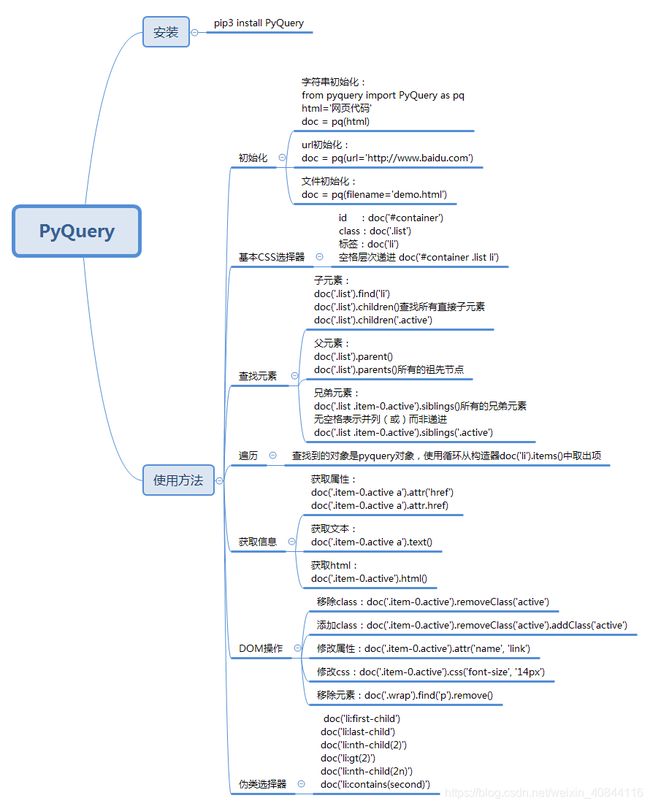
【Python 爬虫】Json、正则、BeautifulSoup、PyQuery解析数据
文章目录
- 一、json解析
- 二、正则表达式
- 三、Beautifulsoup
- 四、PyQuery
一、json解析
如果返回的对象是json格式数据,需要使用json解析,才能使用期类似字典格式的属性(例如切片索引等功能),否则不解析就是’str’类
- 直接调用方法
response.json() - 或者使用json模块
import json
json.load(respons.text)
#注:
#json.dumps()用于将字典形式的数据转化为字符串
#json.loads()用于将字符串形式的数据转化为字典
常用于调用网站API后返回的数据,可以参考文章
新榜 https://blog.csdn.net/weixin_40844116/article/details/103422041
友盟 https://blog.csdn.net/weixin_40844116/article/details/103405620
附注1:json.load()和json.loads()区别
json.load(fp, *, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)
Deserialize
fp(a.read()-supporting file-like object containing
a JSON document) to a Python object.
import json
dic = json.load(open('Data/jd.json', 'r'))
print(type(open('Data/jd.json', 'r')))
for shop in dic:
print(shop.get('shop_name'), shop.get('shop_brief'))
>>><class '_io.TextIOWrapper'>
>>>华为官方旗舰店 华为官方旗舰店
json.loads(s, *, encoding=None, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)
Deserialize
s(astr,bytesorbytearrayinstance
containing a JSON document) to a Python object.
import json
dic = json.loads(open('Data/jd.json', 'r').read())
print(type(open('Data/jd.json', 'r').read()))
for shop in dic:
print(shop.get('shop_name'), shop.get('shop_brief'))
>>><class '_io.TextIOWrapper'>
>>>华为官方旗舰店 华为官方旗舰店
附注2:pandas处理json数据
import pandas
df = pandas.read_json('Data/jd.json')
二、正则表达式
正则表达式参考 https://blog.csdn.net/weixin_40844116/article/details/84646619
将网页返回后,需要从纷杂的网页代码中提取所需的数据,正则表达式是将网页代码作为文本,通过正则规则提取数据。
案例
import re
html =
'''
'''
results = re.findall('(.*?)' , html, re.S)
print(results)
print(type(results))
for result in results:
print(result)
print(result[0], result[1], result[2])
三、Beautifulsoup
官方文档:
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.html
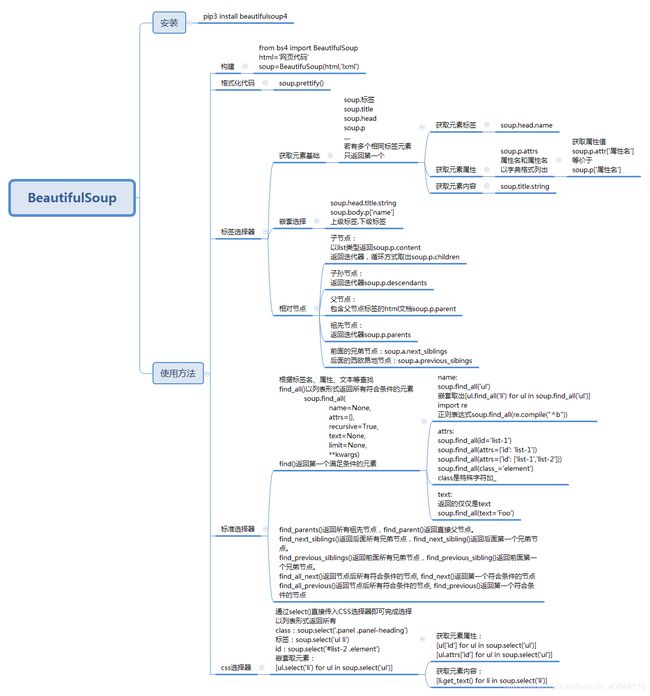
灵活方便的网页解析库,处理高效,支持多种解析器。
BeautifulSoup(markup='', features=None, builder=None, parse_only=None, from_encoding=None, exclude_encodings=None, **kwargs)
解析器
features:
Desirable features of the parser to be used.
This may be the name of a specific parser (“lxml”, “lxml-xml”,“html.parser”, or “html5lib”) or it may be the type of markup to be used (“html”, “html5”, “xml”).
It’s recommended that you name a specific parser, so that Beautiful Soup gives you the same results across platforms and virtual environments.
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup, “html.parser”) | Python的内置标准库、执行速度适中 、文档容错能力强 | Python 2.7.3 or 3.2.2)前的版本中文容错能力差 |
| lxml HTML 解析器 | BeautifulSoup(markup, “lxml”) | 速度快、文档容错能力强 | 需要安装C语言库 |
| lxml XML 解析器 | BeautifulSoup(markup, “xml”) | 速度快、唯一支持XML的解析器 | 需要安装C语言库 |
| html5lib | BeautifulSoup(markup, “html5lib”) | 最好的容错性、以浏览器的方式解析文档、生成HTML5格式的文档 | 速度慢、不依赖外部扩展 |
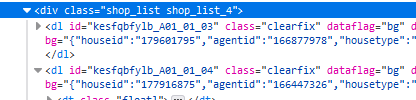
Case:爬取房天下列表房屋基本信息

