在Spotify我们有超过6000万的活跃用户,他们可以访问超过3000万首歌曲的庞大曲库。用户可以关注成千上万的艺术家和上百个好友,并创建自己的音乐图表。在我们的广告平台上,用户还可以通过体验各种音乐宣传活动(专辑发行,艺人推广)发现新的和现有的内容。这些选项增加了用户的自主权和参与度。目前,用户在平台上已创建了超过15亿播放列表,并且,仅去年一年就播放了超过70亿小时的音乐。
但有时丰富的选择也让我们的用户感到些许困惑。如何从超过10亿个播放列表中找到适合锻炼时听的播放列表?如何发现与自己品味契合的新专辑?通过在平台上提供个性化的用户体验,我们帮助用户发现和体验相关内容。
个性化的用户体验包括在不同的场景中学习用户的喜好和厌恶。一个喜欢金属类音乐的人在给孩子播放睡前音乐时,可能不想收到金属类型专辑的公告。这时,给他们推荐一张儿童音乐专辑可能更为贴切。但是这个经验对另一个不介意在任何情况下接受金属类型专辑推荐的金属类型听众可能毫无意义。这两个用户有相似的听音乐习惯,但可能有不同偏好。根据他们在不同场景下的偏好,提供在Spotify上的个性化体验,可以让他们更加投入。
基于以上对产品的理解,我们着手建立了一个个性化系统,它可以分析实时和历史数据,分别了解用户的场景和行为。随着时间的推移和规模的扩大,我们基于一套灵活的架构建立了自己的个性化技术栈,并且确信我们使用了正确的工具来解决问题。
整体架构
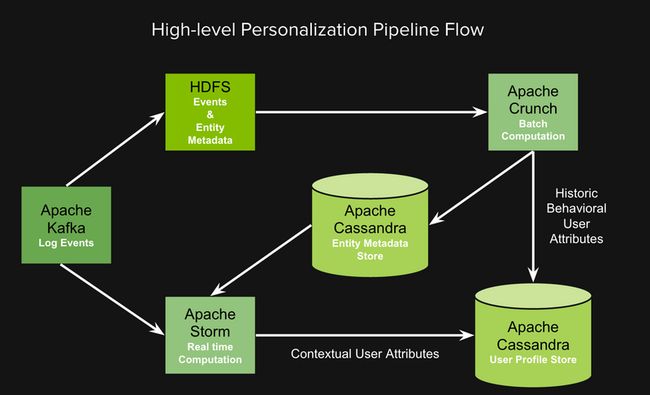
在我们的系统中,使用Kafka收集日志,使用Storm做实时事件处理,使用Crunch在Hadoop上运行批量map-reduce任务,使用Cassandra存储用户画像(user profile)属性和关于播放列表、艺人等实体的元数据。
下图中,日志由Kafka producer发出后,运行在不同的服务上,并且把不同类型的事件(例如歌曲完成、广告展示的投递)发送到Kafka broker。系统中有两组Kafka consumer,分别订阅不同的topic,消费事件:
- Hadoop Consumer将事件写入HDFS。之后HDFS上的原始日志会在Crunch中进行处理,去除重复事件,过滤掉不需要的字段,并将记录转化为Avro格式。
- 运行于Storm topology中的Spouts Consumer对事件流做实时计算。
系统中也有其他的Crunch pipeline接收和生成不同实体的元数据(类型、节奏等)。这些记录存储在HDFS中,并使用Crunch导出到Cassandra,以便在Storm pipeline中进行实时查找。我们将存储实体元数据的Cassandra集群称为实体元数据存储(EMS)。
Storm pipeline处理来自Kafka的原始日志事件,过滤掉不需要的事件,用从EMS获取的元数据装饰实体,按用户分组,并通过某种聚合和派生的算法组合来确定用户级属性。合并后的这些用户属性描述了用户画像,它们存储在Cassandra集群中,我们称之为用户画像存储(UPS)。
为何Cassandra适合?
