自然语言处理(NLP):08 PyTorch深度学习之LSTM微博评论情感分析
作者多年机器学习/数据挖掘工作经验。大厂打过杂,做过几个NLP、推荐系统、深度学习图像分类和目标检测
文章目录
- 研究内容
- 涉及主要功能点
- 01情感分析应用场景
- 02数据分析可视化
- 03 深度学习框架选型
- 04 RNN和LSTM理论知识
- 05 图像描述项目在LSTM中应用
- 06 数字识别项目在LSTM中应用
- 07 基于微博评论情感分析实战
- 微博评论数据探查
- 加载数据
- 文章字长度统计
- 微博评论数据可视化统计
- 微博评论数据词云统计
- 数据预处理和数据封装
- 介绍几种RNN网络
- 标准RNN 模型
- LSTM 模型
- 正则化
- RNN 模型实现细节
- 数据模型定义
研究内容
- 微博评论数据探查,重点掌握pandas数据分析使用
- 数据可视化,重点掌握seaborn,pyecharts 可视化工具的实用
- 卷机神经网络RNN/LSTM 模型原理
- 掌握PyTorch 中关于自然语言处理torchtext 库使用
- torchtext 中重点工具BucketIterator使用,torch.nn模型使用
- 情感分析RNN/LSTM模型构建和训练
- 评论情感分析模型预测
涉及主要功能点
01情感分析应用场景
- 评论分析与智能决策
- 电商评论
- 舆情监控
- 话题监督
- 微博评论情感分析
02数据分析可视化
- matplotlib 可视化
- seaborn可视化
- pyecharts可视化操作
03 深度学习框架选型
- PyTorch作为课程深度学习框架
- PyTorch基本语法使用
- 文本处理采用torchtext 预处理
- 采用RNN和LSTM模型训练
04 RNN和LSTM理论知识
- RNN工作原理
- RNN梯度消失和爆炸问题
- LSTM引入
- LSTM原理以及变种
- 不同RNN架构
05 图像描述项目在LSTM中应用
- LSTM应用以及架构介绍
- CNNEncoder&RNNDecoder架构推断预测
- RNN和LSTM在PyTorch中API
06 数字识别项目在LSTM中应用
- 数据加载
- LSTM模型训练和在线预测双向LSTM项目实战
07 基于微博评论情感分析实战
- 文本数据探测和分析
- 数据长度以及词云可视化
- 数据加载工具搭建torchtext中Field字段使用
- 数据词典加载和调试
- 数据字典PAD和UNK应用场景
- 数据批量加载
- pad和pack使用操作
- 整体工程代码搭建
- 模型参数配置
- 外部词向量引入
- 模型Encoder和FC方法定义
- 训练方法和验证方法定义
- 训练代码调试
- 最优情感分析模型生成
- 模型训练
- 效果评估可视化
- 情感分析在线服务
微博评论数据探查
加载数据
import pandas as pd
import jieba
train = pd.read_csv('data/train.csv')
val = pd.read_csv('data/val.csv')
train.head()
| data | label | |
|---|---|---|
| 0 | 靠怎么就快五月了,从小陪我一起看漫威电影的朋友和我绝交了竟不知道自己怎么去看还记得看妇联1之... | 0 |
| 1 | 就,很难受。 \r\n | 0 |
| 2 | 有朋友真好喔 朋友有我也真好四月快结束了 一切就都重新开始吧 \r\n | 1 |
| 3 | 今天去UT买周刊少年jump50周年合作款、帮朋友抢了4件之后又返回来、才发现小排球!!!!... | 0 |
| 4 | 大家说送别饺子来时面,所以我要从今天开始就吃送别饭了,大概吃三天 \r\n | 1 |
val.head()
| data | label | |
|---|---|---|
| 0 | 青山不改,绿水长流。我们江湖再见。{%#沈阳工学院#%} @沈阳工学院传媒中心 [心][心]... | 1 |
| 1 | 柳词叔叔直播间有人问收徒吗柳词:500一位,包教包会(开玩笑)游戏密聊:柳词叔叔听说您收徒,... | 1 |
| 2 | 最近过得太有烟火气了 我竟然看着菜谱学会做饭了(我室友说好吃 我信了) 现在只想下班回家去超... | 1 |
| 3 | 总有人让檀健次站坑里,本来看的好好的,这一幕让我不厚道的笑了[允悲][允悲][允悲]{%#檀... | 1 |
| 4 | 我们绕了这么一圈再遇到 我比谁都更明白你的重要 \r\n | 1 |
为方便数据分析,我们合并train/val 两种数据
data_df = pd.concat([train,val])
data_df.head()
| data | label | |
|---|---|---|
| 0 | 靠怎么就快五月了,从小陪我一起看漫威电影的朋友和我绝交了竟不知道自己怎么去看还记得看妇联1之... | 0 |
