注意力机制(一)——在机器翻译中的应用
最近在看注意力机制,想要搞明白三个问题:①注意力机制的运行机制 ②解决了什么问题 ③有什么特点。因为它最先被引入机器翻译,所以先从机器翻译看起。主要是资料的整合,我自己的思考是蓝色的部分
目录
1、自然语言处理的不定长问题——seq2seq的引入
单层网络结构(1v1)
经典的RNN结构(N vs N)
N VS 1
1 VS N
N VS M
2、seq2seq模型——编码器和解码器
图解主要思路
数学理解
预处理
编码器encoder处理
解码器decoder处理
3、编码器和解码器的局限性——注意力模型引入
主要思想
Attention is All You Need
回顾:
Attention定义
Multi-Head Attention
Self Attention
Position Embedding
1、自然语言处理的不定长问题——seq2seq的引入
单层网络结构(1v1)
也就是单个神经元的工作原理。其中 X是输入值,W是输入值对应的权重,b是偏差数。神经元进行判断和计算(这里的F激活函数最常见是Sigmund的函数,还有RELU等变种)
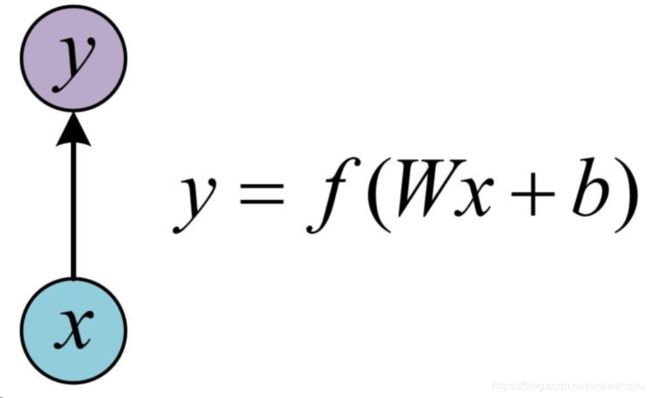
经典的RNN结构(N vs N)
解决的是序列性的问题。主要特点是具有连续性,有时顺序是重要的。RNN引入了隐状态h(hidden state)的概念,h可以对序列形的数据提取特征,接着再转换为输出。
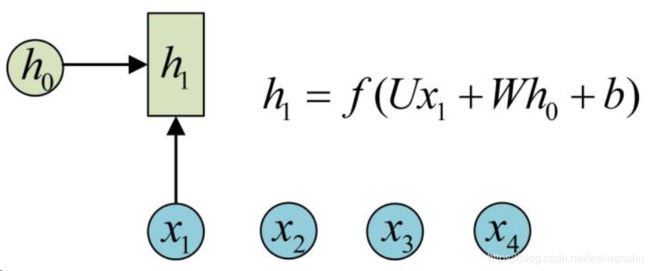
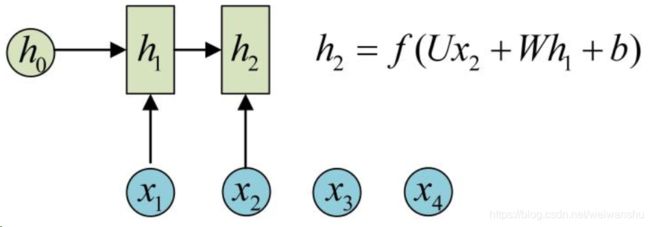
h2的计算和h1类似。每一步使用的参数U、W、b都一样,每个步骤的参数共享的,这是RNN的重要特点。得到输出值的方法就是在U、W、b的情况下直接通过h进行计算。训练的方法就是通过最大似然法调整U、W、b,使训练的样本Y的概率最大。
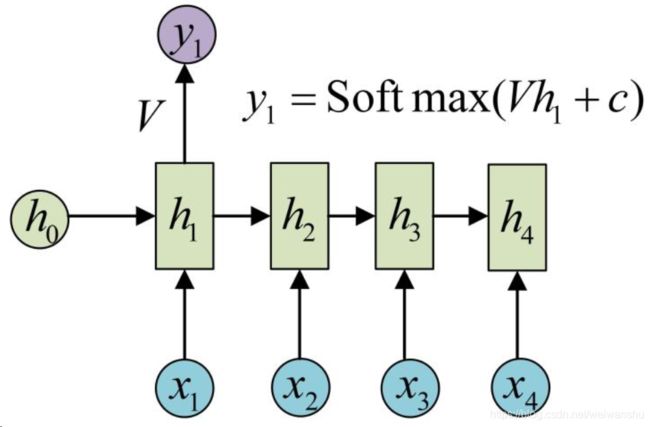
它的输入是x1, x2, .....xn,输出为y1, y2, ...yn,也就是说,输入和输出序列必须要是等长的。
N VS 1
有的时候,我们要处理的问题输入是一个序列,输出是一个单独的值而不是序列,应该怎样建模呢?实际上,我们只在最后一个h上进行输出变换就可以了。这种结构通常用来处理序列分类问题。

1 VS N
