数据分析之Kaggle Titanic竞赛——第二章:数据清洗及特征处理、数据重构、可视化
动手学数据分析——第二章:数据清洗及特征处理、数据重构、可视化
- 0. 前言
- 1. 数据清洗及特征处理
- 1.1 缺失值观察与处理
- 1.1.1 缺失值观察
- 1.1.2 缺失值处理
- (1)处理缺失值的思路:
- (2)对Age列的数据的缺失值进行处理:
- (3)dropna函数与fillna函数:
- 1.2 重复值观察与处理
- 1.2.1 重复值观察
- 1.2.2 重复值处理
- 1.2.3 保存清洗之后的数据
- 1.3 特征观察与处理
- 1.3.1 对年龄进行分箱(离散化)处理
- 1.3.2 对文本变量进行转换
- (1)查看文本变量名及种类
- (2)将文本变量Sex, Cabin ,Embarked用数值变量12345表示
- (3)将文本变量Sex, Cabin, Embarked用one-hot编码表示
- 1.3.3 从纯文本Name特征里提取出Titles的特征(所谓的Titles就是Mr,Miss,Mrs等)¶
- 2. 数据重构
- 2.1 数据的合并
- 2.1.1 concat函数
- 2.1.2 join方法和append(DataFrame自带)
- 2.1.3 merge方法(Panads)和append方法(DataFrame自带)
- 2.2 换一种角度看数据
- 2.2.1 将我们的数据变为Series类型的数据
- 2.3 数据运用(数据聚合与运算)
- 3. 数据可视化
- 3.0 导入库:
- 3.1 了解matplotlib
- 3.2 可视化展示泰坦尼克号数据集中男女中生存人数分布情况(用柱状图)
- 3.3 可视化展示泰坦尼克号数据集中男女中生存人与死亡人数的比例图(用柱状图试试)
- 3.4 可视化展示泰坦尼克号数据集中不同票价的人生存和死亡人数分布情况。(用折线图试试)(横轴是不同票价,纵轴是存活人数)
- 3.5 可视化展示泰坦尼克号数据集中不同仓位等级的人生存和死亡人员的分布情况。(用柱状图试试)
- 3.6 可视化展示泰坦尼克号数据集中不同年龄的人生存与死亡人数分布情况。(不限表达方式)
- 3.7 可视化展示泰坦尼克号数据集中不同仓位等级的人年龄分布情况。(用折线图试试)
- 4. 总结
0. 前言
前面一章的内容大家可以感觉到我们主要是对基础知识做一个梳理,让大家了解数据分析的一些操作,主要做了数据的各个角度的观察。那么在这里,我们主要是做数据分析的流程性学习,主要是包括了数据清洗以及数据的特征处理,数据重构以及数据可视化。这些内容是为数据分析最后的建模和模型评价做一个铺垫。
1. 数据清洗及特征处理
我们拿到的数据通常是不干净的,所谓的不干净,就是数据中有缺失值,有一些异常点等,需要经过一定的处理才能继续做后面的分析或建模,所以拿到数据的第一步是进行数据清洗,本章我们将学习缺失值、重复值、字符串和数据转换等操作,将数据清洗成可以分析或建模的样子。
1.1 缺失值观察与处理
1.1.1 缺失值观察
#方法一:
df.info()
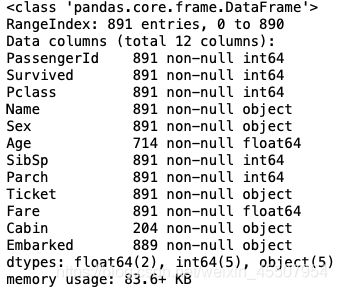
#方法二:
df.isnull().sum()
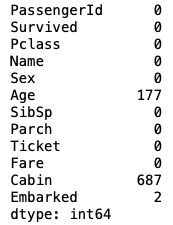
1.1.2 缺失值处理
(1)处理缺失值的思路:
- 0
- 平均值
- 众数
(2)对Age列的数据的缺失值进行处理:
# 方法一:
df[df['Age']==None]=0
# 方法二:
df[df['Age'].isnull()] = 0
# 方法三:
df[df['Age'] == np.nan] = 0
【思考】检索空缺值用np.nan要比用None好,这是为什么?
