TensorFlow学习日记4
1. RNN结构
解析:
(1)one to one表示单输入单输出网络。这里的但输入并非表示网络的输入向量长度为1,而是指数据的长度是确定
的。比如输入数据可以是一个固定类型的数,可以是一个固定长度的向量,或是一个固定大小的图片。同理,模型输
出规模也是确定的。传统神经网络和CNN都可以理解为是这种形式的结构。
(2)one to many表示定长输入变长输出的网络结构。以单词释义问题为例,输入的单个的英文单词he,输出将是一
段单词序列"that male one who is neither speaker nor hearer"。
(3)many to one表示输入为变长序列、输出为固定长度的模型。文本情感分析问题就是这一类型中典型的场景,网
络模型要根据一段文本,给出是否为积极情绪或消极情绪的概率判断。
(4)many to many第一种结构属于Encoder-Decoder框架,它的特点是输入序列数据经过编码器网络得到内部表示
后,再基于这个表示通过解码器网络生成新的序列数据。输入和输出都是变长数据,而且两者的长度可以不同。这一
类型的典型场景是机器翻译。比如使用RNN进行中英文翻译,网络输入为一段中文文本,输出为对应英文翻译结果。
(5)many to many第二种结构属于输入和输出的元素完全一一对应,虽然输入数据和输出数据的规模都是不定的,
但对于每一个输入,都有对应输出,即输入和输出数据长度是一致的。文本序列标注问题就是这样一类问题,可以使
用RNN对给定文本中的每一个单词进行词性标注。
2. tf.stack和tf.unstack
解析:
(1)tf.stack
stack(values, axis=0, name='stack')。假如'x'为[1, 4],'y'为[2, 5],'z'为[3, 6],那么stack([x, y, z]) => [[1, 4], [2, 5], [3,
6]],stack([x, y, z], axis=1) => [[1, 2, 3], [4, 5, 6]]。tf.stack([x, y, z]) = np.asarray([x, y, z])。
(2)tf.unstack
unstack(value, num=None, axis=0, name='unstack')。tf.unstack(x, n) = list(x)。
举个例子,如下所示:
import tensorflow as tf
a = tf.constant([1,2,3])
b = tf.constant([4,5,6])
c = tf.stack([a,b],axis=1)
d = tf.unstack(c,axis=0)
e = tf.unstack(c,axis=1)
print(c.get_shape())
with tf.Session() as sess:
print(sess.run(c))
print(sess.run(d))
print(sess.run(e))结果输出,如下所示:
[[1 4][2 5][3 6]]
[array([1, 4], dtype=int32), array([2, 5], dtype=int32), array([3, 6], dtype=int32)]
[array([1, 2, 3], dtype=int32), array([4, 5, 6], dtype=int32)]
3. tf.split
解析:split(value, num_or_size_splits, axis=0, num=None, name='split')。假设value的shape为[5, 30],如下所示:
(1)如果split0, split1, split2 = tf.split(value, [4, 15, 11], 1),那么tf.shape(split0) ==> [5, 4];tf.shape(split1) ==> [5,
15];tf.shape(split2) ==> [5, 11]。
(2)如果split0, split1, split2 = tf.split(value, num_or_size_splits=3, axis=1),那么tf.shape(split0) ==> [5, 10]。
举个例子,如下所示:
import tensorflow as tf
A = [[1, 2, 3], [4, 5, 6]]
x0 = tf.split(A, num_or_size_splits=3, axis=1)
x1 = tf.unstack(A, num=3, axis=1)
x2 = tf.split(A, num_or_size_splits=2, axis=0)
x3 = tf.unstack(A, num=2, axis=0)
with tf.Session() as sess:
print(sess.run(x0))
print(sess.run(x1))
print(sess.run(x2))
print(sess.run(x3))[array([[1],[4]]), array([[2],[5]]), array([[3],[6]])]
[array([1, 4]), array([2, 5]), array([3, 6])]
[array([[1, 2, 3]]), array([[4, 5, 6]])]
[array([1, 2, 3]), array([4, 5, 6])]
说明:axis=0表示按行操作,axis=1表示按列操作。
4. tf.nn.rnn_cell.BasicLSTMCell和tf.contrib.rnn.BasicLSTMCell
5. state_is_tuple
解析:如果state_is_tuple=True,那么state是元组形式,state=(c,h)。如果state_is_tuple=False,那么state是一个由
c和h拼接起来的张量,state=tf.concat(1,[c,h])。
6. tf.subtract
解析:subtract(x, y, name=None),如下所示:
(1)x: A Tensor. Must be one of the following types: half, float32, float64, int32, int64, complex64, complex128.