1 VS N的结构可以处理的问题:① 从图像生成文字(image caption),此时输入的X就是图像的特征,而输出的y序列就是一段句子 ② 从类别生成语音或音乐等
输入不是序列而输出为序列的情况怎么处理?我们可以只在序列开始进行输入计算:
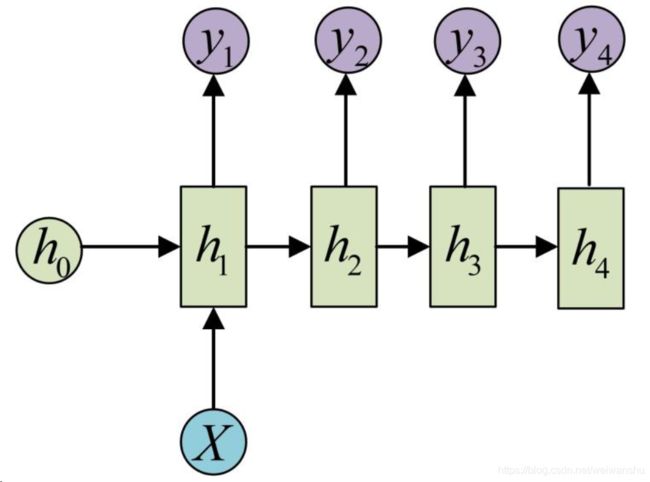
还有一种结构是把输入信息X作为每个阶段的输入:

N VS M
机器翻译中,源语言和目标语言的句子往往并没有相同的长度,需要解决的问题可以抽象为N vs M。这种结构又叫Encoder-Decoder模型,也可以称之为Seq2Seq模型。
2、seq2seq模型——编码器和解码器
图解主要思路
主要的思路是Encoder-Decoder结构先将输入数据通过Encoder编码成一个上下文向量c:拿到c之后,就用另一个RNN(Decoder)网络对其进行解码得到最后的输出值。(其实GAN也是运用了Encoder-Decoder结构,有时间写一下)
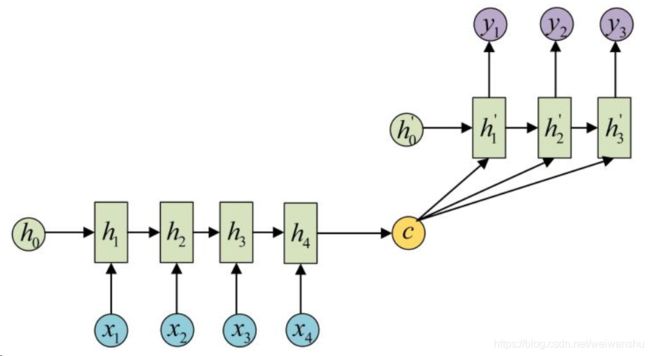
数学理解
编码器(encoder)和解码器(decoder)分别对应着输入序列和输出序列的两个循环神经网络(RNN),通常分别在输出序列和输入序列头尾加上
预处理
深度学习做NLP的方法,基本上都是先将句子分词,然后每个词转化为对应的词向量序列。这样一来,每个句子都对应的是一个矩阵X=(x1,x2,…,xt),其中xi都代表着第i个词的词向量(行向量),维度为d维。
也就是说一个包含n个词的句子q,可以转化为 n×d 的向量Q,d维为词向量的维度。
编码器encoder处理
编码器的作用是把一个不定长的输入序列转换成一个定长的背景向量c,该背景向量包含了输入序列的信息,常用的编码器是循环神经网络。
 ht 表示在t时刻的隐藏变量来源于 t时刻的输入和上一时刻的隐藏变量
ht 表示在t时刻的隐藏变量来源于 t时刻的输入和上一时刻的隐藏变量
又因为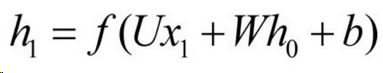 ,所以需要训练的是 U、W 矩阵。最终模型仍然解决的是U,W的求解问题。
,所以需要训练的是 U、W 矩阵。最终模型仍然解决的是U,W的求解问题。
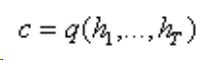 c背景向量就是总结输入序列所对应的各个隐藏层变量,因为是一个编码器递归迭代的过程,所以我认为c可以代指训练过程的信息(?)。
c背景向量就是总结输入序列所对应的各个隐藏层变量,因为是一个编码器递归迭代的过程,所以我认为c可以代指训练过程的信息(?)。
