pytorch实现方面级别情感分类经典模型ATAE-LSTM
首先来看一下模型结构。
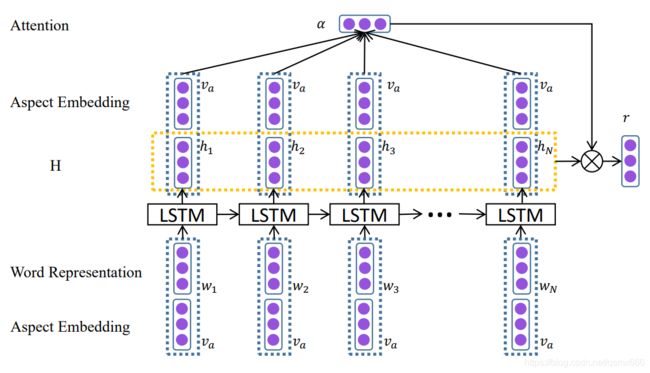
这是LSTM+Attention结构在aspect-level情感分类最早的应用。模型比较简单,输入是sentence和特定aspect,输出是sentence在这个aspect下的情感极性。我们先将Word Respresentation和Aspect Embedding连接后输入到LSTM得到隐藏向量,再将隐藏向量和Aspect Embedding连接后做一次attention,最后把结果输出到全连接层即可。
接下来是具体的实现。
导入包
import torch
import torch.nn as nn
import torch.nn.functional as F
import pandas as pd
import os
from torch.nn import init
from torchtext import data
from torchtext.vocab import Vectors
from torchtext.vocab import GloVe
import time
数据预处理
数据集是SemEval 2014 task4里的,源数据是XML格式,需要先做一些处理。
SemEval 2014数据集预处理:Python xml.etree.cElementTree解析XML文件.
现在的数据结构如下,其中text已经做过分词去停用词之类的处理。

我们用torchtext库处理数据。
torchtext预处理流程
- 定义Field:声明如何处理数据
from nltk.tokenize import word_tokenize
text = data.Field(sequential=True,lower=True,tokenize=word_tokenize)
aspect = data.Field(sequential=False,lower=True)
label = data.Field(sequential=False)
一般的文本分类只需要处理text和label两个字段,这里aspect也是要处理的。
- 定义Dataset:得到数据集,此时数据集里每一个样本是一个经过 Field声明的预处理 预处理后的wordlist
train, val = data.TabularDataset.splits(path='data/',
skip_header=True,
train='train.tsv',
validation='test.tsv',
format='tsv',
fields=[('text', text),
('aspect', aspect),
('polarity', label)])
cache = 'data/.vector_cache'
fields可简单理解为每一列数据和Field对象的绑定关系,参数顺序要和数据集中的字段顺序一致。
我在这一步遇到了一个很奇妙的bug,数据集是CSV格式时建立vocab怎么都不对,后来改成TSV格式就好了。
- 建立vocab:在这一步建立词汇表,词向量
if not os.path.exists(cache):
os.mkdir(cache)
vectors = Vectors(name='data/glove.6B/glove.6B.300d.txt')
text.build_vocab(train, val, vectors=vectors)
aspect.build_vocab(train, val, vectors=vectors)
label.build_vocab(train, val)
text_vocab_size = len(text.vocab)
aspect_vocab_size = len(aspect.vocab)
text_vector=text.vocab.vectors
aspect_vector=aspect.vocab.vectors
建好之后可以打印出来text中出现频率最高的10个词来看一下。
text.vocab.freqs.most_common(10)
print(text.vocab.vectors.shape)

[4083,300]是词汇表的大小,表示一共有4083个词,词向量维度是300。
- 构造迭代器:构造迭代器,用来分批次训练模型
batch_size=128
train_iter, val_iter = data.Iterator.splits(
(train, val),
sort_key=lambda x: len(x.text),
batch_sizes=(batch_size, len(val)), # 训练集设置batch_size,验证集整个集合用于测试
)
打印每个batch的数据结构。
batch = next(iter(train_iter))
print(batch.text.shape)#(seq_len,batch_size)
print(batch.aspect.shape)

