微信群分享:用Python模拟知乎自动登录
Python语言是由Guido van Rossum大牛在1989年发明,它是当今世界最受欢迎的计算机编程语言之一,也是一门“学了有用、学了能用、学会能久用”的计算生态语言。
为此,CSDN作为国内最大的IT中文社区,特向广大Python爱好者开设了Python学习班,帮助大家在学习的道路上少走弯路,事半功倍。3月29号晚上8点,我们特邀请知名Python技术专家刘志军老师在班级里举行分享活动。
刘志军,6年开发经验,曾就职中兴、博雅互动。擅长Web技术架构,对爬虫、数据挖掘领域兴趣浓厚。目前在一家大型医药集团从事数据分析工作。微信公众号:Python之禅(vttalk)
以下为昨晚的分享内容:
前言
文章会按照先原理,再实践的方式来讲解,希望可以做到知其然且知其所以然,读这篇文章前,你需要对 HTTP 协议、
Cookies、跨站请求伪造(CSRF)有一定了解,如果你不太了解这些概念,文末给出了两个链接推荐阅读。
在做爬虫时,有些页面在登录之前,是被禁止抓取的,比如我们查看知乎的话题页面 https://www.zhihu.com/topic 就要求我
们登录。
当提到「登录」时,就不得不提 Cookie 技术,而说起 Cookie 技术时,还得从 HTTP 协议说起。当然在这里我不会把
HTTP 从0到1讲一遍,你只需要了解基本的 HTTP 流程是什么就可以了,推荐阅读我之前在公众号「Python之禅」中写的
另一篇文章一次完整的HTTP请求过程
HTTP 是一种无状态的协议, 协议本身不保留之前的一切请求信息和响应信息,也就是说,对于一个刚刚发送了 HTTP 请求
的客户端再次发起请求时,服务端并不知道之前访问过。这样设计的理由是为了更快地处理大量事务,确保协议的可伸缩
性,而特意把 HTTP 协议设计如此简单。
但是,无状态导致业务处理就变得棘手了,一个简单的例子就是网上购物的时候,当我在一个页面把商品加入购物车的时
候,正当我要跳转到支付页面时,如果没有一种机制来保持我的登录状态,那么之前选的商品全部丢失了。
因此,为了在无状态的 HTTP 协议之上维护会话状态,使服务器可以知道当前是和哪个客户端打交道,于是Cookie 技术应
运而生 ,Cookie 通俗的理解就是服务端分配给客户端的一个标识。
Cookie原理其实也非常简单,总共4个步骤维护HTTP会话。 
1. 浏览器第一次发起 HTTP 请求时,没有携带任何 Cookie 信息,服务器收到请求并返回给浏览器的HTTP响应,同时
HTTP 响应包括了一个响应头 Set-Cookie 字段,它的值是要设置的 Cookie。
2. 浏览器收到来自服务器的 HTTP 响应,响应头中发现有 Set-Cookie 字段,就会将该字段的值保存在内存或者硬盘中。
3. 浏览器下次给该服务器发送 HTTP 请求时, 会将 Cookie 信息附加在 HTTP 请求的头字段 Cookie 中。
4. 服务器收到这个HTTP请求,发现请求头中有Cookie字段, 便知道之前就和这个用户打过交道了。
理解了 Cookie 的基本原理之后,我们就可以尝试用 Python 来实现模拟知乎登录。
用过知乎的都知道,只要提供用户名和密码以及验证码之后即可登录。当然,这只是我们眼中看到的,而背后隐藏的技术细
节还需要借助浏览器来发觉。现在我们就用 Chrome 来查看当我们填完表单后,点击登录的时候究竟发生了什么? 