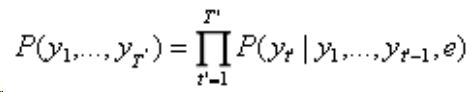 是encoder描述输出序列的概率函数,一般使用最大似然函数。这里等式右边应该是 c 不是 e ,主要意思是,在 c 的条件下使得到 y1...yT'的概率。而 c 表现的是U和W的信息。
是encoder描述输出序列的概率函数,一般使用最大似然函数。这里等式右边应该是 c 不是 e ,主要意思是,在 c 的条件下使得到 y1...yT'的概率。而 c 表现的是U和W的信息。
 是encoder最大似然函数损失函数,目标是最小化损失函数。
是encoder最大似然函数损失函数,目标是最小化损失函数。
解码器decoder处理
解码器的处理就是通过 y1...yT' 值求解最小化损失函数的过程,因为是编码器是使用RNN进行递归编码的,所以解码器也使用RNN来递归解码。也就是decoder在对encoder的loss目标解码。再次重申一遍问题是:
源语言→→编码→→解码→→目标语言
目标是得到编码和解码的方法,也就是对编码方法 U、W矩阵进行求解,让loss最小,也就是得到目标语言单词组合的可能性最大。
训练的数据形式是 <源语言,目标语言>的组合
![]() 公式表示的是编码器p函数。
公式表示的是编码器p函数。
![]() 解码器隐层s1,s2,..,st',是通过c背景向量拿到编码器中的信息,然后可能再通过RNN进行传递输出y1,y2,...,yt'。在s1时刻我们需要的是s0,y0,c的信息得到s1,然后S1通过变化再得到y1。可以说yt和St有关,St取决于St-1,yt-1,c。很自然,RNN中 t 时刻的隐层状态取决于 t - 1时刻的状态,在解码器实例中还需要目前已经有的 c 的参数,注意这里并不是指 U、W已经得到了。
解码器隐层s1,s2,..,st',是通过c背景向量拿到编码器中的信息,然后可能再通过RNN进行传递输出y1,y2,...,yt'。在s1时刻我们需要的是s0,y0,c的信息得到s1,然后S1通过变化再得到y1。可以说yt和St有关,St取决于St-1,yt-1,c。很自然,RNN中 t 时刻的隐层状态取决于 t - 1时刻的状态,在解码器实例中还需要目前已经有的 c 的参数,注意这里并不是指 U、W已经得到了。
可以使用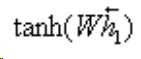 只是一个初始化的选项,理论上其实随机输入也行吧?
只是一个初始化的选项,理论上其实随机输入也行吧?
