Datawhale第二章二三节数据的重构
导入包
import numpy as np
import pandas as pd
2 第二章数据重构
2.4数据的合并
2.4.1任务一:将data文件夹的所有数据都载入
text_left_up=pd.read_csv('datalab/74975/train-left-up.csv')
text_left_down=pd.read_csv('datalab/74975/train-left-down.csv')
text_right_up=pd.read_csv('datalab/74975/train-right-up.csv')
text_right_down=pd.read_csv('datalab/74975/train-right-down.csv')
2.4.2任务二三:使用concat方法连接
将数据train-left-up.csv和train-right-up.csv横向合并成一张表,并保存为表名result_up,将数据train-left-down.csv和train-right-down.csv横向合并成一张表,并保存为表名result_down。将result_up和result_down纵向合并成result。
result_up=pd.concat([text_left_up,text_right_up],axis=1)
result_down=pd.concat([text_left_down,text_right_down],axis=1)
result=pd.concat([result_up,result_down])
result.head()
2.4.4任务四:使用DataFrame自带的join和append方法连接
result_up=text_left_up.join(text_right_up)
result_down=text_left_down.join(text_right_down)
result=result_up.append(result_down)
result.head()
2.4.5任务五:使用pandas自带的merge和dataframe的append方法连接
result_up=pd.merge(text_left_up,text_right_up,left_index=True,right_index=True)
result_down=pd.merge(text_left_down,text_right_down,left_index=True,right_index=True)
result=result_up.append(result_down)
result.head()
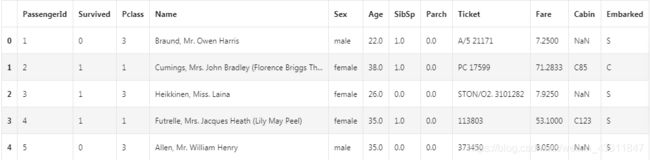
2.4.6任务六:完成数据保存为result.csv
result.to_csv('result.csv')
2.5 换一种角度看数据
2.5.1任务一:将我们的数据变成series类型的数据
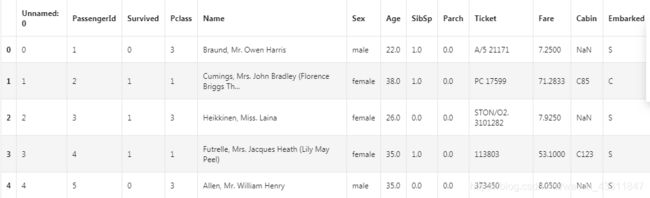
text=pd.read_csv('result.csv')
text.head()
unit_result=text.stack().head(20)
unit_result.head()
运行结果
0 Unnamed: 0 0
PassengerId 1
Survived 0
Pclass 3
Name Braund, Mr. Owen Harris
Sex male
Age 22
SibSp 1
Parch 0
Ticket A/5 21171
Fare 7.25
Embarked S
1 Unnamed: 0 1
PassengerId 2
Survived 1
Pclass 1
Name Cumings, Mrs. John Bradley (Florence Briggs Th...
Sex female
Age 38
SibSp 1
dtype: object
stack()的连接方式:
>>> a = np.array([1, 2, 3])
>>> b = np.array([2, 3, 4])
>>> np.stack((a, b)) #默认axis=0
array([[1, 2, 3],
[2, 3, 4]])
#第一维度增加,也就是1*3变为了2*1*3
>>> np.stack((a, b), axis=-1)
array([[1, 2],
[2, 3],
[3, 4]])
# 根据前面介绍的,axis=-1也就是在最后一维后增加一维,原始为1*3,堆叠后的维度就是1*3*2,由于这里的a和b都只是一维数组,所以axis=1和axis=-1是相同的效果
a = np.array([[1, 2, 3],[2,3,4]])
b = np.array([[2, 3, 4],[4,5,6]])
np.stack((a, b))
array([[[1, 2, 3],
[2, 3, 4]],
[[2, 3, 4],
[4, 5, 6]]])
np.stack((a, b), axis=1)
array([[[1, 2, 3],
[2, 3, 4]],
[[2, 3, 4],
[4, 5, 6]]])
np.stack((a, b), axis=2)
array([[[1, 2],
[2, 3],
[3, 4]],
[[2, 4],
[3, 5],
[4, 6]]])
import numpy as np
import pandas as pd
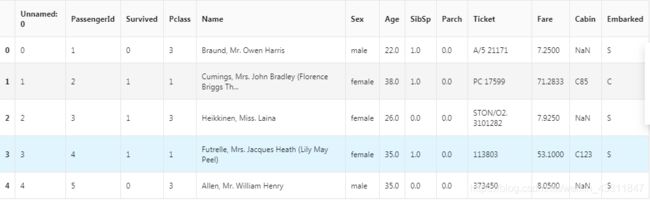
text=pd.read_csv('datalab/74955/result.csv')
text.head()
第一部分:数据聚合与运算
2.4数据运用
2.4.2任务二:计算泰坦尼克号男性和女性平均票价
df=text['Fare'].groupby(text['Sex'])
means=df.mean()
means
运行结果
Sex
female 44.479818
male 25.523893
Name: Fare, dtype: float64
2.4.3任务三:统计泰坦尼克号中男女的存活人数
survived_sex=text['Survived'].groupby(text['Sex']).sum()
survived_sex.head()
运行结果
Sex
female 233
male 109
Name: Survived, dtype: int64
2.4.3任务四:计算客舱不同等级的存活人数
survived_pclass=text['Survived'].groupby(text['Pclass']).sum()
survived_pclass.head()
Pclass
1 136
2 87
3 119
Name: Survived, dtype: int64
2.4.5任务五:统计在不同等级的票中的不同年龄的船票花费的平均值
text.groupby(['Pclass','Age'])['Fare'].mean().head()
2.4.6任务六:将任务二三的数据合并,保存在sex_fare_survived.csv
2.4.7任务七:得出不同年龄总的存活人数,找出存活人数最高的年龄,最后计算存活人数最高的存活率
survived_age=text['Survived'].groupby(text['Age']).sum()
survived_age.head(20)
运行结果
Age
0.42 1
0.67 1
0.75 2
0.83 2
0.92 1
1.00 5
2.00 3
3.00 5
4.00 7
5.00 4
6.00 2
7.00 1
8.00 2
9.00 2
10.00 0
11.00 1
12.00 1
13.00 2
14.00 3
14.50 0
Name: Survived, dtype: int64
survived_age[survived_age.values==survived_age.max()]
运行结果
Age
24.0 15
Name: Survived, dtype: int64
最大存活率:
1
_sum=text['Survived'].sum()
_sum=text['Survived'].sum()
print("sum of person:"+str(_sum))
percent=survived_age.max()/_sum
print("最大存活率:"+str(percent))
运行结果
sum of person:342
最大存活率:0.0438596491228