Java中的线程池是运用场景最多的并发框架,几乎所有需要异步或并发执行任务的程序都可以使用线程池。在开发过程中,合理地使用线程池能够带来3个好处:
第一:降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
第二:提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
第三:提高线程的可管理性。线程是稀缺资源,如果无限制地创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一分配、调优和监控。但是,要做到合理利用线程池,必须对其实现原理了如指掌。
线程池的实现原理
当向线程池提交一个任务之后,线程池是如何处理这个任务的呢?我们来看一下线程池的主要处理流程:

从图中可以看出, 当提交一个新任务到线程池时,线程池的处理流程如下:
1)线程池判断 核心线程池是否已满。如果未满,则创建一个新的工作线程来执行任务。如果核心线程池已满,则进入下个流程。
2)线程池判断 工作队列是否已满。如果工作队列未满,则将新提交的任务存储在这个工作队列里。如果工作队列已满,则进入下个流程。
3)线程池判断 线程池是否已满。如果未满,则创建一个新的工作线程来执行任务。如果已满,则交给 饱和策略来处理这个任务。
ThreadPoolExecutor执行execute()方法的示意图如下:
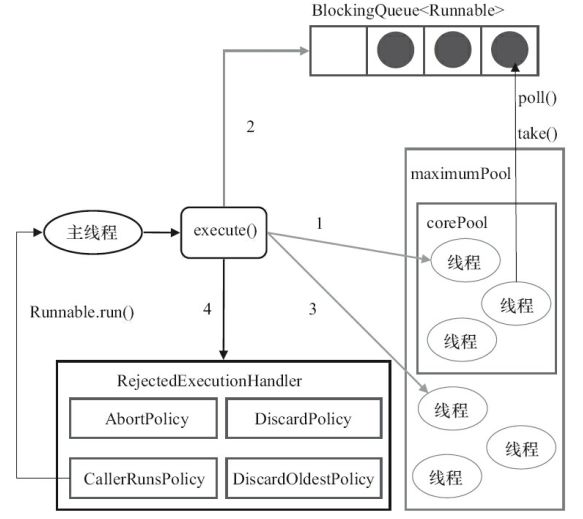
ThreadPoolExecutor执行execute方法分下面4种情况:
1)如果当前运行的线程少于corePoolSize,则创建新线程来执行任务(注意,执行这一步骤需要获取全局锁)。
2)如果运行的线程等于或多于corePoolSize,则将任务加入BlockingQueue。
3)如果无法将任务加入BlockingQueue(队列已满),则创建新的线程来处理任务(注意,执行这一步骤需要获取全局锁)。
4)如果创建新线程将使当前运行的线程超出maximumPoolSize,任务将被拒绝,并调用RejectedExecutionHandler.rejectedExecution()方法。
ThreadPoolExecutor采取上述步骤的总体设计思路,是为了在执行execute()方法时,尽可能地避免获取全局锁(那将会是一个严重的可伸缩瓶颈)。在ThreadPoolExecutor完成预热之后(当前运行的线程数大于等于corePoolSize),几乎所有的execute()方法调用都是执行步骤2,而步骤2不需要获取全局锁。
源码分析:上面的流程分析让我们很直观地了解了线程池的工作原理,让我们再通过源代码来看看是如何实现的,线程池执行任务的方法如下:

工作线程:线程池创建线程时,会将线程封装成工作线程Worker,Worker在执行完任务后,还会循环获取工作队列里的任务来执行。我们可以从Worker类的run()方法里看到这点。

ThreadPoolExecutor中线程执行任务的示意图如下:

线程池中的线程执行任务分两种情况,如下:
1)在execute()方法中创建一个线程时,会让这个线程执行当前任务。
2)这个线程执行完当前任务后,会反复从BlockingQueue获取任务来执行。
线程池的使用
线程池的创建
我们可以通过ThreadPoolExecutor来创建一个线程池。
new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime,
timeUnit,runnableTaskQueue, handler);
创建一个线程池时需要输入几个参数,如下。
1)corePoolSize(核心线程池大小):当提交一个任务到线程池时,线程池会创建一个线程来执行任务,即使其他空闲的基本线程能够执行新任务也会创建线程,等到需要执行的任务数大于核心线程池大小时就不再创建。如果调用了线程池的prestartAllCoreThreads()方法,线程池会提前创建并启动所有基本线程。
2)maximumPoolSize(线程池最大数量):线程池允许创建的最大线程数。如果队列满了,并且已创建的线程数小于最大线程数,则线程池会再创建新的线程执行任务。值得注意的是,如果使用了无界的任务队列这个参数就没什么效果。
3)keepAliveTime(线程活动保持时间):当线程池中的线程数大于corePoolSize时,多余的空闲线程等待新任务的最长时间,超过这个时间后多余的线程将被终止。所以,如果任务很多,并且每个任务执行的时间比较短,可以调大时间,提高线程的利用率。
4)timeUnit(线程活动保持时间的单位):可选的单位有天(DAYS)、小时(HOURS)、分钟(MINUTES)、毫秒(MILLISECONDS)、微秒(MICROSECONDS,千分之一毫秒)和纳秒(NANOSECONDS,千分之一微秒)。
5)runnableTaskQueue(任务队列):用于保存等待执行的任务的阻塞队列。可以选择以下几个阻塞队列:
- ArrayBlockingQueue:是一个基于数组结构的有界阻塞队列,此队列按FIFO(先进先出)原则对元素进行排序。
- LinkedBlockingQueue:一个基于链表结构的有界/无界阻塞队列,指定了容量就是有界阻塞队列,未指定容量默认为Integer.MAX_VALUE,为无界阻塞队列。此队列按FIFO排序元素,吞吐量通常要高于ArrayBlockingQueue。静态工厂方法Executors.newFixedThreadPool()和Executors.newSingleThreadExecutor()使用了这个队列。
- SynchronousQueue:一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQueue,静态工厂方法Executors.newCachedThreadPool使用了这个队列。
- PriorityBlockingQueue:一个具有优先级的无界阻塞队列。
6)RejectedExecutionHandler(饱和策略):当队列和线程池都满了,说明线程池处于饱和状态,那么必须采取一种策略处理提交的新任务。这个策略默认情况下是AbortPolicy,表示无法处理新任务时抛出异常。在JDK 1.5中Java线程池框架提供了以下4种策略:
- AbortPolicy:直接抛出异常。
- CallerRunsPolicy:只用调用者所在线程来运行任务。
- DiscardOldestPolicy:丢弃队列里最近的一个任务,并执行当前任务。
- DiscardPolicy:不处理,丢弃掉。
当然,也可以根据应用场景需要来实现RejectedExecutionHandler接口自定义策略。如记录日志或持久化存储不能处理的任务。
7)ThreadFactory:用于设置创建线程的工厂,可以通过线程工厂给每个创建出来的线程设置更有意义的名字。使用开源框架guava提供的ThreadFactoryBuilder可以快速给线程池里的线程设置有意义的名字,代码如下:
new ThreadFactoryBuilder().setNameFormat("XX-task-%d").build();
向线程池提交任务
可以使用两个方法向线程池提交任务,分别为execute()和submit()方法。
void execute(Runnable task)
Future submit(Callable task)
Future submit(Runnable task, T result)
Future submit(Runnable task)
execute()方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功。通过以下代码可知execute()方法输入的任务是一个Runnable类的实例:

submit()方法用于提交需要返回值的任务。线程池会返回一个future类型的对象,通过这个future对象可以判断任务是否执行成功,并且可以通过future的get()方法来获取返回值,get()方法会阻塞当前线程直到任务完成,而使用get(long timeout,TimeUnit unit)方法则会阻塞当前线程一段时间后立即返回,这时候有可能任务没有执行完。