| 1 | 就,很难受。 \r\n | 0 |
| 2 | 有朋友真好喔 朋友有我也真好四月快结束了 一切就都重新开始吧 \r\n | 1 |
| 3 | 今天去UT买周刊少年jump50周年合作款、帮朋友抢了4件之后又返回来、才发现小排球!!!!... | 0 |
| 4 | 大家说送别饺子来时面,所以我要从今天开始就吃送别饭了,大概吃三天 \r\n | 1 |
文章字长度统计
data_df['tokens'] = data_df['data'].apply(lambda x:jieba.lcut(x))
data_df['token_count'] = data_df['data'].apply(lambda x:len(jieba.lcut(x)))
data_df['text_lengths'] = data_df['data'].apply(lambda x:len(x))
| data | label | tokens | token_count | text_lengths | |
|---|---|---|---|---|---|
| 0 | 靠怎么就快五月了,从小陪我一起看漫威电影的朋友和我绝交了竟不知道自己怎么去看还记得看妇联1之... | 0 | [靠, 怎么, 就, 快, 五月, 了, ,, 从小, 陪, 我, 一起, 看漫威, 电影,... | 56 | 79 |
| 1 | 就,很难受。 \r\n | 0 | [就, ,, 很, 难受, 。, , , \r\n] | 8 | 10 |
| 2 | 有朋友真好喔 朋友有我也真好四月快结束了 一切就都重新开始吧 \r\n | 1 | [有, 朋友, 真好, 喔, , 朋友, 有, 我, 也, 真, 好, 四月, 快, 结束... | 25 | 34 |
| 3 | 今天去UT买周刊少年jump50周年合作款、帮朋友抢了4件之后又返回来、才发现小排球!!!!... | 0 | [今天, 去, UT, 买, 周刊, 少年, jump50, 周年, 合作, 款, 、, 帮... | 58 | 85 |
| 4 | 大家说送别饺子来时面,所以我要从今天开始就吃送别饭了,大概吃三天 \r\n | 1 | [大家, 说, 送别, 饺子, 来时, 面, ,, 所以, 我要, 从, 今天, 开始, 就... | 25 | 37 |
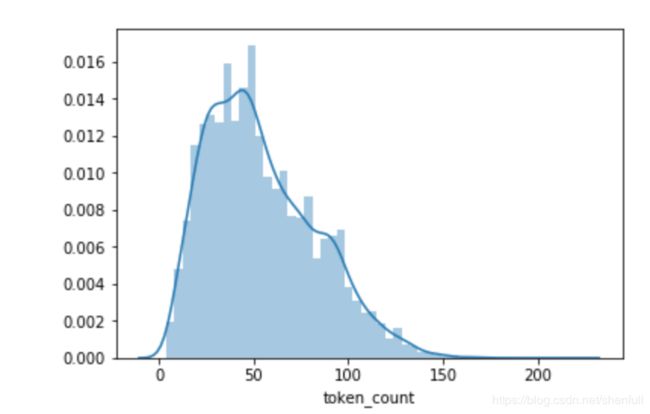
微博评论数据可视化统计
主要通过直方图 来统计 token_count/text_lengths 的整体的数据分布
import seaborn as sns
token_count = data_df['token_count']
text_lengths = data_df['text_lengths']
sns.distplot(token_count)
微博评论数据词云统计
主要通过直方图 来统计 token_count/text_lengths 的整体的数据分布
word_freq 格式 : [(‘他’, 853), (‘好’, 832), (‘真的’, 809),。。。。。]
import pyecharts.options as opts
from pyecharts.charts import WordCloud
# 构建词云数据格式(word,count)
c = WordCloud()
c.add(series_name='',data_pair=word_freq[30:5000])
c.render_notebook()

数据预处理和数据封装
# 导入torch库
import torch
# 导入torchtext库,主要自然语言处理预处理
from torchtext.data import Field, TabularDataset
# 加载外部词向量
from torchtext.vocab import Vectors
# 引入自定义配置
from configs import BasicConfigs
# 引入工具类
from utils import chi_tokenizer
config = BasicConfigs()
# 定义字段 (TEXT/LABEL)
## include_lengths=True 为了方便后续使用torch pack_padded_sequence
## chi_tokenizer 分词器,主要对我们的每个句子进行切分
TEXT = Field(tokenize=chi_tokenizer, include_lengths=True)
LABEL = Field(eos_token=None, pad_token=None, unk_token=None)
## torchtext中于文件配对关系
fields = [('data', TEXT), ('label', LABEL)]
