阿里天池新人赛——二手车交易价格预测(赛题理解)
概览
赛题以二手车市场为背景,这个数据包含了有关二手车的相关的车况、配置参数等features,标签label值是price,建立模型利用这些数据进行学习,预测二手汽车的交易价格,这是一个典型的回归问题。使用集成学习算法Xgboost、LightGBM构建一个baseline。
预测指标
此次赛题的评价指标为MAE(Mean Absolute Error):
M A E = ∑ i = 1 n ∣ y i − y i ^ ∣ n MAE=\frac {\sum_{i=1}^{n} {|y_i-\hat{y_i}|} } {n} MAE=n∑i=1n∣yi−yi^∣
其中 y i y_i yi代表第 i i i个样本的真实值,其中 y i ^ \hat{y_i} yi^代表第 i i i个样本的预测值。
回归任务的性能指标详见
机器学习中性能度量——sklearn.metrics
数据概况
import pandas as pd
import numpy as np
#载入训练集和测试集;
Train_data = pd.read_csv(r'.\used_car_train_20200313/used_car_train_20200313.csv', sep=' ')
Test_data = pd.read_csv(r'.\used_car_testA_20200313/used_car_testA_20200313.csv', sep=' ')
print('Train data shape:',Train_data.shape)
print('TestA data shape:',Test_data.shape)
#Train data shape: (150000, 31)
#TestA data shape: (50000, 30)
- name - 汽车编码
- regDate - 汽车注册时间
- model - 车型编码
- brand - 品牌
- bodyType - 车身类型
- fuelType - 燃油类型
- gearbox - 变速箱
- power - 汽车功率
- kilometer - 汽车行驶公里
- notRepairedDamage - 汽车有尚未修复的损坏
- regionCode - 看车地区编码
- seller - 销售方
- offerType - 报价类型
- creatDate - 广告发布时间
- price - 汽车价格 v_0’, ‘v_1’, ‘v_2’, ‘v_3’, ‘v_4’, ‘v_5’, ‘v_6’, ‘v_7’, ‘v_8’, ‘v_9’, ‘v_10’, ‘v_11’, ‘v_12’, ‘v_13’,‘v_14’(根据汽车的评 论、标签等大量信息得到的embedding向量)【人工构造 匿名特征】
快速查看数据结构
使用DataFrame()的head()、info()、describe()
Train_data.head()#查看数据的前五行
Train_data.info()#查看数据的基本统计信息
Train_data.describe()#describe()方法查看数值属性的概括
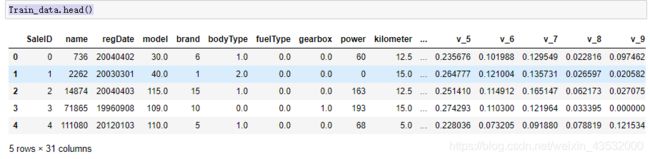
查看数据的前五行
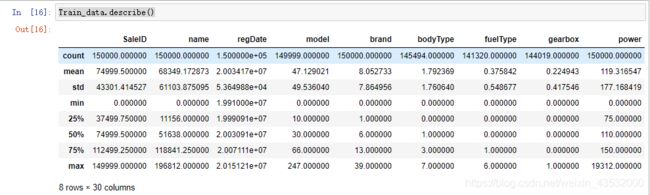
describe()只统计数值型,从下图可以看相关的统计量,count,mean,std
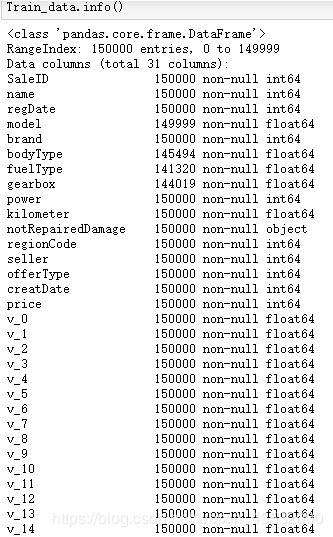
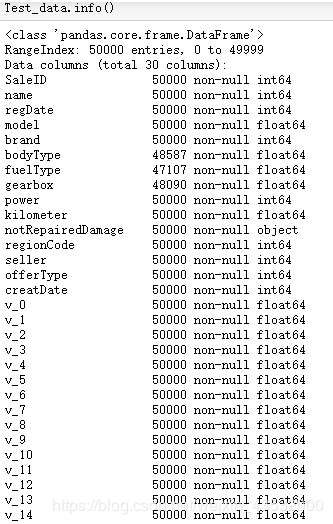
train和test数据集中有存在缺失值,对于model中用众数进行填充
由于数据进行了脱敏处理,feature都是数值数据,仅有notRepairedDamage 为object类型
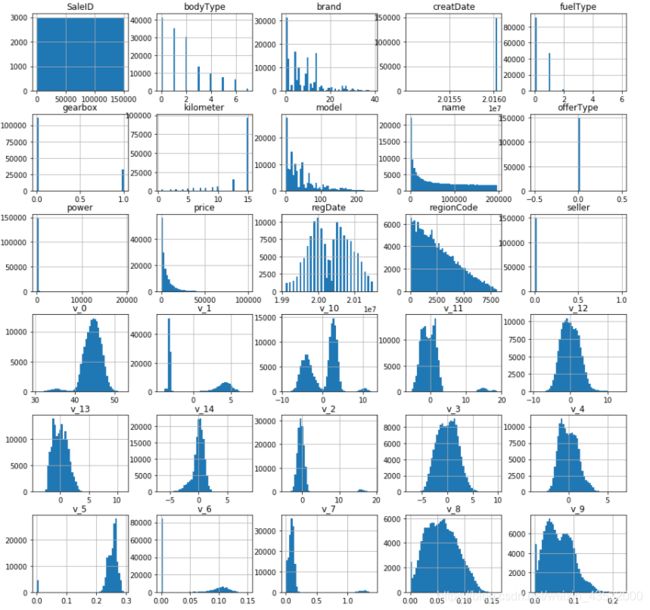
另一种快速了解数据类型的方法是画出每个数值属性的柱状图:
import matplotlib.pyplot as plt
Train_data.hist(bins=50,igsize=(15,15))
准备数据
这是个简单的赛题理解,我们做一个简单Baseline,就不对数据进行数据探索分析。
由于模型输入的数据只能是数值型的数据,我们暂时丢弃非数值型的features。"notReapairedDameage"为object类型
Y_data=Train_data['price']
X_data=Train_data.drop(['price','notRepairedDamage'],axis=1)
X_Test=Test_data.drop('notRepairedDamage',axis=1)
因为数据存在缺失值,我们暂且直接简单用平均值进行填充
for column in list(X_data.columns[X_data.isnull().sum() > 0]):
mean_val = X_data[column].mean()
X_data[column].fillna(mean_val, inplace=True)
模型训练与预测
在数据比赛Kaggle,天池中最常见的就是XGBoost和LightGBM。这两个算法已经成为许多数据科学家的终极武器,这是一个足够强大的可以应对各种不寻常数据的高大上的算法。
使用建立xgboost进行5折交叉验证查看模型的参数效果
import xgboost as xgb
from sklearn.model_selection import StratifiedKFold
from sklearn.metrics import mean_squared_error, mean_absolute_error
## xgb-Model
xgr = xgb.XGBRegressor(n_estimators=120, learning_rate=0.1, gamma=0, subsample=0.8,colsample_bytree=0.9, max_depth=7) #,objective ='reg:squarederror'
