CRF与HMM
每一个HMM模型都等价于某个CRF
对于词性标注问题,HMM模型也可以解决。HMM的思路是用生成办法,就是说,在已知要标注的句子 s s s的情况下,去判断生成标注序列 l l l的概率,如下所示:
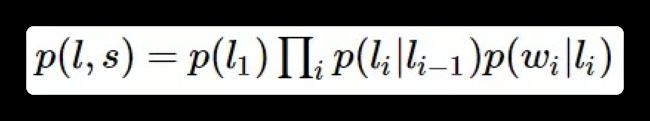
p ( l i ∣ l i − 1 ) p(l_i|l_{i-1}) p(li∣li−1)是转移概率,比如, l i − 1 l_{i-1} li−1是介词, l i l_i li是名词,此时的 p p p表示介词后面的词是名词的概率。 p ( w i ∣ l i ) p(w_i|l_i) p(wi∣li)表示发射概率(emission probability),比如 l i l_i li是名词, w i w_i wi是单词“ball”,此时的 p p p表示在是名词的状态下,是单词“ball”的概率。
而CRF比HMM要强大的多,它可以解决所有HMM能够解决的问题,并且还可以解决许多HMM解决不了的问题。事实上,我们可以对上面的HMM模型取对数,就变成下面这样:
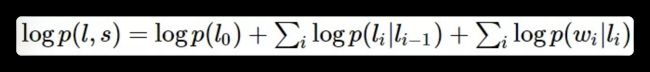
把这个式子与CRF的式子进行比较:
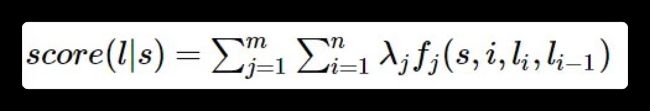
不难发现,如果我们把第一个HMM式子中的 l o g log log形式的概率看做是第二个CRF式子中的特征函数的权重的话,我们会发现,CRF和HMM具有相同的形式。
换句话说,我们可以构造一个CRF,使它与HMM的对数形式相同。
怎么构造呢?
对于HMM中的每一个转移概率 p ( l i = y ∣ l i − 1 = x ) p(l_i=y|l_{i-1}=x) p(li=y∣li−1=x),我们可以定义这样的一个特征函数:
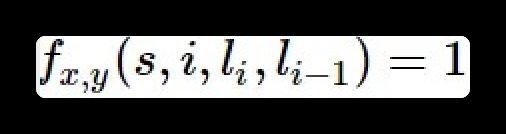
该特征函数仅当 l i = y , l i − 1 = x l_i = y,l_{i-1}=x li=y,li−1=x时才等于1。这个特征函数的权重如下:
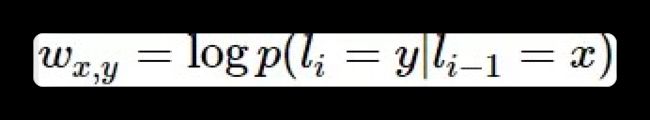
同样的,对于HMM中的每一个发射概率,我们也都可以定义相应的特征函数,并让该特征函数的权重等于HMM中的 l o g log log形式的发射概率。
用这些形式的特征函数和相应的权重计算出来的 s c o r e ( l ∣ s ) score(l|s) score(l∣s)和对数形式的HMM模型几乎是一样的!
用一句话来说明HMM和CRF的关系就是这样:
每一个HMM模型都等价于某个CRF!
CRF要比HMM更加强大,原因主要有两点:
- CRF可以定义数量更多,种类更丰富的特征函数。HMM模型具有天然具有局部性,就是说,在HMM模型中,当前的单词只依赖于当前的标签,当前的标签只依赖于前一个标签。这样的局部性限制了HMM只能定义相应类型的特征函数,我们在上面也看到了。但是CRF却可以着眼于整个句子 s s s定义更具有全局性的特征函数。
- CRF可以使用任意的权重,将对数HMM模型看做CRF时,特征函数的权重由于是log形式的概率,所以都是小于等于0的,而且概率还要满足相应的限制,但在CRF中,每个特征函数的权重可以是任意值,没有这些限制。
CRF与HMM对比
两者的相同点
linear-CRF模型和HMM模型有很多相似之处,尤其是其三个典型问题非常类似,除了模型参数学习的问题求解方法不同以外,概率估计问题和解码问题使用的算法思想基本也是相同的。同时,两者都可以用于序列模型,因此都广泛用于自然语言处理的各个方面。并且都是概率图模型。
两者的不同点
1.最大的不同点是linear-CRF模型是判别模型,而HMM是生成模型,即linear-CRF模型要优化求解的是条件概率P(y|x),则HMM要求解的是联合分布P(x,y)。
2.linear-CRF建立条件概率模型,对于观测序列并没有做马尔科夫假设。而HMM是在对观测序列做了齐次马尔科夫链假设的前提下建立联合分布的模型。
(只有linear-CRF模型和HMM模型才是可以比较讨论的。但是linear-CRF是CRF的一个特例,CRF本身是一个可以适用于很复杂条件概率的模型,因此理论上CRF的使用范围要比HMM广泛的多。)
3.HMM是概率有向图,CRF是概率无向图。
4.CRF比HMM更强大, 更广泛,CRF既具有判别式模型的优点,又考虑到长距离上下文标记间的转移概率,以序列化形式进行全局参数优化和解码的特点,解决了其他判别式模型(如MEMM)难以避免的标记偏见问题。
补充
补充一:生成模型 v s vs vs 判别模型
生成模型就是去学习训练数据的分布,即学习联合概率P(X,Y),主要是对数据分布建模。
判别模型就是直接学习特征与label之间的映射关系。
生成式模型的优点是:
实际上带的信息要比判别模型丰富, 研究单类问题比判别模型灵活性强
能更充分的利用先验知识
模型可以通过增量学习得到 (实验过)
缺点也很明显:
学习过程比较复杂;
在目标分类问题中准确度不高
而判别式模型的优点是:
分类边界更灵活,比生成模型实验效果好
能清晰的分辨出多类或某一类与其他类之间的差异特征
适用于较多类别的识别
缺点是:
不能反映训练数据本身的特性。
能力有限,可以分类, 但无法把整个场景描述出来。
补充二:序列标注训练HMM根本不用EM算法
搞自然语言处理的同学接触的多是Y是可见量的HMM,因为训练数据给出了观测状态,便没有了hidden的变量,没有了hidden变量的hmm就不需要EM来训练。只是使用极大似然估计即可。
补充三:CRF与逻辑回归
实际上,CRF基本上就是逻辑回归的序列化:
与逻辑回归是用于分类的对数线性模型不同,
CRF是标签序列的对数线性模型。