首先进入知乎的登录页面 https://www.zhihu.com/#signin ,打开 Chrome 的开发者工具条(按 F12)先尝试输入一个错误的
验证码观察浏览器是如何发送请求的。 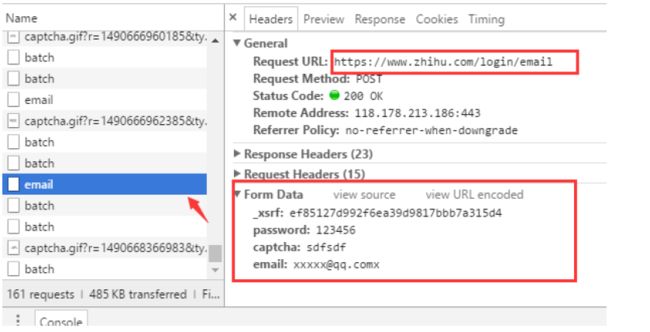
从浏览器的请求可以发现几个关键的信息
1. 登录的 URL 地址是 https://www.zhihu.com/login/email
2. 登录需要提供的表单数据有4个:用户名(email)、密码(password)、验证码(captcha)、_xsrf。
3. 获取验证码的URL地址是 https://www.zhihu.com/captcha.gif?r=1490690391695&type=login
那么 _xsrf 参数是什么?如果你对CSRF(跨站请求伪造)攻击非常熟悉的话,那么你一定知道它的作用,xsrf是一串伪随机
数,它是用于防止跨站请求伪造的。它一般存在网页的 form 表单标签中,为了证实这一点,可以在页面上搜索 “xsrf”,果
然,从下图可以看到 _xsrf在一个隐藏的 input 标签中 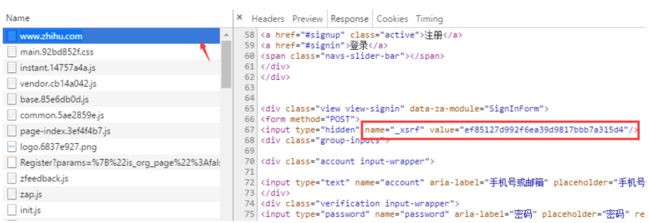
到这里,基本上摸清了浏览器登录时所需要的数据是如何获取的了,那么现在就可以开始撸代码用 Python 模拟浏览器来登
录。登录时所依赖的两个第三方库是 requests 和 BeautifulSoup,先安装
pip install beautifulsoup4==4.5.3
pip install requests==2.13.0
获取 xsrf
前面已经找到了 xsrf 所在的标签,,
利用 BeatifulSoup的find方法可以非常便捷的获取该值,当然,如果你熟悉正则表达式,也可以不用 BeatifulSoup
def get_xsrf():
response = session.get("https://www.zhihu.com", headers=headers)
soup = BeautifulSoup(response.content, "html.parser")
xsrf = soup.find('input', attrs={"name": "_xsrf"}).get("value")
return xsrf
获取验证码
验证码是通过 /captcha.gif 接口返回的,这里我们把验证码图片下载保存到当前目录,由人工识别,当然你可以用第三方支
持库来自动识别,比如 pytesser。
def get_captcha():
"""
把验证码图片保存到当前目录,手动识别验证码
:return:
"""
t = str(int(time.time() * 1000))
captcha_url = 'https://www.zhihu.com/captcha.gif?r=' + t + "&type=login"
r = session.get(captcha_url, headers=headers)
with open('captcha.jpg', 'wb') as f:
f.write(r.content)
captcha = input("验证码:")
return captcha登录
一切参数准备就绪之后,就可以请求登录接口了。
def login(email, password):
login_url = 'https://www.zhihu.com/login/email'
data = {
'email': email,
'password': password,
'_xsrf': get_xsrf(),
"captcha": get_captcha(),
'remember_me': 'true'}
response = session.post(login_url, data=data, headers=headers)
login_code = response.json()
print(login_code['msg'])
session.cookies.save()最后运行返回的结果是“登录成功”。表明登录成功了。细心的你可能已经发现了,我调用了一个 cookies.save() 方法,我是
把cookie信息保存到了本地,下次请求其他需要登录的页面时,就可以把 cookie信息携带上了。
session = requests.session()
session.cookies = cookiejar.LWPCookieJar(filename='cookies')
try:
session.cookies.load(ignore_discard=True)
except:
print("还没有cookie信息")附源码地址 https://github.com/lzjun567/crawler_html2pdf/blob/master/zhihu/auto_login.py
CSDN Python学习班组织的【攒课】活动正在火热进行中,欢迎Python爱好者报名参与,点击==>>[Python爬虫入门与实践](http://www.bagevent.com/event/517724)
除此以外,CSDN Python学习班正在免费招新,期待你的加入,扫描下方二维码,备注“python” 