# 加载数据
## 注意skip_header = True
train_data, val_data = TabularDataset.splits(path='data',
train='train.csv',
validation='val.csv',
format='csv',
fields=fields,
skip_header=True)
## 数据记录数统计
print('train total_count = ', len(train_data.examples))
print('val total_count = ', len(val_data.examples))
from torchtext.data import BucketIterator
train_iter = BucketIterator(train_data,
batch_size=config.batch_size,
sort_key=lambda x:len(x.data),
sort_within_batch=True,
shuffle=True,
device=config.device)
val_iter = BucketIterator(val_data,
batch_size=config.batch_size,
sort_key=lambda x:len(x.data),
sort_within_batch=True,
shuffle=False,
device=config.device)
- 最后一步数据的准备是创建iterators。每个itartion都会返回一个batch的examples。
- 我们会使用
BucketIterator。BucketIterator会把长度差不多的句子放到同一个batch中,确保每个batch中不出现太多的padding。 - 严格来说,我们这份notebook中的模型代码都有一个问题,也就是我们把
- 如果我们有GPU,还可以指定每个iteration返回的tensor都在GPU上。
介绍几种RNN网络
标准RNN 模型
- 下面我们尝试把模型换成一个recurrent neural network (RNN)。RNN经常会被用来encode一个sequence
h t = RNN ( x t , h t − 1 ) h_t = \text{RNN}(x_t, h_{t-1}) ht=RNN(xt,ht−1) - 我们使用最后一个hidden state h T h_T hT来表示整个句子。
- 然后我们把 h T h_T hT通过一个线性变换 f f f,然后用来预测句子的情感。
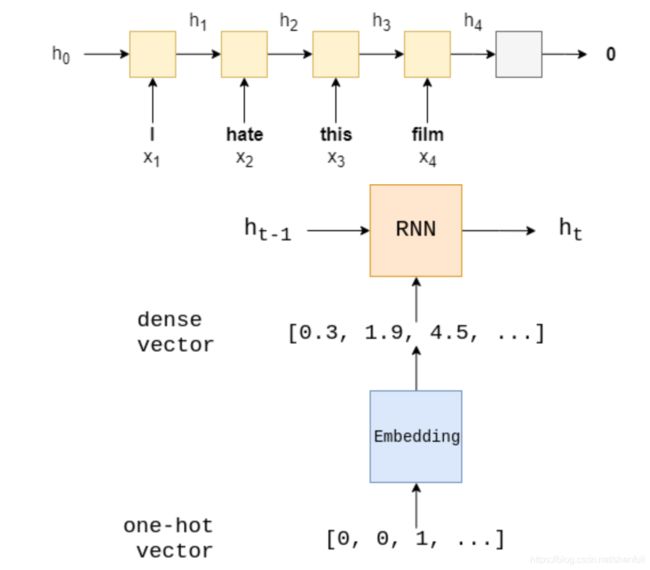
使用train和evaluate 创建模型
自定义RNN 模型,在pytorch中需要继承nn.Model,同时在__init__ 方法中定义layer
这里,我们定义三层 an embedding layer,our RNN,and a linear layer
- embedding layer:对每个word 进行one-hot 编码处理,spare vector-> dense vector . [sentence length, batch size, embedding dim]
- RNN:获取dense vector and hidden state(prev layers)
- a linear layer: 最后的hidden state ,通过一个FC,获取最终维度的数据
LSTM 模型
We’ll be using a different RNN architecture called a Long Short-Term Memory (LSTM). Why is an LSTM better than a standard RNN? Standard RNNs suffer from the vanishing gradient problem. LSTMs overcome this by having an extra recurrent state called a cell, c c c - which can be thought of as the “memory” of the LSTM - and the use use multiple gates which control the flow of information into and out of the memory. For more information, go here. We can simply think of the LSTM as a function of x t x_t xt, h t h_t ht and c t c_t ct, instead of just x t x_t xt and h t h_t ht.
