mmseg中文分词算法的python实现及其优化
mmseg中文分词算法的python实现及其优化
任务定义
实现一个中文分词系统并对其性能做测试。
输入输出
该分词的训练语料取自人民日报1998年公开的语料库。为了保证测试的严谨性,选择另一份语料库做测试文档。该文档为SIGHAN(国际计算语言学会(ACL)中文语言处理小组)举办的国际中文语言处理竞赛中提供的pku_test_gold语料。
方法描述
mmseg算法理解
mmseg本质上就是前向最大匹配+消除歧义规则+贪心,最简单的前向最大匹配就是,将每次从起点位置能匹配到的最长词语作为分词结果,连续进行下去。前向最大匹配符合人们的习惯,但是在某些语句中会产生歧义。例如北京大学生前来应聘,由于北京大学在词库中出现,所以前向最大匹配会分成北京大学/生/前来/应聘,显然这不是正确的分词结果。
那么mmseg会怎么做呢,mmseg首先是从起始位置,找到所有可能的三个词语的组合,每个组合作为一个候选分词结果,然后通过四种消除歧义的规则选出最优分词结果。
候选词组的类定义如下
#候选词的类
class candidate(object):
length=0#总长度
avelen=0#平均长度
variance=0.0#方差
lsum=0.0#单子频的自然对数集合
num=0.0#词语数量
words=[]消除歧义的规则如下:
- 最大匹配,也就是找到候选词组中,三个词语长度加起来最长的一个。
- 最大平均词语长度。理论上,总长度相同,若都是三个词语,平均长度当然也相同。这个问题后文再说。
- 词语长度最小变化率,这个求一下标准差或者方差即可,也很简单。
- 单字词词频的自然对数的和,这个是什么意思呢,就是把分词结果中所有的单字组成的词语找出来,计算每个单字词频的自然对数,再求和。之所以去自然对数再求和的原因,主要是为了降低直接把词频相加还相同的可能性。
以上四条规则,优先级由高到低,也就是说先按第一个关键字排序,再按第二个,以此类推。
算法本身很简单,实现也不复杂,不过效果比简单的前向最大匹配好很多。
一些简单的优化和细节实现
每次都是选择三个词语,不会有问题么?
答案是会的,举个栗子,我们去马尔代夫结婚吧,首先起点从“我”开始,分出三个词语是我们/去/马尔代夫,那么起点变成了结,如果强行分出三个词语,那么结果就是我们/去/马尔代夫/结/婚/吧。这个情况下,显然我们/去/马尔代夫/结婚/吧才是更好的选择。
所以不妨在遍历可能得词语组合的情况时,加入单个词语和两个词语的情况。可以提高分词的准确度
利用字典树提高搜索效率
这个是一个非常简单但是十分有效的优化。mmseg十分依赖于字典,需要做大量的查找。不过中文的字典树问题在于可能的字符太多,所以实际上字典树也是非常庞大的。
贴一个python的字典树实现代码,节点保存词语频率。
#字典树部分 class trie: root={} END='/' def add(self,word,cnt): node=self.root for c in word: node=node.setdefault(c,{}) node[self.END]=cnt def find(self,word): node=self.root for c in word: if(c not in node): return 0 node=node[c] if(self.END in node): return int(node[self.END]) return 0词典中找不到怎么办
如果语料库合格,词典中找不到,那么可能性大多是单字词语,或者专有名词。后者只能是扩充字典,所以这种情况默认分成单字词语。
多关键字排序的python实现
利用operator模块是最简单的选择
candidates = sorted(candidates, key=attrgetter('lsum'),reverse=True) candidates = sorted(candidates, key=attrgetter('variance')) candidates=sorted(candidates,key=attrgetter('length','avelen'),reverse=True)存在的缺陷
事实上,如果复杂度允许,分的词语越多,正确性应该越高。但也就意味着复杂度多乘一个O(n)。mmseg默认是三个词语为一个词组,当遇到结婚的和尚未结婚的这条语句则会出现问题,mmseg会选择结婚/的/和尚/未/结婚的。这个问题我目前还没找到合适的解决方案。
结果分析
消除歧义效率
mmseg作为基于前向最大匹配算法的优化算法,最大的提升在于对歧义句子的消除。下图展示了一些比较典型的案例。

准确率,召回率以及F-score
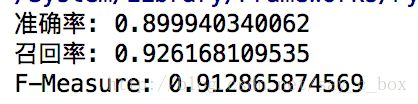
用于测试的代码部分如下# -*- coding: UTF-8 -*- # 打开一个文件 #coding:utf-8 import sys reload(sys) sys.setdefaultencoding('utf8') import codecs import re fin1=codecs.open("处理后测试数据.txt","r","utf-8")#这个是标准分词结果 fin2=codecs.open("分词结果.txt","r","utf-8")#这个是我的分词结果 xnum=0#应该切分出的词语总数 ynum=0#切分出的总词语个数 rnum=0#正确词语个数 while(True): x=fin1.readline() y=fin2.readline() if(x==""): break w1=x.split(" ") w2=y.split(" ") n=len(w1) m=len(w2) xnum+=n ynum+=m i=0 j=0 p=0 q=0 while(iand j 测试结果如下:

源码运行环境
Python 2.7
python实现
#语料库处理之后的形式为 词语 词频
#例如 生活 2 ,这样方便插入字典树。
# -*- coding: UTF-8 -*-
# 打开一个文件
#coding:utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf8')
import codecs
import re
import math
from operator import itemgetter, attrgetter
#字典树部分
class trie:
root={}
END='/'
def add(self,word,cnt):