(2)y: A Tensor. Must have the same type as x.
(3)name: A name for the operation (optional).
7. tf.multiply和tf.matmul区别
解析:
(1)tf.multiply是点乘,即Returns x * y element-wise.
(2)tf.matmul是矩阵乘法,即Multiplies matrix a by matrix b, producing a * b.
8. tf.contrib.layers.xavier_initializer
解析:xavier_initializer(uniform=True, seed=None, dtype=tf.float32):An initializer for a weight matrix.
(1)uniform: Whether to use uniform or normal distributed random initialization.
(2)seed: A Python integer. Used to create random seeds. See tf.set_random_seed for behavior.
(3)dtype: The data type. Only floating point types are supported.
9. tf.concat
解析:concat(values, axis, name='concat')。假设t1 = [[1, 2, 3], [4, 5, 6]],t2 = [[7, 8, 9], [10, 11, 12]],那么
tf.concat([t1, t2], 0) ==> [[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]],tf.concat([t1, t2], 1) ==> [[1, 2, 3, 7, 8, 9], [4, 5, 6,
10, 11, 12]]。
10. dynamic_rnn与static_rnn [1]
解析:可以分别静态和动态构建RNN模型,如下所示:
(1)rnn_outputs, final_state = tf.nn.static_rnn(cell, rnn_inputs, initial_state=init_state)
(2)rnn_outputs, final_state = tf.nn.dynamic_rnn(cell, rnn_inputs, initial_state=init_state)
两者的区别,如下所示:
(1)使用static_rnn时,输入为一个列表,len(list)=num_step,list[0].shape=[batch_size, input_feature],输出为一
个列表,len(list)=num_step,list[0].shape=[batch_size, num_hidden]。
(2)使用dynamic_rnn时,输入为[batch_size, num_step, input_feature]的三维Tensor,输出为[batch_size,
num_step, num_hidden]的三维Tensor。
说明:dynamic_rnn可以让不同迭代传入的batch是长度不同的数据,但同一次迭代一个batch内部的所有数据长度是
固定的。但是,static_rnn不能这样,它要求每一时刻传入的数据为[batch_size, max_seq],并且在每次迭代过程中都
保持不变。
11. tf.get_default_graph和tf.reset_default_graph
解析:
(1)tf.get_default_graph():返回返回当前线程的默认图。
(2)tf.reset_default_graph():清除默认图的堆栈,并设置全局图为默认图。
12. 双曲正切函数(tanh)
解析:
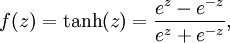
说明:tanh值域的范围为(-1,1)。
13. TensorFlow中的常亮、序列、随机数
解析:
(1)tf.ones([2, 3], int32) ==> [[1, 1, 1], [1, 1, 1]]
(2)tf.zeros([2, 3], int32) ==> [[0, 0, 0], [0, 0, 0]]
(3)假设tensor为[[1, 2, 3], [4, 5, 6]],那么tf.ones_like(tensor) ==> [[1, 1, 1], [1, 1, 1]]
(4)假设tensor为[[1, 2, 3], [4, 5, 6]],那么tf.zeros_like(tensor) ==> [[0, 0, 0], [0, 0, 0]]
(5)tf.fill([2, 3], 9) ==> [[9, 9, 9], [9, 9, 9]]
(6)tf.constant(-1.0, shape=[2, 3]) => [[-1. -1. -1.] [-1. -1. -1.]
