1.前言
2020年真的太难了!(来自一个已经被迫在家隔离了29天的农村娃的无力吐槽)
2020年对于我来说原本也会是一个难忘的一年,新年女朋友第一次来我家,6月份硕士生涯结束,正式步入996的美好生活!没曾想2020年会如此多事,突如其来的疫情(2019-nCoV),也将我原本的计划彻底打乱。唯一让我感到好受一点的可能就是难得在家陪父母这么长时间了吧。
2.研究目的及意义
这次疫情让我感受最深的,除了隔离在家的烦闷和不便,那就是随着疫情漫天飞舞的谣言。
平时的生活中我们也会经常看到、听到各种各样的虚假信息,甚至谣言。可能因为疫情的原因,相关的谣言和虚假信息格外的多,朋友圈、微信群经常能够看到。说实话,有些谣言根据经验大体可以看出真假,但是有很多谣言是真的很难分辨,今天才信以为真,明天就有人出来辟谣,偶尔还会再来一次反辟谣,让人非常烦恼。
正是谣言的滋扰让我萌生了用模型来自动分辨谣言的想法。后文中,我们将谣言、虚假新闻等统称为虚假信息。
3.研究背景
在实验之前,我做了些简单的调研,发现虚假信息自动化鉴别的研究由来已久。
3.1 为什么虚假信息如此盛行
虚假信息的产生,绝大多数是出于利益角度的考量,这里的利益除了金钱以外,也可能是政治上的利益。例如通过编造虚假信息来引起关注,从而获取广告收入,或者让自己的产品变得畅销。政治上,为了达到操纵和宣传的目的,有时候也会故意编造一些虚假信息。
大量虚假信息的产生和传播对于社会、经济的发展非常不利,对于我们个人来说也是一件令人厌烦的事。
3.2 虚假信息自动化鉴别的难点及研究方向
难点1:一些虚假信息隐藏的较好,会利用一些真的信息来增加迷惑性,有时甚至会借助一些权威人士或机构来提升信息的可信度。
难点2:虚假信息的判别缺乏及时、权威的数据。很多虚假信息都是针对当前的实事,例如此次疫情。对于一些缺乏相关经验的人来说,很难辨识真假。而缺乏相应的数据库,也很难由模型自动化鉴别。
虚假信息自动化鉴别是一个典型的文本分类问题,我们可以直接使用一些文本分类的算法或模型,但是其效果也因数据、场景而不同。
除了直接针对虚假信息的文本内容下手,一些研究者将方向拓展到对虚假信息制造者的用户特征、发文特征以及平台特征的研究。
虚假信息鉴别是自然语言处理领域的热门研究方向之一,并且依然面临着诸多的困难和挑战。
3.3 相关论文和数据集
在撰写本文的过程中,本人搜集整理了一些相关的论文和数据集,与本文配套的代码、数据以及训练好的模型打包在了一起。获取方式在文章末尾。

4.实验:尝试用Bert对疫情谣言进行分类
4.1 数据集
实验中使用了两部分数据,一部分是从腾讯的较真平台爬取的疫情辟谣数据,另一部分是从biendata平台获取的比赛数据。
图4.1 腾讯较真平台
腾讯较真提供了疫情期间的辟谣数据,目前其数据量较少(在爬取时只有310条),此外也没有找到其它更好的疫情谣言数据的来源。这部分数据爬取的代码也已打包在了一起。
biendata平台获取的比赛数据是微博数据,有38000多条,但是数据质量较为一般,并且有少量重复。示例数据如下(标签为0的是真实信息数据,标签为1的是虚假信息数据):

图4.2 biendata平台提供的微博数据示例
4.2 模型