node=self.root
for c in word:
node=node.setdefault(c,{})
node[self.END]=cnt
def find(self,word):
node=self.root
for c in word:
if(c not in node):
return 0
node=node[c]
if(self.END in node):
return int(node[self.END])
return 0
#构建字典树部分
Trie=trie()
fin=codecs.open("处理后语料.txt","r","utf-8")
num=fin.readline()
num=int(num)
for i in range(0,num):
s=fin.readline()
a=s.split()
k=a[0].encode('utf-8')
v=int(a[1].encode('utf-8'))
Trie.add(a[0],a[1])
fin.close()
def is_chinese(uchar):
"""判断一个unicode是否是汉字"""
if uchar >= u'\u4e00' and uchar <= u'\u9fa5':
return True
else:
return False
#mmseg算法部分
while(True):
tmp=raw_input("请输入需要分词的句子:")
if(tmp=="-1"):
break
tmp=unicode(tmp)
sentence=""
for c in tmp:
if(is_chinese(c)):
sentence=sentence+c
#候选词的类
class candidate(object):
length=0#总长度
avelen=0#平均长度
variance=0.0#方差
lsum=0.0#单子频的自然对数集合
num=0.0#词语数量
words=[]
candidates=[]
Allwords=[]
n = len(sentence)
i=0;
while(ifor j in range(i+1,n+1):
#一个词
a=unicode(sentence[i:j])
x=Trie.find(a)
if(x!=0):
can = candidate()
can.words=[]
can.num=1
can.words.append(a)
can.length=j-i
can.avelen=can.length
can.variance=0.0
if(len(a)==1):
can.lsum=math.log(x)
candidates.append(can)
for k in range(j+1,n+1):
#两个词
a = unicode(sentence[i:j])
b = unicode(sentence[j:k])
x = Trie.find(a)
y = Trie.find(b)
if ((x != 0 and y != 0 )):
can = candidate()
can.words = []
can.words.append(a)
can.words.append(b)
can.num=2
can.length = (k - i)
can.avelen = (len(a) + len(b)) / 2.0
can.variance = (len(a) - can.avelen) ** 2 + (len(b) - can.avelen) ** 2
can.lsum = 0
if (len(a) == 1):
can.lsum += math.log(x)
if (len(b) == 1):
can.lsum += math.log(y)
candidates.append(can)
for l in range(k+1,n+1):
#三个词
a=unicode(sentence[i:j])
b=unicode(sentence[j:k])
c=unicode(sentence[k:l])
x=Trie.find(a)
y=Trie.find(b)
z=Trie.find(c)
if((x!=0 and y!=0 and z!=0)):
can=candidate()
can.words=[]
can.words.append(a)
can.words.append(b)
can.words.append(c)
can.num=3
can.length=(l-i)
can.avelen=(len(a)+len(b)+len(c))/3.0
can.variance=(len(a)-can.avelen)**2+(len(b)-can.avelen)**2+(len(c)-can.avelen)**2
can.lsum=0
if(len(a)==1):
can.lsum+=math.log(x)
if(len(b)==1):
can.lsum+=math.log(y)
if(len(c)==1):
can.lsum+=math.log(z)
candidates.append(can)
if(len(candidates)!=0):
candidates = sorted(candidates, key=attrgetter('lsum'),reverse=True)
candidates = sorted(candidates, key=attrgetter('variance'))
candidates=sorted(candidates,key=attrgetter('length','avelen'),reverse=True)
for x in range(0,candidates[0].num):
Allwords.append(candidates[0].words[x])
i=i+candidates[0].length
#如果找不到三个分词的词语则尝试使用simple方法
else:
update=False
for j in range(n+1,i+1):
w=unicode(sentence[i:j])
if(Trie.find(w)!=0):
update=True
i=j
Allwords.append(w)
break
if(update==False):
w = unicode(sentence[i:i+1])
Allwords.append(w)
i=i+1
ans=[]
for c in Allwords:
print (c.encode('utf-8')),
print ""