scores_train = []
scores = []
## 5折交叉验证方式
sk=StratifiedKFold(n_splits=5,shuffle=True,random_state=0)
for train_ind,val_ind in sk.split(X_data,Y_data):
train_x=X_data.iloc[train_ind].values
train_y=Y_data.iloc[train_ind]
val_x=X_data.iloc[val_ind].values
val_y=Y_data.iloc[val_ind]
xgr.fit(train_x,train_y)
pred_train_xgb=xgr.predict(train_x)
pred_xgb=xgr.predict(val_x)
score_train = mean_absolute_error(train_y,pred_train_xgb)
scores_train.append(score_train)
score = mean_absolute_error(val_y,pred_xgb)
scores.append(score)
print('Train mae:',np.mean(score_train))
print('Val mae',np.mean(scores))
#Train mae: 536.5672303578158
#Val mae 634.2082997218529
定义xgb和lgb模型函数
import lightgbm as lgb
from sklearn.model_selection import GridSearchCV
def build_model_xgb(x_train,y_train):
model = xgb.XGBRegressor(n_estimators=150, learning_rate=0.1, gamma=0, subsample=0.8,
colsample_bytree=0.9, max_depth=7) #, objective ='reg:squarederror'
model.fit(x_train, y_train)
return model
def build_model_lgb(x_train,y_train):
estimator = lgb.LGBMRegressor(num_leaves=127,n_estimators = 150)
param_grid = {
'learning_rate': [0.01, 0.05, 0.1, 0.2],
}
gbm = GridSearchCV(estimator, param_grid)
gbm.fit(x_train, y_train)
return gbm
切分数据集(Train,Val)
## Split data with val
x_train,x_val,y_train,y_val = train_test_split(X_data,Y_data,test_size=0.3)
进行模型训练,评价和预测
print('Train lgb...')
model_lgb = build_model_lgb(x_train,y_train)
val_lgb = model_lgb.predict(x_val)
MAE_lgb = mean_absolute_error(y_val,val_lgb)
print('MAE of val with lgb:',MAE_lgb)
## Train lgb...
## MAE of val with lgb: 599.5780989136218
print('Predict lgb...')
model_lgb_pre = build_model_lgb(X_data,Y_data)
subA_lgb = model_lgb_pre.predict(X_test)
print('Train xgb...')
model_xgb = build_model_xgb(x_train,y_train)
val_xgb = model_xgb.predict(x_val)
MAE_xgb = mean_absolute_error(y_val,val_xgb)
print('MAE of val with xgb:',MAE_xgb)
#Train xgb...
#MAE of val with xgb: 621.734760148006
print('Predict xgb...')
model_xgb_pre = build_model_xgb(X_data,Y_data)
subA_xgb = model_xgb_pre.predict(X_test)
进行模型融合并输出结果保存到csv文件
## 这里我们采取了简单的加权融合的方式
val_Weighted = (1-MAE_lgb/(MAE_xgb+MAE_lgb))*val_lgb+(1-MAE_xgb/(MAE_xgb+MAE_lgb))*val_xgb
val_Weighted[val_Weighted<0]=10 # 由于我们发现预测的最小值有负数,而真实情况下,price为负是不存在的,由此我们进行对应的后修正
print('MAE of val with Weighted ensemble:',mean_absolute_error(y_val,val_Weighted))
### MAE of val with Weighted ensemble: 591.2915509942275
sub_Weighted = (1-MAE_lgb/(MAE_xgb+MAE_lgb))*subA_lgb+(1-MAE_xgb/(MAE_xgb+MAE_lgb))*subA_xgb
sub = pd.DataFrame()
sub['SaleID'] = X_test.index
sub['price'] = sub_Weighted
sub.to_csv('./sub_Weighted.csv',index=False)
sub.head()