3、编码器和解码器的局限性——注意力模型引入
主要思想
上式可以发现发现输出序列的每一个时刻获得的信息一定只能通过c获得,在解码器中我们每一时刻获得的c都是一样的没有变化的,但是假设我们希望输入序列第一时刻的c只对应输出序列对应的第一时刻和第二时刻,而输入序列的第二时刻只对应输出序列的第三时刻。我们希望输入每一个部分分布的注意力是不一样的,这就是注意力机制。

我们假设ct'是c背景向量的不同时刻不同的c,每一时刻的c对编码器中所对应的每个隐藏层进行一个加权平均,这个加权平均的权重是我们学习的参数,我们分配对应时刻隐藏h的权重的大小就是输入时刻每一时刻的注意力的大小。
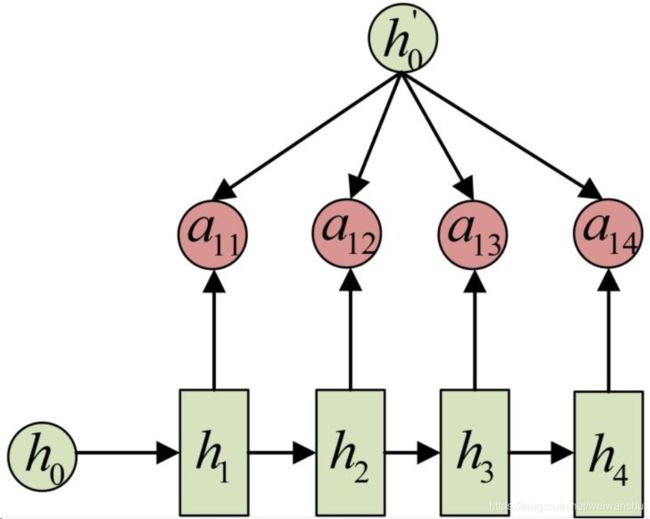
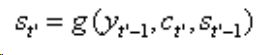 原式是g函数的变形,这里表示 C 随 t 的变化而变化
原式是g函数的变形,这里表示 C 随 t 的变化而变化
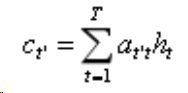 这个公式就是一个加权平均得到一个c
这个公式就是一个加权平均得到一个c
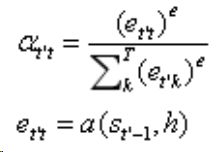 一个阿尔法表达式用一个softmax进行概率分布。而下面的a的设计也可以依据实际情况变换比如
一个阿尔法表达式用一个softmax进行概率分布。而下面的a的设计也可以依据实际情况变换比如
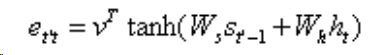
Attention is All You Need
回顾:
深度学习做NLP的方法,基本上都是先将句子分词,然后每个词转化为对应的词向量序列。这样一来,每个句子都对应的是一个矩阵X=(x1,x2,…,xt),其中xi都代表着第i个词的词向量(行向量),维度为d维,故X∈Rn×d。这样的话,问题就变成了编码这些序列了。
第一个基本的思路是RNN层RNN结构本身比较简单,也很适合序列建模,但RNN的明显缺点之一就是无法并行,因此速度较慢,这是递归的天然缺陷。另外我个人觉得RNN无法很好地学习到全局的结构信息,因为它本质是一个马尔科夫决策过程。
![]()
第二个思路是CNN层,其实CNN的方案也是很自然的,窗口式遍历,CNN方便并行,而且容易捕捉到一些全局结构信息。
![]()
Google的大作提供了第三个思路:纯Attention!单靠注意力就可以!RNN要逐步递归才能获得全局信息,因此一般要双向RNN才比较好;CNN事实上只能获取局部信息,是通过层叠来增大感受野;Attention的思路最为粗暴,它一步到位获取了全局信息!它的解决方案是:
![]()
其中A,B是另外一个序列(矩阵)。如果都取A=B=X,那么就称为Self Attention,它的意思是直接将xt与原来的每个词进行比较,最后算出yt!
Attention定义
矩阵定义如下:
这里用的是跟Google的论文一致的符号,其中![]()
如果忽略激活函数softmax的话,那么事实上它就是三个n×dk,dk×m,m×dv的矩阵相乘。最后的结果就是一个n×dv的矩阵。于是我们可以认为:这是一个Attention层,将n×dk的序列Q编码成了一个新的n×dv的序列
逐个向量来看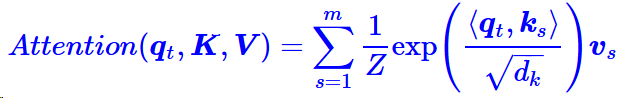
其中Z是归一化因子。事实上q,k,v分别是query,key,value的简写,K,V是一一对应的,它们就像是key-value的关系,那么上式的意思就是通过qt这个query,通过与各个ks内积的并softmax的方式,来得到qt与各个vs的相似度,然后加权求和,得到一个dv维的向量。其中因子√dk起到调节作用,使得内积不至于太大(太大的话softmax后就非0即1了,不够“soft”了)。
所以我一直想搞清楚的问题,如何得到注意力参数,也就是编码器各个状态应该怎么和解码器状态进行匹配的问题得到了解答:
query:源语言句子Q中的一个词qt,映射到dk空间,得到的一个由dk维张量表示的词向量
value:目标语言句子(m个词)中的词,表示为dv维的向量空间中,得到的一个由dv维张量表示的词向量
key:转换矩阵,主要作用是把dk维的qt转化为dv维张量表示的词向量
为什么要转换矩阵?因为要把词当成向量的话,同维才能计算。