模型
class ATAE_LSTM(nn.Module):
def __init__(self, embedding_dim, num_hiddens, num_layers):
super(ATAE_LSTM, self).__init__()
self.text_embeddings = nn.Embedding(text_vocab_size, embedding_dim)
self.aspect_embeddings = nn.Embedding(aspect_vocab_size, embedding_dim)
self.text_embeddings = nn.Embedding.from_pretrained(text_vector,
freeze=False)
self.aspect_embeddings = nn.Embedding.from_pretrained(aspect_vector,
freeze=False)
self.lstm = nn.LSTM(input_size=2 * embedding_dim,
hidden_size=num_hiddens,
num_layers=num_layers,
batch_first=True,
bidirectional=True)
self.wh = nn.Parameter(torch.Tensor(num_hiddens * 2, num_hiddens * 2))
self.wv = nn.Parameter(torch.Tensor(embedding_dim, embedding_dim))
self.omega = nn.Parameter(
torch.Tensor(1, embedding_dim*2))
self.wp = nn.Parameter(torch.Tensor(num_hiddens * 2, num_hiddens * 2))
self.wx = nn.Parameter(torch.Tensor(num_hiddens * 2, num_hiddens * 2))
self.ws = nn.Parameter(torch.Tensor(4, num_hiddens * 2))
nn.init.uniform_(self.wh, -0.1, 0.1)
nn.init.uniform_(self.wv, -0.1, 0.1)
nn.init.uniform_(self.omega, -0.1, 0.1)
nn.init.uniform_(self.wp, -0.1, 0.1)
nn.init.uniform_(self.wx, -0.1, 0.1)
nn.init.uniform_(self.ws, -0.1, 0.1)
self.bs = nn.Parameter(torch.zeros((4, 1)))
def forward(self, text, aspect):
seq_len = len(text.t())
e1 = self.text_embeddings(text)
# e1 形状是(batch_size,seq_len, embedding_dim)
e2 = self.aspect_embeddings(aspect).expand(e1.size())
wv = torch.cat((e1, e2), dim=2)
# e.g.
# wv torch.Size([batch_size,seq_len,2*embedding_dim])
out, (h, c) = self.lstm(wv) # output, (h, c)
# out形状是(batch_size,seq_len, 2 * num_hiddens)
# h形状是(num_layers * num_directions, batch_size, 2*num_hiddens)
H = out.permute(0, 2, 1)
# H形状是(batch_size,2 * num_hiddens,seq_len)
#print(H.shape)
#print(self.wh.shape)
Wh_H = torch.matmul(self.wh, H)
# wh 形状是(2*num_hiddens, 2*num_hiddens)
# wh_H 形状是(batch_size, 2*num_hiddens, seq_len)
#print('Wh_H: ', Wh_H.shape)
Wv_Va_eN = torch.matmul(
self.wv,
self.aspect_embeddings(aspect).permute(0, 2, 1).expand(
-1, embedding_dim, seq_len))
# Wv 形状是(seq_len, seq_len) embedding_dim=2*num_hiddens
# Wv_Va_eN 形状是(batch_size, embedding_dim, seq_len)
#print('Wv_Va_eN: ', Wv_Va_eN.shape)
vh = torch.cat((Wh_H, Wv_Va_eN), dim=1)
# vh 形状是(batch_size, 2*embedding_dim, seq_len)
#print('vh: ', vh.shape)
M = torch.tanh(vh)
# M 形状是(batch_size, 2*embedding_dim, seq_len)
#print('M: ', M.shape)
alpha = F.softmax(torch.matmul(self.omega, M),dim=2)
# omega 形状为(1, 2*embedding_dim))
# alpha 形状为(batch_size, 1, seq_len)
#print('alpha: ', alpha.shape)
r = torch.matmul(H, alpha.permute(0, 2, 1))
# H形状是(batch_size,2 * num_hiddens,seq_len)
# r 形状为(batch_size,2*num_hiddens,1)
#print('r: ', r.shape)
h_star = torch.tanh(
torch.matmul(self.wp, r) +
torch.matmul(self.wx, torch.unsqueeze(H[:, :, -1], 2)))
# h_star形状是(batch_size,2 * num_hiddens,1)
#print('h_star: ', h_star.shape)
y = torch.matmul(self.ws, h_star) + self.bs #不需要手动求softmax
# y 形状(batch_size,4,1)
y = y.reshape([-1, 4])
# y 形状(batch_size,4)
# ws 形状(4, 2*num_hiddens)
#print('y: ', y.shape)
return y
模型的输入是text和aspect,text的维度为[batch_size,seq_len],aspect的维度为[batch_size,1]。经过embedding层后text维度为[batch_size,seq_len, embedding_dim],aspect维度为[batch_size,1, embedding_dim]。将aspect 扩展后和text在embedding_dim维连接,再输入到LSTM。后面的我就不多说了,代码里有注释。
论文里没有batch_size,我搜的一些代码里也没有,就挺奇怪的。所以为了弄清这些矩阵维度还花了不少时间。
还有一点是这里的embedding_dim和2num_hiddens是相等的,有些地方我就用embedding_dim2代替embedding_dim+2*num_hiddens了。
实例化。
embedding_dim, num_hiddens, num_layers = 300, 150, 1
net = ATAE_LSTM(embedding_dim, num_hiddens, num_layers)
print(net)