这部分简单介绍一下我们所使用的BERT模型。
4.2.1 BERT的网络结构
BERT(Bidirectional Encoder Representations from Transformers)是Google在2018年发表的论文“Bert: Pre-training of deep bidirectional transformers for language understanding”中提出的。
BERT吸取了Transformer模型的一些经验,Transformer是Google的机器翻译团队在2017年提出的一种模型,该模型抛弃了传统的卷积、循环神经网络结构,而仅以Attention机制解决机器翻译任务,并且取得了很好的效果。Transformer的模型结构下: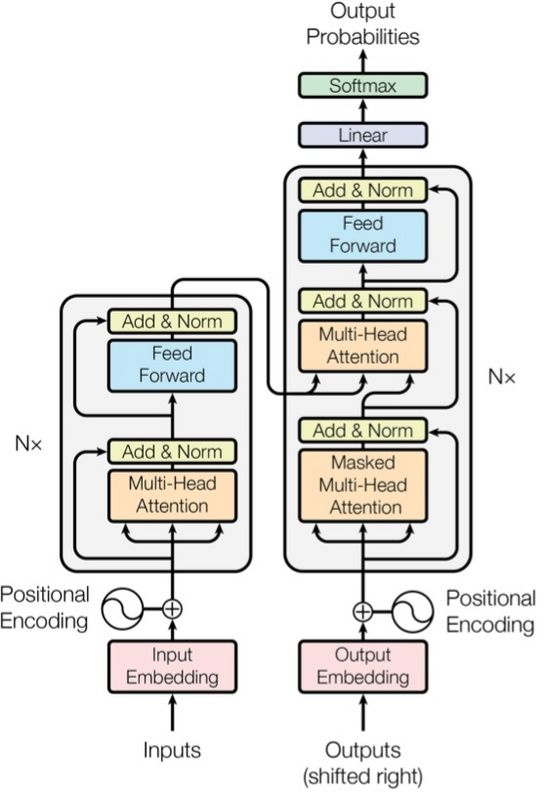
图4.3 Transformer模型结构图
Transformer由编码器(Encoder)和解码器(Decoder)两部分组成,对应上图左右两部分。Transformer的Encoder部分由多个上图左侧所示的块(Block)堆叠而成。
BERT的结构如下所示: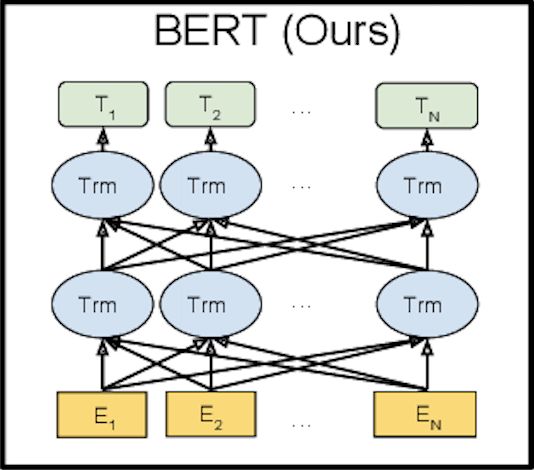
图4.4 BERT模型结构图
BERT将网络结构中的每一个神经元用前面介绍的Transformer的编码块取代,并且是一个双向的网络结构。
4.2.2 BERT的输入
BERT的输入由三种Embedding叠加而成,如下图所示,分别是“Token Embeddings”、“Segment Embeddings”和“Position Embeddings”。
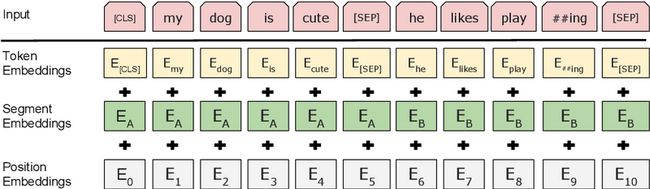
图4.5 BERT模型的输入示意图
输入BERT的可以是单个句子(例如当下游任务是文本分类时),也可以是一对句子(例如当下游任务是QA时)。如上图所示,当输入的是一对句子时,句子之间会添加一个[SEP]标记。
构成BERT输入的三个Embedding中,“Token Embeddings”是输入文本中每个词的词向量。“Segment Embeddings”是句子的编码向量,该句向量会叠加到句子中每一个词的词向量上。“Position Embeddings”是句子中每个词在该句子中位置信息的编码向量,同样也会叠加到每个词向量上。
4.2.3 BERT的训练方式
BERT的训练包括两个部分:Masked Language Model和Next Sentence Prediction。
Masked Language Model部分的训练,会随机掩盖一些Token,然后通过上下文来预测这个Token。该方法与用CBOW来训练Word2Vec相似,主要的不同是前者是双向的,并且使用了Transformer中的结构来提取特征。
Next Sentence Prediction部分的训练是为了学习句子间的前后关系,即判断句子B是否是句子A的下一句。该部分的考量主要是基于QA等下游任务。
4.2.4 基于BERT的下游任务
基于预训练的BERT模型,我们可以用来实现诸如文本分类、QA、序列标注(例如分词、实体识别等)等任务。