【回答】数值列读取数据后,空缺值的数据类型为float64所以用None一般索引不到,比较的时候最好用np.nan
(3)dropna函数与fillna函数:
df.dropna().head(3)
df.fillna(0).head(3)
【思考】dropna和fillna有哪些参数,分别如何使用呢?
【参考】https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.dropna.html
【参考】https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.fillna.html
1.2 重复值观察与处理
1.2.1 重复值观察
df[df.duplicated()]
1.2.2 重复值处理
df.drop_duplicates().head()
1.2.3 保存清洗之后的数据
df.to_csv('test_clear.csv')
1.3 特征观察与处理
我们对特征进行一下观察,可以把特征大概分为两大类:
数值型特征:Survived ,Pclass, Age ,SibSp, Parch, Fare,其中Survived, Pclass为离散型数值特征,Age,SibSp, Parch, Fare为连续型数值特征
文本型特征:Name, Sex, Cabin,Embarked, Ticket,其中Sex, Cabin, Embarked, Ticket为类别型文本特征。
数值型特征一般可以直接用于模型的训练,但有时候为了模型的稳定性及鲁棒性会对连续变量进行离散化。文本型特征往往需要转换成数值型特征才能用于建模分析。
1.3.1 对年龄进行分箱(离散化)处理
分箱操作:在建模中,需要对连续变量离散化,特征离散化后,模型会更稳定,降低了模型过拟合的风险。
无监督分箱法:等距划分、等频划分
- 将连续变量Age平均分箱成5个年龄段,并分别用类别变量12345表示
df['AgeBand'] = pd.cut(df['Age'], 5,labels = ['1','2','3','4','5'])
df.to_csv('test_ave.csv')
- 将连续变量Age划分为[0,5) [5,15) [15,30) [30,50) [50,80)五个年龄段,并分别用类别变量12345表示
df['AgeBand'] = pd.cut(df['Age'],[0,5,15,30,50,80],labels = ['1','2','3','4','5'])
df.to_csv('test_cut.csv')
- 将连续变量Age按10% 30% 50 70% 90%五个年龄段,并用分类变量12345表示
df['AgeBand'] = pd.qcut(df['Age'],[0,0.1,0.3,0.5,0.7,0.9],labels = ['1','2','3','4','5'])
df.to_csv('test_pr.csv')
【参考】https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.cut.html
【参考】https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.qcut.html
1.3.2 对文本变量进行转换
(1)查看文本变量名及种类
#方法一: value_counts
df['Sex'].value_counts()

#方法二: unique
df['Sex'].unique()
![]()
(2)将文本变量Sex, Cabin ,Embarked用数值变量12345表示
#方法一: replace
df['Sex_num'] = df['Sex'].replace(['male','female'],[1,2])
#方法二: map
df['Sex_num'] = df['Sex'].map({'male': 1, 'female': 2})
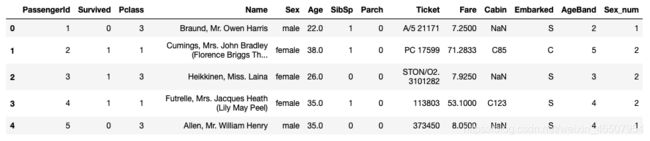
#方法三: 使用sklearn.preprocessing的LabelEncoder
from sklearn.preprocessing import LabelEncoder
for feat in ['Cabin', 'Ticket']:
lbl = LabelEncoder()
label_dict = dict(zip(df[feat].unique(), range(df[feat].nunique())))
df[feat + "_labelEncode"] = df[feat].map(label_dict)
df[feat + "_labelEncode"] = lbl.fit_transform(df[feat].astype(str))
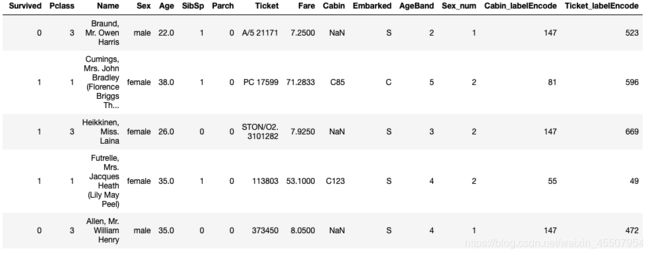
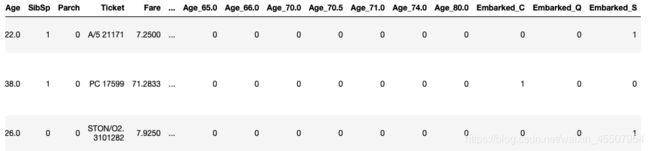
(3)将文本变量Sex, Cabin, Embarked用one-hot编码表示
#方法一: OneHotEncoder
for feat in ["Age", "Embarked"]:
# x = pd.get_dummies(df["Age"] // 6)
# x = pd.get_dummies(pd.cut(df['Age'],5))
x = pd.get_dummies(df[feat], prefix=feat)
df = pd.concat([df, x], axis=1)
#df[feat] = pd.get_dummies(df[feat], prefix=feat)
1.3.3 从纯文本Name特征里提取出Titles的特征(所谓的Titles就是Mr,Miss,Mrs等)¶
