cs224n学习笔记 01: Introduction and word vectors
本节首先介绍NLP的一些一本概念;然后讨论如何用向量(numeric vector)来表示一个一个的单词(word);最后,我们对时下比较流行生成word vector方法进行探讨。
1 词向量
英语中近130万的单词,并且这些单词之间也存在一定的联系,比如:cat-feline,hotel-motel。很多研究表明,可以只要使用N维的向量空间,其中万,就足以对一种语言的全部语义进行表达。例如,语义空间可以表示出时态(过去时、现在时、奇偶、性别等信息。
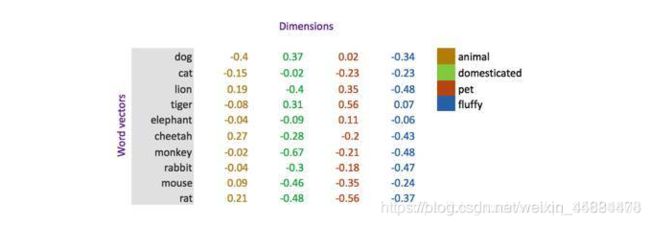
在这个图片中,我们假象每个维度都代表了一个清晰定义的意思。例如,你可以想象第一个维度代表animal,每个词汇在这个维度的权重代表了与这个意思或概念的相近度。
常用的生成word vectors方法可以分为以下几类:
one-hot vector
SVD-based methods
Iterations-based methods - word2vec
接下来,我们会对这些种类的方法进行详细介绍。注意,word vectors也可以写成word embeddings.
2 one-hot 编码
one-hot vector方法是最简单和直接的一种。设语料库包括\left | V \right |个不同的单词,对单词进行排序,用R^{\left | V \right | \times 1}维的向量来表示每一个单词,向量只由0和1组成,其中该单词的对应的位置的值为1。具体例子如下: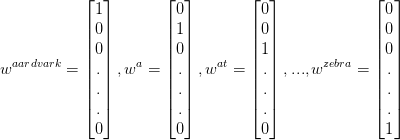
可以看出,one-hot vector方法生成的word vectors,单词与单词之间是完全独立的。
优点:解决了分类器不好处理离散数据的问题;在一定程度上也起到了扩充特征的作用。
缺点:在文本特征表示上有些缺点就非常突出。首先,它是一个词袋模型,不考虑词与词之间的顺序(文本中词的顺序信息也是很重要的);其次,它假设词与词相互独立(在大多数情况下,词与词是相互影响的);
![]()
最后,它得到的特征是离散稀疏的。因此,我们可以尝试降低向量空间R\left | V \right |的维度,寻找其他子空间对词与词之间的联系进行编码。
3 word2vec
ord2vec模型是简单化的神经网络。既然是神经网络,就有对应的输入层,隐层与输出层。输入就是上边提到的One-Hot Vector,隐层没有激活函数,只是线性的单元。输出层维度跟输入层一样,用的是Softmax回归。
word2vec主要包含两个模型:CBOW和skip-gram,以及两种高效训练的方法:负采样(negative sampling)和层序softmax(hierarchical softmax)。
CBOW模型的训练输入是某一个特征词的上下文相关的词对应的词向量,而输出就是这特定的一个词的词向量。Skip-Gram模型和CBOW的思路是反着来的,即输入是特定的一个词的词向量,而输出是特定词对应的上下文词向量。CBOW对小型数据库比较合适,而Skip-Gram在大型语料中表现更好。
3.1 CBOW模型
BOW是一种基于迭代的、学习word vectors的方法。
它的思想是:给定一个中心词的上下文单词,预测这个中心词是是什么。例如:{“the”,“cat”,"?", “over”,“the”,“puuddle”},预测“?”是哪个词。
因此,CBOW训练数据由(中心词对应的context,中心词)组成,其中中心词就是数据的label。
接下来我们开始介绍CBOW的具体实现:
首先,我们给出一些已知参数的定义:
设数据集共包括个不同的单词