( h t , c t ) = LSTM ( x t , h t , c t ) (h_t, c_t) = \text{LSTM}(x_t, h_t, c_t) (ht,ct)=LSTM(xt,ht,ct)
Thus, the model using an LSTM looks something like (with the embedding layers omitted):
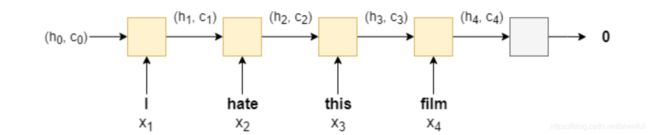
The initial cell state, c 0 c_0 c0, like the initial hidden state is initialized to a tensor of all zeros. The sentiment prediction is still, however, only made using the final hidden state, not the final cell state, i.e. y ^ = f ( h T ) \hat{y}=f(h_T) y^=f(hT).
LSTM 和 RNN 区别
LSTM(Long Short-Item Memory) : 相比普通的RNN 效果为好。普通RNN 会出现梯度消失问题,而LSTM 主要为了解决梯度消息和梯度爆炸问题。LSTM 能够在更长的序列中有更好的表现。
RNN 只有一个传递状态 h t h_t ht
LSTM有两个传递状态 c t c_t ct(cell state) 和 h^t (hidden state),其中: c t c_t ct 改变很慢, h t h_t ht 在不通节点上改变很大
LSTM内部主要有三个阶段:
- 忘记阶段。这个阶段主要是对上一个节点传进来的输入进行选择性忘记。简单来说就是会 “忘记不重要的,记住重要的”。
- 选择记忆阶段。这个阶段将这个阶段的输入有选择性地进行“记忆”。
- 输出阶段。
通过门控状态来控制传输状态,记住需要长时间记忆的,忘记不重要的信息;而不像普通的RNN那样只能够“呆萌”地仅有一种记忆叠加方式。对很多需要“长期记忆”的任务来说,尤其好用。
LSTM 相比RNN 也存在问题:
因为引入了很多内容,导致参数变多,也使得训练难度加大了很多。因此很多时候我们往往会使用效果和LSTM相当但参数更少的GRU来构建大训练量的模型
正则化
我提升model 效果,增加大量的参数。
带来问题: 过拟合(train data 上的error 低,但在validation/test error 上高)。
解决方案: 使用regularization,例如: dropout-在forward pass 的时候,使得某些神经元权重0,
每个forward pass 生成一个weak model。对这些weaker model 进行ensemble,理论上可以解决过拟合问题
RNN 模型实现细节
-
标记: 填充标记于情感无关,明确告诉模型不需要embedding,只是占据一个位置,在pytorch中可以通过nn.Embedding图层实现这个操作
-
使用LSTM 替换普通的RNN ,在pytorch中可以使用nn.LSTM (替换nn.RNN) ,我们的LSTM 最终输出hidden state and cell state ,而nn.RNN 输出hidden state
-
我们LSTM 最后hidden state 有两个组件: forward and backward ,聚合他们后输入给nn.Linear 层,维度大小是hidden dim size 的两倍
-
实现Bi-directional RNN 可以在RNN/LSTM 中num_layers and bidirectional 参数设置
-
nn.Dropout 实现了dropout层,这层可以在每个神经元后可以dropping。 在LSTM 中,有个dropout参数可以设置。
-
使用 ,我们设置text_lengths,to forward
-
文本的embedding
nn.utils.rnn.packed_padded_sequence -> 使用RNN embedding -
两个hidden state 获取
hidden[-2,:,:] and hidden[-1,:,:]
数据模型定义
# 导入定义bilstm库
import torch
from torch import nn
class BiLSTM(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_size, num_layers, pad_idx,
unk_idx, pre_trained_embedding=None):
super(BiLSTM, self).__init__()
# lookup table that stores embeddings of fixed dictionary and size
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=pad_idx)
# 加载 预处理embeddding
if pre_trained_embedding is not None:
self.embedding.weight.data.copy_(pre_trained_embedding)
# 对于pre_trained vocab 没有对应的vector
self.embedding.weight.data[unk_idx] = torch.zeros(embedding_dim)
self.embedding.weight.data[pad_idx] = torch.zeros(embedding_dim)
# 定义encoder
self.encoder = nn.LSTM(input_size=embedding_dim,
hidden_size=hidden_size,
num_layers=num_layers,
bidirectional=True)
# 定义decoder
self.decoder = nn.Linear(2 * hidden_size, 2)
# 定义dropout
## 减少过拟合,增加我们模型的泛化能力
## Dropout 在深度网络训练中,以一定随机概率临时丢失一部分神经元的节点
self.dropout = nn.Dropout(0.5)
def forward(self, inputs, text_lengths):
"""
:param inputs: 每个batch text 内容
:param text_lengths: words 的长度,词汇长度
:return:
"""
# 提取词特征(词数,批量大小)
......
# pad sequence 设置
......
# encoder
......
# decoder
......
return outs