df['Title'] = df.Name.str.extract('([A-Za-z]+)\.', expand=False)
df.to_csv('test_fin.csv')
2. 数据重构
在前面我们已经学习了Pandas基础,第二章我们开始进入数据分析的业务部分,在第二章第一节的内容中,我们学习了数据的清洗,这一部分十分重要,只有数据变得相对干净,我们之后对数据的分析才可以更有力。而这一节,我们要做的是数据重构,数据重构依旧属于数据理解(准备)的范围。
2.1 数据的合并
2.1.1 concat函数
- 横向合并:
list_up = [text_left_up,text_right_up]
result_up = pd.concat(list_up,axis=1)
list_down=[text_left_down,text_right_down]
result_down = pd.concat(list_down,axis=1)
- 纵向合并:
result = pd.concat([result_up,result_down])
2.1.2 join方法和append(DataFrame自带)
resul_up = text_left_up.join(text_right_up)
result_down = text_left_down.join(text_right_down)
result = result_up.append(result_down)
2.1.3 merge方法(Panads)和append方法(DataFrame自带)
result_up = pd.merge(text_left_up,text_right_up,left_index=True,right_index=True)
result_down = pd.merge(text_left_down,text_right_down,left_index=True,right_index=True)
result = resul_up.append(result_down)
【思考】对比merge、join以及concat的方法的不同以及相同:merge、join只能横向,concat可以横向也可以纵向
2.2 换一种角度看数据
2.2.1 将我们的数据变为Series类型的数据
- stack函数:
# 将完整的数据加载出来
text = pd.read_csv('result.csv')
text.head()
# 代码写在这里
unit_result=text.stack().head(20)
unit_result.head()
#将代码保存为unit_result,csv
unit_result.to_csv('unit_result.csv')
test = pd.read_csv('unit_result.csv')
test.head()
2.3 数据运用(数据聚合与运算)
通过《Python for Data Analysis》P303、Google or Baidu来学习了解GroupBy机制
- 计算泰坦尼克号男性与女性的平均票价:
avg_fare = df['Fare'].groupby(df['Sex'])
avg_fare.mean()

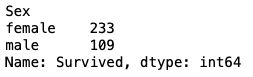
- 统计泰坦尼克号中男女的存活人数:
survived_sex = df['Survived'].groupby(df['Sex']).sum()
- 计算客舱不同等级的存活人数:
survived_pclass = df['Survived'].groupby(df['Pclass'])
survived_pclass.sum()

- 通过agg()函数来同时计算,同时用rename()函数修改列名:
df.groupby('Survived').agg({'Sex': 'mean', 'Pclass': 'count'}).rename(columns={'Sex': 'mean_sex', 'Pclass': 'count_pclass'})
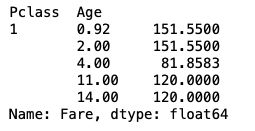
- 统计在不同等级的票中的不同年龄的船票花费的平均:
df.groupby(['Pclass','Age'])['Fare'].mean().head()
- 将1和2的数据合并后保存:
result = pd.merge(means,survived_sex,on='Sex')
result.to_csv('sex_fare_survived.csv')
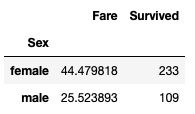
- 得出不同年龄的总的存活人数,然后找出存活人数的最高的年龄,最后计算存活人数最高的存活率(存活人数/总人数):
#不同年龄的存活人数
survived_age = df['Survived'].groupby(df['Age']).sum()

#找出最大值的年龄段
survived_age[survived_age.values==survived_age.max()]

#计算总人数
_sum = text['Survived'].sum()
print("sum of person:"+str(_sum))
# 存活率
precetn =survived_age.max()/_sum
print("最大存活率:"+str(precetn))
sum of person:342
最大存活率:0.043859649122807015
3. 数据可视化
数据可视化,主要给大家介绍一下Python数据可视化库Matplotlib,在本章学习中,你也许会觉得数据很有趣。在打比赛的过程中,数据可视化可以让我们更好的看到每一个关键步骤的结果如何,可以用来优化方案,是一个很有用的技巧。
配合食用:如何让人一眼看懂你的数据?
