一 Post 请求
在爬虫文件中重写父类的start_requests(self)方法
- 父类方法源码(Request):
def start_requests(self): for url in self.start_urls: yield scrapy.Request(url=url,callback=self.parse)
- 重写该方法(FormRequests(url=url,callback=self.parse,formdata=data))
def start_requests(self): data={ 'kw': 'xml', } for url in self.start_urls:
#post请求,并传递参数
yield scrapy.FormRequest(url=url,callback=self.parse,formdata=data)
二 多页面手动爬去数据
import scrapy from QiubaiPagePro.items import QiubaipageproItem class QiubaiSpider(scrapy.Spider): name = 'qiubai' # allowed_domains = ['xxx.com'] start_urls = ['https://www.qiushibaike.com/text/'] ''' https://www.qiushibaike.com/text/page/13/ ''' url='https://www.qiushibaike.com/text/page/%d/' #手动发起请求 page=1 def parse(self, response): div_list = response.xpath('//div[@id="content-left"]/div') for div in div_list: author = div.xpath('./div[1]/a[2]/h2/text()').extract_first() content = div.xpath('./a[1]/div[@class="content"]/span//text()').extract() content = "".join(content) #实例管道对象 item=QiubaipageproItem() item['author']=author item['content']=content.strip() yield item
- 1 构造请求url的格式
url='https://www.qiushibaike.com/text/page/%d/' #手动发起请求 page=1
- 2 手动发送请求
if self.page<=12: self.page += 1 url=format(self.url%self.page) #手动发送请求 yield scrapy.Request(url=url,callback=self.parse)
三 五大核心组件
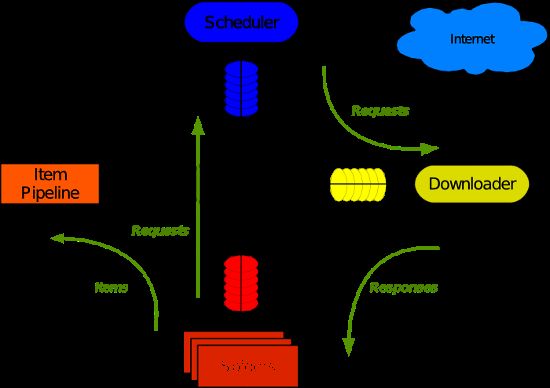
- 引擎(Scrapy)用来处理整个系统的数据流,触发事务(框架核心)
- 调度器(Scheduler) 用来接收应勤发过来的请求,压入队列中,并在引擎再次发起请求的时候返回,可以想象成一个url的优先队列,他决定下一个要爬取的网址是什么,同时去重复的网址。
- 下载器(Downloader)用于下载页面内容,并将页面内容返回给引擎。
- 爬虫(Spider)爬虫主要是干活的,用于从特定的网页中提取自己需要的信息。用户可以在这里面编写程序,从网页中提取链接,让scrapy继续爬取下一个页面。
- 项目管理(Pipeline)负责处理爬虫从网页中爬取的数据,主要功能是持久存储,验证实体的有效性,清楚不需要的信息,当也被爬虫解析后,将被发送到项目管道,经过几个特点的次序处理数据
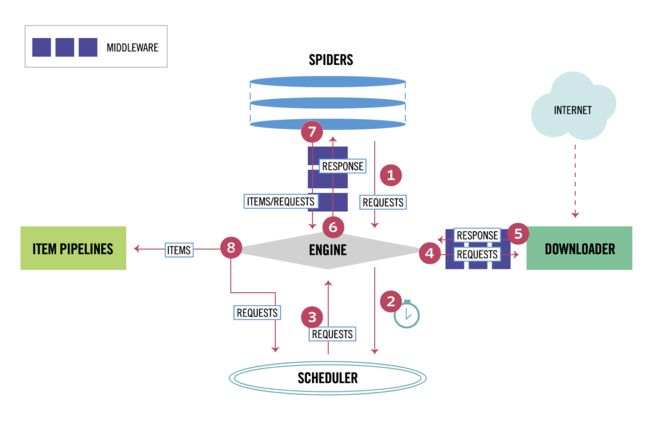
四 下载中间件
class QiubaipageproDownloaderMiddleware(object): #拦截请求 def process_request(self, request, spider): #设置代理 request.meta['proxy']='119.176.66.90:9999' print('this is process_request') #拦截响应 def process_response(self, request, response, spider): # Called with the response returned from the downloader. # Must either; # - return a Response object # - return a Request object # - or raise IgnoreRequest return response #拦截发生异常的请求对象 def process_exception(self, request, exception, spider): # 设置代理 request.meta['proxy'] = 'https:119.176.66.90:9999' print('this is process_request')
setting中开启下载中间键
DOWNLOADER_MIDDLEWARES = { 'QiubaiPagePro.middlewares.QiubaipageproDownloaderMiddleware': 543, }
五 boss直聘爬取
- bossspider.py 爬虫文件
# -*- coding: utf-8 -*- import scrapy from BossPro.items import BossproItem class BossspiderSpider(scrapy.Spider): name = 'bossspider' # allowed_domains = ['boss.com'] start_urls = ['https://www.zhipin.com/c101280600/?query=python%E7%88%AC%E8%99%AB&ka=sel-city-101280600'] def parse(self, response): li_list=response.xpath('//div[@class="job-list"]/ul/li') for li in li_list: job_name=li.xpath('.//div[@class="job-title"]/text()').extract_first() company_name=li.xpath('.//div[@class="info-company"]/div[1]/h3/a/text()').extract_first() detail_url='https://www.zhipin.com'+li.xpath('.//div[@class="info-primary"]/h3/a/@href').extract_first() #实例项目对象,给管道传输数据 item=BossproItem() item['job_name']=job_name.strip() item['company_name']=company_name.strip() #手动发起get请求,并通过meta给回调函数传参 yield scrapy.Request(url=detail_url,callback=self.parse_detail,meta={'item':item}) def parse_detail(self,response): #从meta中取出参数item item=response.meta['item'] job_desc = response.xpath('//*[@id="main"]/div[3]/div/div[2]/div[2]/div[1]/div//text()').extract() job_desc = ''.join(job_desc).strip() job_desc=job_desc.replace(';','\n') job_desc = job_desc.replace(';', '\n') job_desc = job_desc.replace('。', '\n') item['job_desc']=job_desc yield item
- items.py
import scrapy class BossproItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() job_name = scrapy.Field() company_name = scrapy.Field() job_desc = scrapy.Field()
- pipelines.py
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html class BossproPipeline(object): fp=None def open_spider(self,spider): self.fp=open('boss.txt','w',encoding='utf-8') def process_item(self, item, spider): # print(item) self.fp.write(item['job_name']+":"+item['company_name']) self.fp.write('\n'+item['job_desc']+'\n\n') return item def close_spider(self,spider): pass
- setings.py
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36' #UA ROBOTSTXT_OBEY = False #不遵从robots协议 ITEM_PIPELINES = { 'BossPro.pipelines.BossproPipeline': 300, #开启item_pipelines }