CRF条件随机场与HMM,MEMM比较
CRF简介
Conditional Random Field:条件随机场,一种机器学习技术(模型)
CRF由John Lafferty最早用于NLP技术领域,其在NLP技术领域中主要用于文本标注,并有多种应用场景,例如:
- 分词(标注字的词位信息,由字构词)
- 词性标注(标注分词的词性,例如:名词,动词,助词)
- 命名实体识别(识别人名,地名,机构名,商品名等具有一定内在规律的实体名词)
本文主要描述如何使用CRF技术来进行中文分词。
CRF VS 词典统计分词
- 基于词典的分词过度依赖词典和规则库,因此对于歧义词和未登录词的识别能力较低;其优点是速度快,效率高
- CRF代表了新一代的机器学习技术分词,其基本思路是对汉字进行标注即由字构词(组词),不仅考虑了文字词语出现的频率信息,同时考虑上下文语境,具备较好的学习能力,因此其对歧义词和未登录词的识别都具有良好的效果;其不足之处是训练周期较长,运营时计算量较大,性能不如词典分词
CRF VS HMM,MEMM
- 首先,CRF,HMM(隐马模型),MEMM(最大熵隐马模型)都常用来做序列标注的建模,像分词、词性标注,以及命名实体标注
- 隐马模型一个最大的缺点就是由于其输出独立性假设,导致其不能考虑上下文的特征,限制了特征的选择
- 最大熵隐马模型则解决了隐马的问题,可以任意选择特征,但由于其在每一节点都要进行归一化,所以只能找到局部的最优值,同时也带来了标记偏见的问题,即凡是训练语料中未出现的情况全都忽略掉
- 条件随机场则很好的解决了这一问题,他并不在每一个节点进行归一化,而是所有特征进行全局归一化,因此可以求得全局的最优值。
CRF分词原理
1. CRF把分词当做字的词位分类问题,通常定义字的词位信息如下:
- 词首,常用B表示
- 词中,常用M表示
- 词尾,常用E表示
- 单子词,常用S表示
2. CRF分词的过程就是对词位标注后,将B和E之间的字,以及S单字构成分词
3. CRF分词实例:
- 原始例句:我爱北京天安门
- CRF标注后:我/S 爱/S 北/B 京/E 天/B 安/M 门/E
- 分词结果:我/爱/北京/天安门
CRF原理:
从概率模型(Probabilistic Models)与图表示(Graphical Representation)两个方面引出CRF。
概率模型
Naïve Bayes(NB)是分类问题中的生成模型(generative model),以联合概率P(x,y)=P(x|y)P(y)P(x,y)=P(x|y)P(y)建模,运用贝叶斯定理求解后验概率P(y|x)P(y|x)。NB假定输入xx的特征向量(x(1),x(2),⋯,x(j),⋯,x(n))(x(1),x(2),⋯,x(j),⋯,x(n))条件独立(conditional independence),即
![]()
HMM是用于对序列数据XX做标注YY的生成模型,用马尔可夫链(Markov chain)对联合概率P(X,Y)P(X,Y)建模:
![]()
然后,通过Viterbi算法求解P(Y|X)P(Y|X)的最大值。LR (Logistic Regression)模型是分类问题中的判别模型(discriminative model),直接用logistic函数建模条件概率P(y|x)P(y|x)。实际上,logistic函数是softmax的特殊形式(证明参看ufldl教程),并且LR等价于最大熵模型(这里给出了一个简要的证明),完全可以写成最大熵的形式:
![]()
其中,Zw(x)Zw(x)为归一化因子,ww为模型的参数,fi(x,y)fi(x,y)为特征函数(feature function)——描述(x,y)(x,y)的某一事实。
CRF便是为了解决标注问题的判别模型,于是就有了下面这幅张图(出自 [3]):

图表示
概率模型可以用图表示变量的相关(依赖)关系,所以概率模型常被称为概率图模型(probabilistic graphical model, PGM)。PGM对应的图有两种表示形式:independency graph, factor graph. independency graph直接描述了变量的条件独立,而factor graph则是通过因子分解( factorization)的方式暗含变量的条件独立。比如,NB与HMM所对应的两种图表示如下(图出自[2]):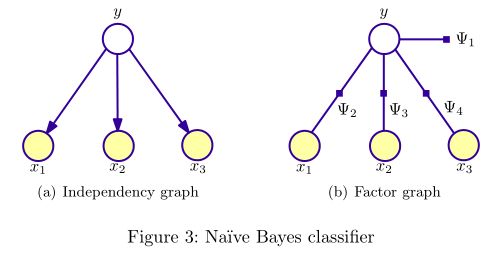
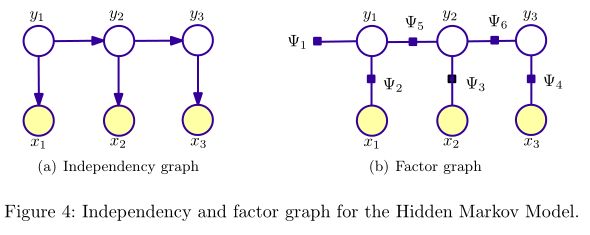
可以看出,NB与HMM所对应的independency graph为有向图,图(V,E)(V,E)所表示的联合概率P(v→)P(v→)计算如下:
![]()
其中,vkvk为图(V,E)(V,E)中一个顶点,其parent节点为vpkvkp。根据上述公式,则上图中NB模型的联合概率:
![]()
有别于NB模型,最大熵则是从全局的角度来建模的,“保留尽可能多的不确定性,在没有更多的信息时,不擅自做假设”;特征函数则可看作是人为赋给模型的信息,表示特征xx与yy的某种相关性。有向图无法表示这种相关性,则采用无向图表示最大熵模型: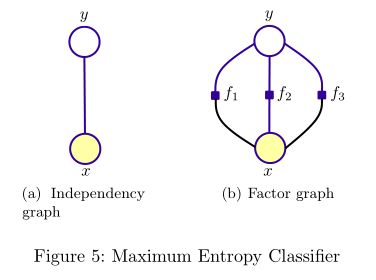
最大熵模型与马尔可夫随机场(Markov Random Field, MRF)所对应factor graph都满足这样的因子分解:
![]()
其中,CC为图的团(即连通子图),ΨCΨC为势函数( potential function)。在最大熵模型中,势函数便为exp(wifi(x,y))exp(wifi(x,y))的形式了。
2. CRF
前面提到过,CRF(更准确地说是Linear-chain CRF)是最大熵模型的sequence扩展、HMM的conditional求解。CRF假设标注序列YY在给定观察序列XX的条件下,YY构成的图为一个MRF,即可表示成图: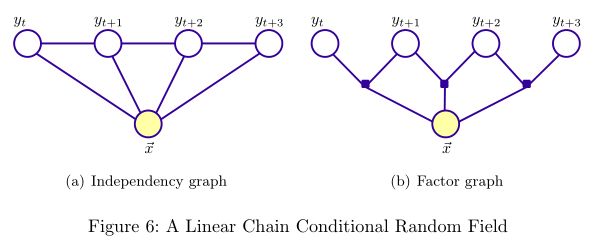
根据式子(4)(4),则可推导出条件概率:

原文:https://www.cnblogs.com/en-heng/p/6214023.html
https://blog.csdn.net/zengxiaosen/article/details/53743474