《Python for Data Analysis》第九章
【思考】最基本的可视化图案有哪些?分别适用于那些场景?
- 折线图:适合可视化某个属性值随时间变化的走势
- 柱状图:适合数值大小的比较
- 散点图:适合分散的数值,看数值集中的位置
- 箱线图:适合较为集中的数据展示
- 热力图:适合相关系数的展示
- ……
3.0 导入库:
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
text = pd.read_csv(r'result.csv')
text.head()
3.1 了解matplotlib
跟着书本第九章,了解matplotlib,自己创建一个数据项,对其进行基本可视化
3.2 可视化展示泰坦尼克号数据集中男女中生存人数分布情况(用柱状图)
sex = text.groupby('Sex')['Survived'].sum()
sex.plot.bar()
plt.title('survived_count')
plt.show()
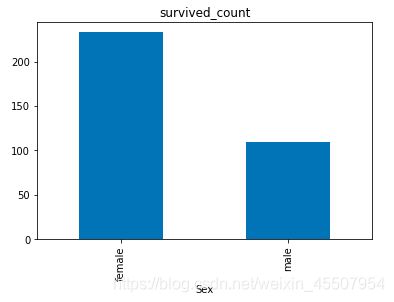
【思考】计算出泰坦尼克号数据集中男女中死亡人数,并可视化展示?如何和男女生存人数可视化柱状图结合到一起?看到你的数据可视化,说说你的第一感受(比如:你一眼看出男生存活人数更多,那么性别可能会影响存活率)。
3.3 可视化展示泰坦尼克号数据集中男女中生存人与死亡人数的比例图(用柱状图试试)
【提示】男女这两个数据轴,存活和死亡人数按比例用柱状图表示
# 提示:计算男女中死亡人数 1表示生存,0表示死亡
text.groupby(['Sex','Survived'])['Survived'].count().unstack().plot(kind='bar',stacked='True')
plt.title('survived_count')
plt.ylabel('count')
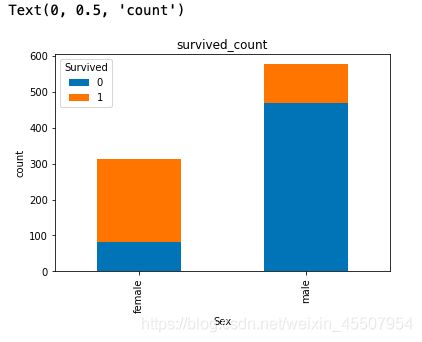
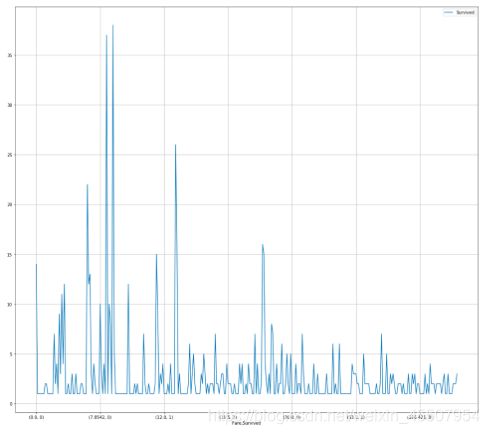
3.4 可视化展示泰坦尼克号数据集中不同票价的人生存和死亡人数分布情况。(用折线图试试)(横轴是不同票价,纵轴是存活人数)
【提示】对于这种统计性质的且用折线表示的数据,你可以考虑将数据排序或者不排序来分别表示。看看你能发现什么?