关闭线程池
可以通过调用线程池的shutdown或shutdownNow方法来关闭线程池。 shutdown() 方法会等待线程都执行完毕之后再关闭,但是如果调用的是 shutdownNow() 方法,则相当于调用每个线程的 interrupt() 方法。
只要调用了这两个关闭方法中的任意一个,isShutdown方法就会返回true。当所有的任务都已关闭后,才表示线程池关闭成功,这时调用isTerminated方法会返回true。至于应该调用哪一种方法来关闭线程池,应该由提交到线程池的任务特性决定,通常调用shutdown方法来关闭线程池,如果任务不一定要执行完,则可以调用shutdownNow方法。
如果只想中断 Executor 中的一个线程,可以通过使用 submit() 方法来提交一个线程,它会返回一个 Future 对象,通过调用该对象的 cancel(true) 方法就可以中断线程。
合理地配置线程池
要想合理地配置线程池,就必须首先分析任务特性,可以从以下几个角度来分析。
- 任务的性质:CPU密集型任务、IO密集型任务和混合型任务。
- 任务的优先级:高、中和低。
- 任务的执行时间:长、中和短。
- 任务的依赖性:是否依赖其他系统资源,如数据库连接。
性质不同的任务可以用不同规模的线程池分开处理。CPU密集型任务应配置尽可能小的线程,如配置Ncpu + 1个线程的线程池。由于IO密集型任务线程并不是一直在执行任务,则应配置尽可能多的线程,如2 * Ncpu。混合型的任务,如果可以拆分,将其拆分成一个CPU密集型任务和一个IO密集型任务,只要这两个任务执行的时间相差不是太大,那么分解后执行的吞吐量将高于串行执行的吞吐量。如果这两个任务执行时间相差太大,则没必要进行分解。
可以通过Runtime.getRuntime().availableProcessors()方法获得当前设备的CPU个数。
优先级不同的任务可以使用优先级队列PriorityBlockingQueue来处理。它可以让优先级高的任务先执行。
注意:
1)如果一直有优先级高的任务提交到队列里,那么优先级低的任务可能永远不能执行。
2)执行时间不同的任务可以交给不同规模的线程池来处理,或者可以使用优先级队列,让执行时间短的任务先执行。
3)依赖数据库连接池的任务,因为线程提交SQL后需要等待数据库返回结果,等待的时间越长,则CPU空闲时间就越长,那么线程数应该设置得越大,这样才能更好地利用CPU。
建议使用有界队列。有界队列能增加系统的稳定性和预警能力,可以根据需要设大一点,比如几千。有一次,我们系统里后台任务线程池的队列和线程池全满了,不断抛出抛弃任务的异常,通过排查发现是数据库出现了问题,导致执行SQL变得非常缓慢,因为后台任务线程池里的任务全是需要向数据库查询和插入数据的,所以导致线程池里的工作线程全部阻塞,任务积压在线程池里。如果当时我们设置成无界队列,那么线程池的队列就会越来越多,有可能会撑满内存,导致整个系统不可用,而不只是后台任务出现问题。当然,我们的系统所有的任务是用单独的服务器部署的,我们使用不同规模的线程池完成不同类型的任务,但是出现这样问题时也会影响到其他任务。
线程池的监控
如果在系统中大量使用线程池,则有必要对线程池进行监控,方便在出现问题时,可以根据线程池的使用状况快速定位问题。可以通过线程池提供的参数进行监控,在监控线程池的时候可以使用以下属性:
- taskCount:线程池需要执行的任务数量。
- completedTaskCount:线程池在运行过程中已完成的任务数量,小于或等于taskCount。
- largestPoolSize:线程池里曾经创建过的最大线程数量。通过这个数据可以知道线程池是否曾经满过。如该数值等于线程池的最大大小,则表示线程池曾经满过。
- getPoolSize:线程池的线程数量。如果线程池不销毁的话,线程池里的线程不会自动销毁,所以这个大小只增不减。
- getActiveCount:获取活动的线程数。
通过扩展线程池进行监控。可以通过继承线程池来自定义线程池,重写线程池的beforeExecute、afterExecute和terminated方法,也可以在任务执行前、执行后和线程池关闭前执行一些代码来进行监控。例如,监控任务的平均执行时间、最大执行时间和最小执行时间等。
这几个方法在线程池里是空方法。
protected void beforeExecute(Thread t, Runnable r) { }