首先为数据集生成one-hot编码的word vectors,然后用词向量的组合来表示数据集中的每一个句子
:代表句子中第c个单词对应的one-hot word vector,;
:表示模型对该组输入数据做出的中心词的预测结果,;
:代表该组数据的label,就是这个真实中心词对应的one-hot word vector,。
接下来,给出需要学些的未知参数的定义。
假设我们希望用维的向量来表示每个单词,就是词向量空间的大小为
CBOW需要为每个单词学习两个向量,分别为:
w: input vector,用来表示该单词作为context word输入时的向量表示
w’: output vector,用来表示该单词作为center word输出时的向量表示
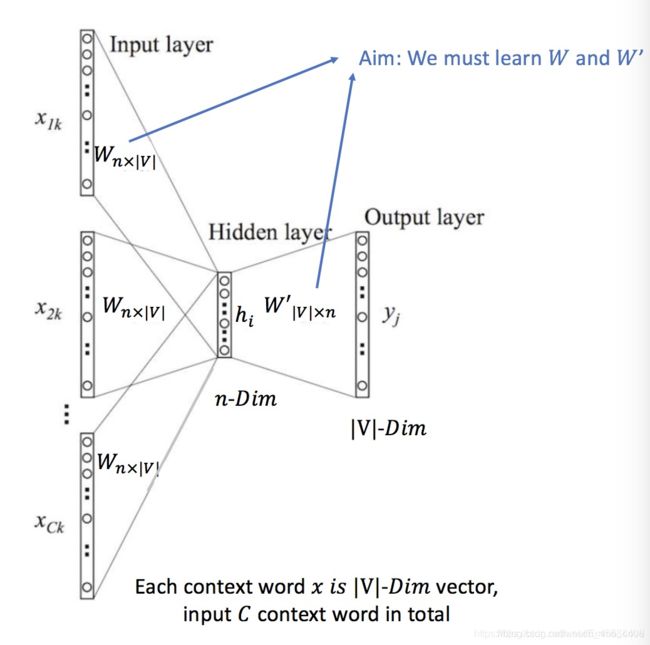
接下来,我们给出CBOW模型的损失函数。对于给定的一组数据,使用cross entropy来度量输出的y与真实的label \hat{y}之间的差别:
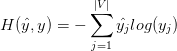
由于真实label\hat{y}是一个one-hot vector,只有center word对于的位置才是1,其它位置均为0。因此设第i个单词为真正的中心词,则可以将上面的损失函数可以化简为:
![]()
因此,CBOW的目标函数应该为:
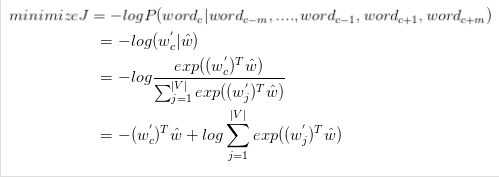
3.2 Skim-gram模型
kip-gram是给定input word来预测上下文。所谓一个单词的上下文是指在其窗口中出现的词(一般情况窗口的size选5左右,即这个中心词的前5个词和后5个词,上下文词一共是10个词)。
给出训练词w1,w2,w3,…,wt ,Skip-gram模型的目标是最大化对数日志概率:

其中c是训练上下文(可以是中心单词wt的一个函数)的大小。较大的c意味着更多的训练例,因此可以导致更高的准确性,同时也意味着更多的训练时间。
如何求这个P(wt+j | wt;θ)?基本Skip-gram公式使用softmax函数:
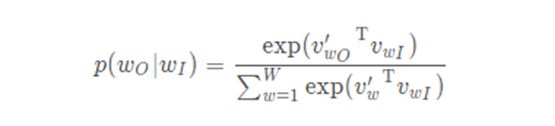
其中Vw和V′w分别为w的输入和输出向量表示,W为词汇表中的单词数。
4 梯度优化
我们的损失函数 J ( θ ) J(\theta) J(θ) 需要最小化
使用的方法为:梯度下降
对于当前 θ \theta θ ,计算 J ( θ ) J(\theta) J(θ) 的梯度
然后小步重复朝着负梯度方向更新方程里的参数 α = ( s t e p s i z e ) o r ( l e a r n i n g r a t e ) \alpha=(step\ size)\ or\ (learning\ rate) α=(step size) or (learning rate)
θ n e w = θ o l d − α ∇ θ J ( θ ) \theta^{new}=\theta^{old}-\alpha \nabla_\theta J(\theta) θnew=θold−α∇θJ(θ)
更新唯一的参数 θ \theta θ: θ j n e w = θ j o l d − α α α θ j o l d J ( θ ) \theta_j^{new}=\theta_j^{old}-\alpha \frac \alpha{\alpha\ \theta_j^{old}}J(\theta) θjnew=θjold−αα θjoldαJ(θ)
while True:
theta_grad = evaluate_gradient(J,corpus,theta)
theta = theta - alpha * theta_grad