由于UPS是我们个性化系统的核心,在本文中,我们将详细说明为什么选择Cassandra作为存储。当我们开始为UPS购买不同的存储解决方案时,我们希望有一个解决方案可以:
- 水平扩展
- 支持复制—最好跨站点
- 低延迟。可以为此牺牲一致性,因为我们不执行事务
- 能够支持Crunch的批量数据写入和Storm的流数据写入
- 能为实体元数据的不同用例建模不同的数据模式,因为我们不想为EMS开发另一个解决方案,这会增加我们的运营成本。
我们考虑了在Spotify常用到的各种解决方案,如Memcached、Sparkey和Cassandra。只有Cassandra符合所有这些要求。
水平扩展
Cassandra随着集群中节点数量的增加而扩展的能力得到了高度的宣传,并且有很好的文档支持,因此我们相信它对于我们的场景来说是一个很好的选择。我们的项目从相对较小的数据量开始,但现在已经从几GB增长到100 GB以上(译者注:原文如此,可能是笔误?欢迎有了解内情的读者释疑)。在这一过程中,我们很容易通过增加集群中的节点数量来扩展存储容量;例如,我们最近将集群的规模增加了一倍,并观察到延迟(中位数和99分位)几乎减少了一半。
此外,Cassandra的复制和可用性特性也提供了巨大的帮助。虽然我们不幸遇到了一些由于GC或硬件问题导致节点崩溃的情况,但是我们访问Cassandra集群的服务几乎没有受到影响,因为所有数据都在其他节点上可用,而且客户端驱动程序足够智能,可以透明地进行failover。
跨节点复制
Spotify在全球近60个国家提供服务。我们的后端服务运行在北美的两个数据中心和欧洲的两个数据中心。为了确保在任何一个数据中心发生故障时,我们的个性化系统仍能为用户提供服务,我们必须能够在至少两个数据中心存储数据。
我们目前在个性化集群中使用NetworkReplicationStrategy在欧盟数据中心和北美数据中心之间复制数据。这允许用户访问离自己最近的Spotify数据中心中的数据,并提供如上所述的冗余功能。
虽然我们还没有发生任何导致整个数据中心中的整个集群宕机的事件,但我们已经执行了从一个数据中心到另一个数据中心的用户流量迁移测试,Cassandra完美地处理了从一个站点处理来自两个站点的请求所带来的流量增长。
低延迟 可调一致性
考虑到Spotify的用户基数,实时计算用户听音乐的个性化数据会产生大量数据存储到数据库中。除了希望查询能够快速读取这些数据外,存储数据写入路径的低延迟对我们来说也是很重要的。
由于Cassandra中的写入会存储在append-only的结构中,所以写操作通常非常快。实际上,在我们个性化推荐中使用的Cassandra,写操作通常比读操作快一个数量级。
由于实时计算的个性化数据本质上不是事务性的,并且丢失的数据很容易在几分钟内从用户的听音乐流中替换为新数据,我们可以调整写和读操作的一致性级别,以牺牲一致性,从而降低延迟(在操作成功之前不要等待所有副本响应)。
Bulkload数据写入
在Spotify,我们对Hadoop和HDFS进行了大量投入,几乎所有关于用户的见解都来自于在历史数据上运行作业。
Cassandra提供了从其他数据源(如HDFS)批量导入数据的方式,可以构建整个SSTable,然后将SSTable通过streaming传输到集群中。比起发送数百万条或更多条INSERT语句,这种方式要简单得多,速度更快,效率更高。
针对从HDFS读取数据并bulkload写入SSTable,Spotify开源了一个名为hdfs2cass的工具。
虽然此功能的可用性并不影响我们使用Cassandra进行个性化推荐的决定,但它使我们将HDFS中的数据集成到Cassandra中变得非常简单和易于维护。
Cassandra数据模型
自开始这个项目以来,我们在Cassandra中个性化数据的数据模型经历了一些演变。
最初,我们认为我们应该有两个表——一个用于用户属性(键值对),一个用于“实体”(如艺术家、曲目、播放列表等)的类似属性集。前者只包含带有TTL的短期数据,而后者则是写入不频繁的相对静态的数据。
将键值对存储为单独的CQL行而不是试图为每个“属性”创建一个CQL列(并且每个用户有一个CQL行)的动机是允许生成此数据的服务和批处理作业独立于使用数据的服务。使用这种方法,当数据的生产者需要增加一个新的“属性”时,消费服务不需要做任何改动,因为这个服务只是查询给定用户的所有键值对。
这些表的结构如下:
CREATE TABLE entitymetadata (
entityid text,
featurename text,
featurevalue text,
PRIMARY KEY (entityid, featurekey)
)
CREATE TABLE userprofilelatest (
userid text,
featurename text,
featurevalue text,
PRIMARY KEY (userid, featurename)
)在最初的原型阶段,这种结构工作得很好,但是我们很快遇到了一些问题,这就需要重新考虑关于“实体”的元数据的结构:
- entitymetadata列的结构意味着我们可以很容易地添加新类型的entitymetadata,但是如果我们尝试了一种新类型的数据后发现它没有用,不再需要时,这些featurename没法删除。
- 一些实体元数据类型不能自然地表示为字符串,相反,使用CQL的某个集合类型更容易存储。例如,在某些情况下,将值表示为list更为自然,因为这个值是有顺序的事物列表;或者另一些情况下使用map来存储实体值的排序。
