)
b2 = nd.zeros(W2.shape[0], ctx=ctx)
# output dim = 128
W3 = nd.random_normal(shape=(1250, 128), scale=weight_scale, ctx=ctx)
b3 = nd.zeros(W3.shape[1], ctx=ctx)
# output dim = 10
W4 = nd.random_normal(shape=(W3.shape[1], 10), scale=weight_scale, ctx=ctx)
b4 = nd.zeros(W4.shape[1], ctx=ctx)
params = [W1, b1, W2, b2, W3, b3, W4, b4]
for param in params:
param.attach_grad()
# 定义模型
def net(X, verbose=False):
X = X.as_in_context(W1.context)
# 第⼀层卷积,kernel为5*5,filter有20个,所以卷积输出有20个通道
h1_conv = nd.Convolution( data=X, weight=W1, bias=b1, kernel=W1.shape[2:], num_filter=W1.shape[0])
# 激活函数
h1_activation = nd.relu(h1_conv)
# 池化
h1 = nd.Pooling(data=h1_activation, pool_type="max", kernel=(2, 2), stride=(2, 2))
# 第⼆层卷积,kernel为3*3,filter有50个,所以卷积输出有50个通道。输入有20个通道,所以每一个filter会卷积20个通道,然后求和
h2_conv = nd.Convolution(data=h1, weight=W2, bias=b2, kernel=W2.shape[2:], num_filter=W2.shape[0])
h2_activation = nd.relu(h2_conv)
h2 = nd.Pooling(data=h2_activation, pool_type="max", kernel=(2, 2), stride=(2, 2))
# flatten成向量
h2 = nd.flatten(h2)
# 第⼀层全连接
h3_linear = nd.dot(h2, W3) + b3
h3 = nd.relu(h3_linear)
# 第⼆层全连接
h4_linear = nd.dot(h3, W4) + b4
if verbose:
print('X:',X.shape)
print('h1_conv:', h1_conv.shape)
print('1st conv block:', h1.shape)
print('h2_conv:', h2_conv.shape)
print('2nd conv block:', h2.shape)
print('1st dense:', h3.shape)
print('2nd dense:', h4_linear.shape)
print('output:', h4_linear)
return h4_linear
# 查看信息
for data, _ in train_data:
print(data.shape)
net(data, verbose=True)
break
def evaluate_accuracy(data_iterator, net, ctx=mx.cpu()):
acc = 0.
for data, label in data_iterator:
output = net(data.as_in_context(ctx))
acc += accuracy(output, label.as_in_context(ctx))
return acc / len(data_iterator)
from mxnet import autograd as autograd
from utils import SGD, accuracy
from mxnet import gluon
#
#
softmax_cross_entropy = gluon.loss.SoftmaxCrossEntropyLoss()
learning_rate = .2
for epoch in range(5):
train_loss = 0.
train_acc = 0.
for data, label in train_data:
label = label.as_in_context(ctx)
with autograd.record():
output = net(data)
loss = softmax_cross_entropy(output, label)
loss.backward()
SGD(params, learning_rate / batch_size)
train_loss += nd.mean(loss).asscalar()
train_acc += accuracy(output, label)
test_acc = evaluate_accuracy(test_data, net, ctx)
print("Epoch %d. Loss: %f, Train acc %f, Test acc %f" % (
epoch, train_loss / len(train_data),
train_acc / len(train_data), test_acc))
使用Gluon
代码:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
#Author: yuquanle
#2017/10/28
#沐神教程实战之CNN,使用Gluon
#本例子使用FashionMNIST数据集
from mxnet import gluon
from time import time
# 处理输入数据
def transform_mnist(data, label):
# change data from height x weight x channel to channel x height x weight
return nd.transpose(data.astype('float32'), (2,0,1))/255, label.astype('float32')
def load_data_fashion_mnist(batch_size, transform=transform_mnist):
"""download the fashion mnist dataest and then load into memory"""
mnist_train = gluon.data.vision.FashionMNIST(
train=True, transform=transform)
mnist_test = gluon.data.vision.FashionMNIST(
train=False, transform=transform)
train_data = gluon.data.DataLoader(
mnist_train, batch_size, shuffle=True)
test_data = gluon.data.DataLoader(
mnist_test, batch_size, shuffle=False)
return (train_data, test_data)
# 获取数据
batch_size = 256