- 定位条目
soup.select('.shop_list dl')
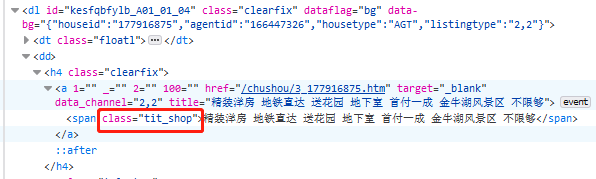
- 定位标题
title=house.select('.tit_shop')[0].text.strip()
- 定位房屋细节
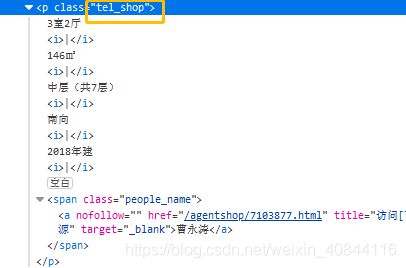
house_detail=house.select('.tel_shop')[0].text.strip().replace('|','').split()
- 定位地址信息
house.select('.add_shop')[0].text.split()

- 定位价格信息
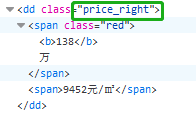
house.select('.price_right')[0].text.split()
import requests
domain='https://nanjing.esf.fang.com'
res = requests.get(domain)
from bs4 import BeautifulSoup
soup = BeautifulSoup(res.text, 'html.parser')
#soup.select('.shop_list dl')是一个列表,包含了一个个房屋信息条目
for house in soup.select('.shop_list dl'):
if len(house.select('.tit_shop'))>0:#有些条目其实是空的
#print(house)
#print(house.select('.tit_shop'))
title=house.select('.tit_shop')[0].text.strip()
print(title)#打印出标题
house_detail=house.select('.tel_shop')[0].text.strip().replace('|','').split()
print(house_detail) #打印房屋细节
address=house.select('.add_shop')[0].text.split()
print(address) #打印地址信息
price=house.select('.price_right')[0].text.split()
print(price) #打印价格信息
#打印房屋条目的详情页网址
print(domain+house.select('a')[0]['href']+'?channel='+house.select('a')[0]['data_channel'])
print("==============================")

结果只是打印,分项信息还在列表里,还需要再去整理成可直接使用的数据
四、PyQuery
官方文档:http://pyquery.readthedocs.io/
熟悉jQuery,使用该库比较方便。