所以匹配问题也就是两个dk维度上的词向量的距离
之后再把得到的加权和参数代替一开始计算的结果
Multi-Head Attention
不过从形式上看,它其实就再简单不过了,就是把Q,K,V通过参数矩阵映射一下,然后再做Attention,把这个过程重复做h次,结果拼接起来就行了
![]()
这里![]() 然后
然后
![]()
最后得到一个n×(hdv)的序列。所谓“多头”(Multi-Head),就是只多做几次同样的事情(参数不共享),然后把结果拼接。
Self Attention
到目前为止,对Attention层的描述都是一般化的,我们可以落实一些应用。比如,如果做阅读理解的话,Q可以是篇章的词向量序列,取K=V为问题的词向量序列,那么输出就是所谓的Aligned Question Embedding
所谓Self Attention,其实就是Attention(X,X,X),X就是前面说的输入序列。也就是说,在序列内部做Attention,寻找序列内部的联系。Google论文的主要贡献之一是它表明了内部注意力在机器翻译(甚至是一般的Seq2Seq任务)的序列编码上是相当重要的,而之前关于Seq2Seq的研究基本都只是把注意力机制用在解码端。类似的事情是,目前SQUAD阅读理解的榜首模型R-Net也加入了自注意力机制,这也使得它的模型有所提升。
当然,更准确来说,Google所用的是Self Multi-Head Attention:
![]()
Position Embedding
然而,只要稍微思考一下就会发现,这样的模型并不能捕捉序列的顺序!换句话说,如果将K,V按行打乱顺序(相当于句子中的词序打乱),那么Attention的结果还是一样的。这就表明了,到目前为止,Attention模型顶多是一个非常精妙的“词袋模型”而已。
结合位置向量和词向量有几个可选方案,可以把它们拼接起来作为一个新向量,也可以把位置向量定义为跟词向量一样大小,然后两者加起来。FaceBook的论文和Google论文中用的都是后者。直觉上相加会导致信息损失,似乎不可取,但Google的成果说明相加也是很好的方案。看来我理解还不够深刻。
这问题就比较严重了,大家知道,对于时间序列来说,尤其是对于NLP中的任务来说,顺序是很重要的信息,它代表着局部甚至是全局的结构,学习不到顺序信息,那么效果将会大打折扣(比如机器翻译中,有可能只把每个词都翻译出来了,但是不能组织成合理的句子)。
于是Google再祭出了一招——Position Embedding,也就是“位置向量”,将每个位置编号,然后每个编号对应一个向量,通过结合位置向量和词向量,就给每个词都引入了一定的位置信息,这样Attention就可以分辨出不同位置的词了。
这里插一句embedding——“嵌入层将正整数(下标)转换为具有固定大小的向量”。
嵌入层 Embedding呢? 两大原因:
1、使用One-hot 方法编码的向量会很高维也很稀疏。
2、训练神经网络的过程中,每个嵌入的向量都会得到更新。
Embedding层的作用:处理句子“deep learning is very deep”
第一步 通过索引对该句子进行编码,这里我们给每一个不同的单词分配一个索引 1 2 3 4 1
第二步 我们要决定每一个索引需要分配多少个‘潜在因子’,这大体上意味着向量长度,通用情况是32和50
简而言之,嵌入层embedding在这里做的就是把单词“deep”用向量[.32, .02, .48, .21, .56, .15]来表达
然而并不是每一个单词都会被一个向量来代替,而是被替换为用于查找嵌入矩阵中向量的索引。这样我们就可以探索在高维空间中哪些词语之间具有彼此相似性。
参考文献:
帮助理解机器翻译的文章 完全图解RNN、RNN变体、Seq2Seq、Attention机制
帮助阅读Attention is All You Need的文章 《Attention is All You Need》浅读(简介+代码)以及 神经机器翻译 之 谷歌 transformer 模型
帮助数学理解的文章 编码器-解码器(seq2seq)和注意力机制
帮助阅读代码的文章 注意力模型的一个实例代码的实现与分析
帮助理解embedding https://blog.csdn.net/u010412858/article/details/77848878