train_data, test_data = load_data_fashion_mnist(batch_size)
# 定义模型
from mxnet.gluon import nn
net = nn.Sequential()
with net.name_scope():
net.add(
nn.Conv2D(channels=20, kernel_size=5, activation='relu'),
nn.MaxPool2D(pool_size=2, strides=2),
nn.Conv2D(channels=50, kernel_size=3, activation='relu'),
nn.MaxPool2D(pool_size=2, strides=2),
nn.Flatten(),
nn.Dense(128, activation="relu"),
nn.Dense(10)
)
# 初始化
from mxnet import autograd
from mxnet import nd
import mxnet as mx
# 优先使用GPU运算
try:
ctx = mx.gpu()
_ = nd.zeros((1,), ctx=ctx)
except:
ctx = mx.cpu()
net.initialize(ctx=ctx)
print('initialize weight on', ctx)
def _get_batch(batch, ctx):
"""return data and label on ctx"""
if isinstance(batch, mx.io.DataBatch):
data = batch.data[0]
label = batch.label[0]
else:
data, label = batch
return (gluon.utils.split_and_load(data, ctx),
gluon.utils.split_and_load(label, ctx),
data.shape[0])
def evaluate_accuracy(data_iterator, net, ctx=[mx.cpu()]):
if isinstance(ctx, mx.Context):
ctx = [ctx]
acc = nd.array([0])
n = 0.
if isinstance(data_iterator, mx.io.MXDataIter):
data_iterator.reset()
for batch in data_iterator:
data, label, batch_size = _get_batch(batch, ctx)
for X, y in zip(data, label):
acc += nd.sum(net(X).argmax(axis=1)==y).copyto(mx.cpu())
acc.wait_to_read() # don't push too many operators into backend
n += batch_size
return acc.asscalar() / n
def train(train_data, test_data, net, loss, trainer, ctx, num_epochs, print_batches=None):
"""Train a network"""
print("Start training on ", ctx)
if isinstance(ctx, mx.Context):
ctx = [ctx]
for epoch in range(num_epochs):
train_loss, train_acc, n = 0.0, 0.0, 0.0
if isinstance(train_data, mx.io.MXDataIter):
train_data.reset()
start = time()
for i, batch in enumerate(train_data):
data, label, batch_size = _get_batch(batch, ctx)
losses = []
with autograd.record():
outputs = [net(X) for X in data]
losses = [loss(yhat, y) for yhat, y in zip(outputs, label)]
for l in losses:
l.backward()
train_acc += sum([(yhat.argmax(axis=1)==y).sum().asscalar()
for yhat, y in zip(outputs, label)])
train_loss += sum([l.sum().asscalar() for l in losses])
trainer.step(batch_size)
n += batch_size
if print_batches and (i+1) % print_batches == 0:
print("Batch %d. Loss: %f, Train acc %f" % (
n, train_loss/n, train_acc/n
))
test_acc = evaluate_accuracy(test_data, net, ctx)
print("Epoch %d. Loss: %.3f, Train acc %.2f, Test acc %.2f, Time %.1f sec" % (
epoch, train_loss/n, train_acc/n, test_acc, time() - start
))
# 训练和测试
loss = gluon.loss.SoftmaxCrossEntropyLoss()
trainer = gluon.Trainer(net.collect_params(),'sgd', {'learning_rate': 0.5})
train(train_data, test_data, net, loss, trainer, ctx, num_epochs=5)
结果:
initialize weight on gpu(0)
Start training on gpu(0)
[10:50:57] d:\program files (x86)\jenkins\workspace\mxnet\mxnet\src\operator\./cudnn_algoreg-inl.h:106: Running performance tests to find the best convolution algorithm, this can take a while... (setting env variable MXNET_CUDNN_AUTOTUNE_DEFAULT to 0 to disable)
Epoch 0. Loss: 1.140, Train acc 0.57, Test acc 0.80, Time 14.0 sec
Epoch 1. Loss: 0.457, Train acc 0.83, Test acc 0.82, Time 13.3 sec
Epoch 2. Loss: 0.380, Train acc 0.86, Test acc 0.77, Time 17.2 sec
Epoch 3. Loss: 0.342, Train acc 0.87, Test acc 0.87, Time 17.2 sec
Epoch 4. Loss: 0.311, Train acc 0.88, Test acc 0.88, Time 16.9 sec
Process finished with exit code 0