# 计算不同票价中生存与死亡人数 1表示生存,0表示死亡
# 排序后绘折线图
fare_sur = text.groupby(['Fare'])['Survived'].value_counts().sort_values(ascending=False)
fare_sur

# 绘图
fig = plt.figure(figsize=(20, 18))
fare_sur.plot(grid=True)
plt.legend()
plt.show()
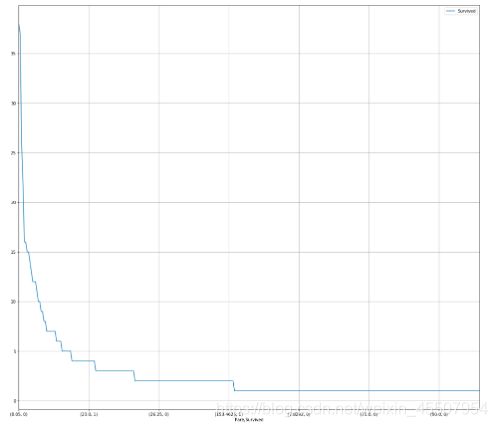
# 排序前绘折线图
fare_sur1 = text.groupby(['Fare'])['Survived'].value_counts()
fare_sur1

# 绘图
fig = plt.figure(figsize=(20, 18))
fare_sur1.plot(grid=True)
plt.legend()
plt.show()
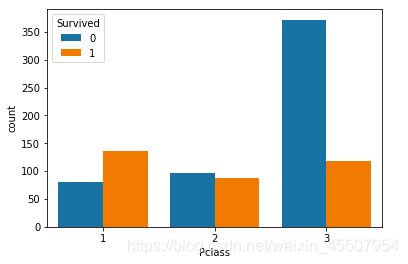
3.5 可视化展示泰坦尼克号数据集中不同仓位等级的人生存和死亡人员的分布情况。(用柱状图试试)
# 1表示生存,0表示死亡
pclass_sur = text.groupby(['Pclass'])['Survived'].value_counts()
pclass_sur

import seaborn as sns
sns.countplot(x="Pclass", hue="Survived", data=text)
【思考】看到这个前面几个数据可视化,说说你的第一感受和你的总结
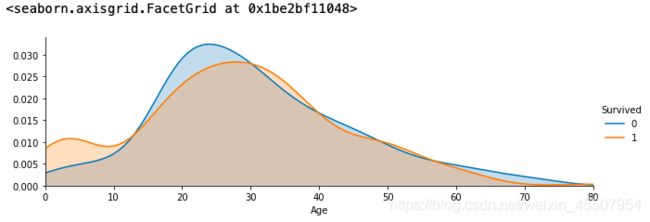
3.6 可视化展示泰坦尼克号数据集中不同年龄的人生存与死亡人数分布情况。(不限表达方式)
facet = sns.FacetGrid(text, hue="Survived",aspect=3)
facet.map(sns.kdeplot,'Age',shade= True)
facet.set(xlim=(0, text['Age'].max()))
facet.add_legend()
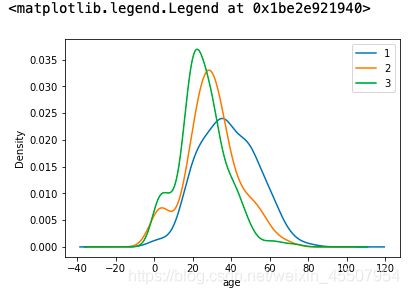
3.7 可视化展示泰坦尼克号数据集中不同仓位等级的人年龄分布情况。(用折线图试试)
text.Age[text.Pclass == 1].plot(kind='kde')
text.Age[text.Pclass == 2].plot(kind='kde')
text.Age[text.Pclass == 3].plot(kind='kde')
plt.xlabel("age")
plt.legend((1,2,3),loc="best")
【思考】上面所有可视化的例子做一个总体的分析,你看看你能不能有自己发现
4. 总结
到这里,我们的可视化就告一段落啦,如果你对数据可视化极其感兴趣,你还可以了解一下其他可视化模块,如:pyecharts,bokeh等。
如果你在工作中使用数据可视化,你必须知道数据可视化最大的作用不是炫酷,而是最快最直观的理解数据要表达什么,你觉得呢?