我们放弃了使用一个表来存储以(entityid,featurename)为键的所有值的做法,改为采用了为每个“featurename”创建一个表的方法,这些值使用适当的CQL类型。例如:
CREATE TABLE playlisttag (
entityid text,
featurevalue list,
PRIMARY KEY (entityid)
) 用适当的CQL类型而不是全部用字符串表示,意味着我们不再需要对如何将非文本的数据表示为文本(上面提到的第2点)做出任何笨拙的决定,并且我们可以很容易地删除那些实验之后决定不再用的表。从操作性的角度来看,这也允许我们检查每个“特性”的读写操作的数量。
截至2014年底,我们有近12个此类数据的表,并且发现比起把所有数据块塞进一个表,使用这些表要容易得多。
在Cassandra中有了DateTieredCompactionStrategy之后(我们自豪地说,这是Spotify同事对Cassandra项目的贡献),用户数据表也经历了类似的演变。
我们对userprofilelatency表(译者注:原文如此,猜测可能是userprofilelatest的笔误)的读写延迟不满意,认为DTCS可能非常适合我们的用例,因为所有这些数据都是面向时间戳的,并且具有较短的ttl,因此我们尝试将“userprofilelatest”表的STCS改为DTCS以改善延迟。
在开始进行更改之前,我们使用nodetool记录了SSTablesPerRead的直方图,来作为我们更改前的状态,以便和修改后的效果做比较。当时记录的一个直方图如下:
SSTables per Read
1 sstables: 126733
2 sstables: 111414
3 sstables: 141385
4 sstables: 181974
5 sstables: 222921
6 sstables: 220581
7 sstables: 217314
8 sstables: 216296
10 sstables: 380294注意,直方图相对平坦,这意味着大量的读取请求都需要访问多个sstable,而且往下看会发现这些数字实际上也在增加。

在检查了直方图之后,我们知道延迟很可能是由每次读操作所访问的sstable绝对数量引起的,减少延迟的关键在于减少每次读取必须检查的sstable数量。
最初,启用DTCS后的结果并不乐观,但这并不是因为compaction策略本身的任何问题,而是因为我们把短期TTL数据和没有TTL的用户长期“静态”数据混合在一个表里面。
为了测试如果表中的所有行都有TTL,DTCS是否能够更好地处理TTL行,我们把这个表分成了两个表,一个表用于没有TTL的“静态”行,一个表用于带有TTL的行。
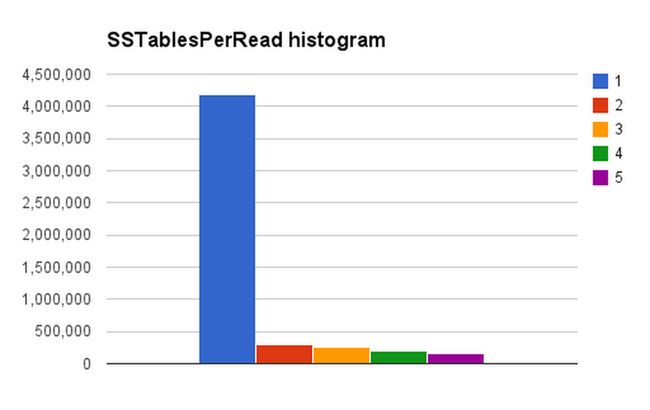
在小心迁移使用这个数据的后端服务(首先将服务更改为同时从新旧表读取数据,然后在数据迁移到新表完成后仅从新表读取)后,我们的实验是成功的:对只有TTL行的表开启DTCS后生成了SSTablesPerRead直方图,其中只需访问1个SSTable的读操作与访问2个SSTable的读操作的比例大约在6:1到12:1之间(取决于主机)。
下面是这次改动之后nodetool cfhistograms输出的一个例子:
SSTables per Read
1 sstables: 4178514
2 sstables: 302549
3 sstables: 254760
4 sstables: 197695
5 sstables: 154961
... 或者如下图:
在解决userprofileLatest表延迟问题的过程中,我们学到了一些关于Cassandra的宝贵经验:
- DTCS非常适合时间序列,特别是当所有行都有TTL时(SizeTieredCompactionStrategy不适合这种类型的数据)
- 但是,如果把有TTL的行和没有TTL的行混在一个表里面,DTCS表现不是很好,因此不要以这种方式混合数据
- 对于带有DTCS/TTL数据的表,我们将gc_grace_period设置为0,并有效地禁用读修复,因为我们不需要它们:TTL比gc grace period要短。
- nodetool cfhistograms和每次读取所访问的SSTables数量可能是了解表延迟背后原因的最佳资源,因此请确保经常测量它,并将其导入图形系统以观察随时间的变化。
通过对我们的数据模型和Cassandra配置进行一些调整,我们成功地构建了一个健壮的存储层,用于向多个后端服务提供个性化数据。在对配置进行微调之后,在Cassandra集群的后续运行中我们几乎没做过任何其他运维操作。我们在仪表板中展示了一组集群和数据集的指标,并配置了警报,当指标开始朝错误方向发展时会触发。这有助于我们被动地跟踪集群的健康状况。除了把集群的大小增加一倍以适应新增的负载之外,我们还没做过太多的集群维护。而即使是集群倍增这部分也相当简单和无缝,值得再发一篇文章来解释所有细节。
总的来说,我们非常满意Cassandra作为满足我们所有个性化推荐需求的解决方案,并相信Cassandra可以随着我们不断增长的用户基数持续扩展,提供个性化体验。
本文翻译自https://labs.spotify.com/2015/01/09/personalization-at-spotify-using-cassandra/
本文作者:_陆豪
本文为云栖社区原创内容,未经允许不得转载。