训练
计算准确率的函数。
def evaluate_accuracy(data_iter, net):
acc_sum, n = 0.0, 0
with torch.no_grad():
for batch_idx, batch in enumerate(data_iter):
X1, X2, y = batch.text, batch.aspect, batch.polarity
X1 = X1.permute(1, 0)
X2 = X2.unsqueeze(1)
if isinstance(net, torch.nn.Module):
net.eval() # 评估模式, 这会关闭dropout
acc_sum += (net(X1,
X2).argmax(dim=1) == y).float().sum().item()
net.train() # 改回训练模式
else:
if ('is_training'
in net.__code__.co_varnames): # 如果有is_training这个参数
# 将is_training设置成False
acc_sum += (net(X1, X2, is_training=False).argmax(
dim=1) == y).float().sum().item()
else:
acc_sum += (net(
X1, X2).argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
return acc_sum / n
这里的batch.text, batch.aspect, batch.polarity都是文件的列名,不是filed。batch.text的形状为[seq_len,batch_size],所以要转换一下维度。batch.aspect的形状为[batch_size],我们用unsequeeze函数将它扩展为[batch_size,1]。
训练过程。
def train(train_iter, test_iter, net, loss, optimizer, num_epochs):
batch_count = 0
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n, start = 0.0, 0.0, 0, time.time()
for batch_idx, batch in enumerate(train_iter):
X1, X2, y = batch.text, batch.aspect, batch.polarity
X1 = X1.permute(1, 0)
X2 = X2.unsqueeze(1)
y_hat = net(X1,X2)
l = loss(y_hat, y)
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l_sum += l.item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().item()
n += y.shape[0]
batch_count += 1
test_acc = evaluate_accuracy(test_iter, net)
print(
'epoch %d, loss %.4f, train acc %.3f, test acc %.3f, time %.1f sec'
% (epoch + 1, train_l_sum / batch_count, train_acc_sum / n,
test_acc, time.time() - start))
lr, num_epochs = 0.01, 20
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
train(train_iter, val_iter, net, loss, optimizer, num_epochs)
训练结果。

训练了20个epoch,最后测试集准确率在0.713,比论文里的准确率低。可能是因为论文里用的是840d的词向量,我用的是300d的。还有就是超参数可以再调一下。