(7)tf.linspace(10.0, 12.0, 3, name="linspace") => [ 10.0 11.0 12.0]
(8)tf.range(start,limit=None,delta=1,name='range'):返回一个tensor等差数列,该tensor中的数值在start到limit之
间,不包括limit,delta是等差数列的差值。
(9)tf.random_normal(shape,mean=0.0,stddev=1.0,dtype=tf.float32,seed=None,name=None):返回一个tensor其
中的元素的值服从正态分布。
(10)tf.truncated_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None):返回一个
tensor其中的元素服从截断正态分布。
(11)tf.random_uniform(shape,minval=0,maxval=None,dtype=tf.float32,seed=None,name=None):返回一个形状
为shape的tensor,其中的元素服从minval和maxval之间的均匀分布。
(12)tf.random_shuffle(value,seed=None,name=None):对value(是一个tensor)的第一维进行随机化。比如,
[[1,2], [2,3],[3,4]] ==> [[2,3], [1,2], [3,4]]。
(13)tf.set_random_seed(seed):设置产生随机数的种子。
14. softmax(logits, dim=-1, name=None)
解析:
(1)logits: A non-empty Tensor. Must be one of the following types: half, float32, float64.
(2)dim: The dimension softmax would be performed on. The default is -1 which indicates the last dimension.
(3)name: A name for the operation (optional).
15. tf.shape(x)和x.get_shape()区别
解析:
(1)都可以得到tensor x的尺寸。
(2)tf.shape()中x数据类型可以是tensor,list,array,而x.get_shape()中x的数据类型只能是tensor,且返回的是一
个元组。
16. tf.slice
解析:slice(input_, begin, size, name=None):Extracts a slice from a tensor.
假设input为[[[1, 1, 1], [2, 2, 2]], [[3, 3, 3], [4, 4, 4]], [[5, 5, 5], [6, 6, 6]]],如下所示:
(1)tf.slice(input, [1, 0, 0], [1, 1, 3]) ==> [[[3, 3, 3]]]
(2)tf.slice(input, [1, 0, 0], [1, 2, 3]) ==> [[[3, 3, 3], [4, 4, 4]]]
(3)tf.slice(input, [1, 0, 0], [2, 1, 3]) ==> [[[3, 3, 3]], [[5, 5, 5]]]
17. FLAGS = tf.app.flags.FLAGS
解析:
(1)tf.app.flags.DEFINE_string()
(2)tf.app.flags.DEFINE_integer()
(3)tf.app.flags.DEFINE_boolean()
(4)tf.app.flags.DEFINE_integer()
说明:TensorFlow通过设置flags来传递tf.app.run()所需的参数。
18. tf.get_default_graph()
解析:得到默认的图。
19. Graph.as_default()
解析:with tf.Graph().as_default():...:使用Graph.as_default()上下文管理器可以覆盖默认的图。
20. 多个Session和Graph
解析:
import tensorflow as tf
g1 = tf.Graph()
with g1.as_default():
c1 = tf.constant([1.0])
with tf.Graph().as_default() as g2:
c2 = tf.constant([2.0])
with tf.Session(graph=g1) as sess1:
print sess1.run(c1)
with tf.Session(graph=g2) as sess2:
print sess2.run(c2)21. TensorFlow分布式
解析:
(1)in-graph就是模型并行,将模型中不同节点分布式地运行;
(2)between-graph就是数据并行,同时训练多个batch的数据。
22. tf.contrib.framework.get_or_create_global_step
解析:get_or_create_global_step(graph=None):Returns and create (if necessary) the global step tensor.
说明:graph: The graph in which to create the global step tensor. If missing, use default graph.
23. TensorFlow Fold动态计算图工具
解析:TensorFlow Fold库会根据每个不同的输入数据建立单独的计算图,因为各个输入数据都可能具有各自不同的规
模和结构,因此计算图也应该各不相同。此后,动态批处理功能将自动组合这些计算图,以实现在输入数据内部和不
同输入数据之间的批处理操作,同时还可以通过插入一些附加指令来实现不同批处理操作之间的数据互通。
24. sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
解析:在sess中设置log_device_placement=True来查看每一部分代码在哪里执行。
参考文献:
[1] tensorflow dynamic_rnn与static_rnn使用注意:http://blog.csdn.net/daxiaofan/article/details/70197812