4.3 实验过程和结果
Google官方提供了BERT模型的TensorFlow实现(https://github.com/google-res...),本实验部分也是基于官方的代码。本实验的代码结构如下:
bert_master:Google官方提供的代码
bert_model_zh_cn:官方提供的基于中文的预训练好的BERT模型
data:实验使用的数据
get_data:爬取腾讯较真平台数据的代码
output:预测阶段的输出存放在此
saved_model:保存我们基于自己的数据微调后训练好的BERT模型(使用疫情数据、含部分微博数据)
saved_model_ori:保存我们基于自己的数据微调后训练好的BERT模型(使用微博数据)
calculate_acc.py:基于预测结果计算混淆矩阵和准确率
fake_news_classifier.py:基于BERT实现分类的代码部分
4.3.1 使用微博数据训练和验证模型
首先,我们使用微博数据来训练和检测模型的效果。混淆矩阵和一些评价指标如下:
用微博数据训练和测试的效果看上去还不错,98%的准确率,其他指标也没有大问题。
4.3.2 使用微博数据训练的模型预测疫情谣言
将微博数据训练的模型直接拿来预测疫情谣言数据的结果如下:

首先,准确率只有28%,咋一看感觉还没有直接懵的准确率高。从混淆矩阵来看,导致准确率低的原因在于大量假信息被预测成了真信息(290条假信息有218条被预测成了真信息)。
分析原因,可能是由于疫情相关的新闻数据在内容上与微博的数据有很大偏差,特征上没有太多的相通之处,直接使用基于微博数据训练的模型,效果并不佳。
4.3.3 使用疫情谣言数据训练和验证模型
最后我们使用疫情谣言数据直接训练BERT模型。不过这里有一个问题,我们拥有的疫情相关数据太少,并且样本极不平衡。我们总共只有310条疫情相关数据,而其中只有20条是真实信息的数据,另外290条是虚假信息。
这里为了平衡一些训练样本,从微博数据中获取了120条标注为真实信息的数据,增加到训练数据中。
最终效果如下:
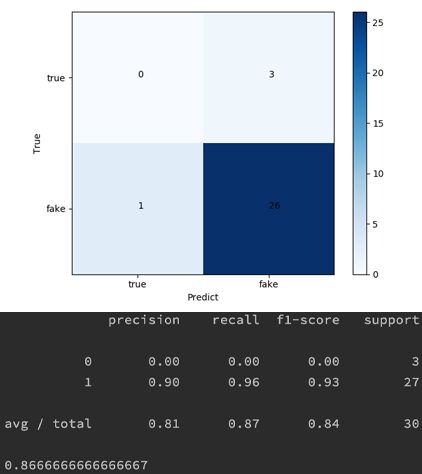
由于数据实在太少,所以测试集只用了30条数据。从准确率来看,虽然有86.66%,但是仔细分析混淆矩阵的话,这个准确率可能会比真实值要偏高。另外,测试集中只有3条真实信息数据,并且全都被预测成了虚假信息。
由于数据量的不足,该结果只能作为参考。
总结与展望
1.通过实验我们能够看到,直接使用文本分类的模型来自动鉴别虚假信息,是能够取得一定效果的,在微博数据上的实验一定程度上佐证了这一点。
2.利用文本分类解决虚假信息的自动鉴别有其局限性。当我们用微博数据训练好模型后,再来预测疫情数据,其效果并不好。究其根本原因是因为我们的训练数据没有覆盖到疫情相关的数据特征。因此,数据的规模和数据的全面性是决定模型适用范围和效果的关键。
感兴趣的朋友可以基于本人的实验继续探究,不过最好能够先解决数据量不足的问题。欢迎大家一起交流!
数据、代码和资料获取
本文实验部分的代码已上传Github:https://github.com/lqhou/NLP_...