定时器实现之时间轮算法
前言
在看这篇文章的时候对其中超时控制一块儿有点好奇。通过时间轮来控制超时?啥是时间轮?怎么控制的?文章会先介绍常见的计时超时处理,再引入时间轮介绍及 netty 在实现时的一些细节,最后总结下实现的一些优缺点。个人观点,如有错误望指正。
计时/超时
JDK 中有许多经典的计时/超时计算的实现。例如 AQS 中的 doAcquireNanos, FutureTask 中的 awitDone, 从原理上来讲都是通过以下这种两种计时方式来实现的。

这里有两个问题:
为什么要用 LockSupport.parkNanos 不用 Object.wait/Thread.sleep?
LockSupport 是使用来实现底层操作,比如
park/unpark,源码文档开头第一句是 LockSupport 是创建锁或其他同步类的基本线程同步原语(p.s. 个人觉得就是基本工具的意思吧)。根据文档内容我整理了几个要点:有三种情况会从休眠中唤醒:
回到问题,为什么不使用 Object.wait ?个人认为是因为我们不能保证 wait 是在 notify/notifyAll 之前执行的。如果在之后,就会一直阻塞下去。
为什么不用 Thread.sleep?个人认为首先需要要处理
InterruptedException,其次 sleep 必须休眠设定的时间,无法中途唤醒。
使用 LockSupport 需要每个线程关联一个 permit,类似于 Semaphore 信号量同步类计数的原理,只是不会像 Semaphore 一样累加,类似于只有 0/1 两个值。调用 park 阻塞 permit 为 0,调用 unpark 恢复 permit 为 1。
由于 permit 的原因,线程之间的竞争具有活性(liveness),非 0 即 1,不会产生死锁。
no reason return:只要 unpark 就会在任何时候恢复,所以一般建议在循环中使用,时刻检查循环条件,所以 park 其实是自旋的一种优化,避免长时间空转。

unpark 调用
其他线程调用了休眠线程的 interrupt,但不会抛出
InterruptedException虚调用(这个不太了解。。)
为什么要用 System.nanoTime 不用 System.currentTimeMillis?
currentTimeMillis 返回的是当前时间和 1970.01.01 midnight 之间的差值。如果发生时钟回拨或者手动把时钟改到以前,两次记录的时间差值就有可能为负了。
nanoTime 在 JDK 文档中是建议用来做耗时计算的。nanoTime 并不是严格意义上的时间,只是 JVM 实例启动后随机选取的一个固定且任意的原点时间(可能是未来时间,值有可能为负数)开始计时。所以正确使用 nanoTime 的姿势是:
// 耗时计算
long startTime = System.nanoTime();
long estimatedTime = System.nanoTime() - startTime;
// 比较两个时间
long t0 = System.nanoTime();
long t1 = System.nanoTime();
// 由于存在溢出的问题
// t0 < t1 不一定成立,比如 t0 是正数,t1 溢出成负数了
// 所以应该使用 t1 - t0 < 0
时间轮算法
 image.png
image.png
超时的本质个人理解也的确是处理未来到达的定时任务,通过上述的方式可以控制超时需要每个线程独自控制,时间轮的这种方式更适合异步批量。Netty 针对 I/O 超时控制做了一些优化,参考这篇论文实现了 HashedWheelTimer。从上图可知,时间轮会分为固定长度的 bucket,任务根据设定的 delay 时间计算放入指定的 bucket, 同一个 buket 下通过双向链表相连。其实就是一个 HashMap 。HashedWheelTimer 会通过一个线程循环的查每个 bucket 下有哪些已经可以执行的定时任务并执行。从上面的图也可以发现,不同 delay 的定时任务也可能会落到同一个 bucket 下,但并不代表触发时间是相同的,比如上图中有 10 个 tick,定时 1s 和 11s 都会落在 tick 1 上,但定时 11s 应该在下一轮时才触发。所以应该还要记录每个任务需要在第几轮触发。
使用案例
基于 Netty 的中间件有很多,大多都会用到这个 Timer 来做些事情。下面的案例源码来自蚂蚁开源的 sofa-bolt。
一次正常的异步请求超时控制
sofa-bolt 中的自行封装的异步请求是与 JDK 中行为一致的。调用后立即返回,通过
future.get()/get(long timeout, TimeUnit unit),获取调用结果。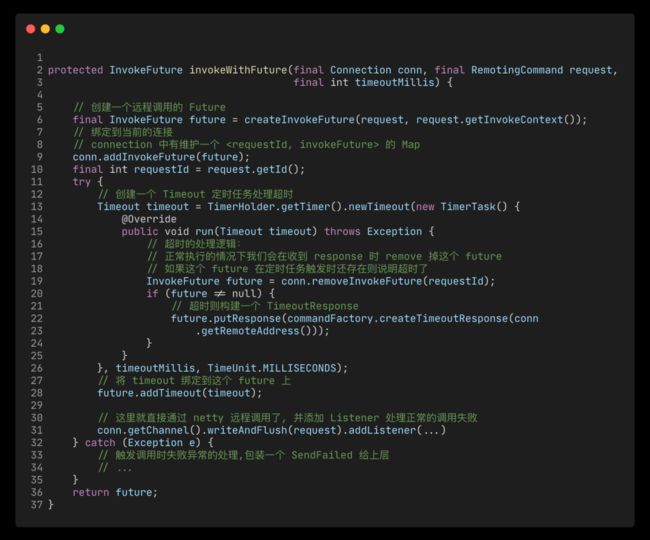 invokeWithFuture
invokeWithFuture 心跳检测超时控制
sofa-bolt 的实现借用了 Netty 的 IdleStateEvent 触发, 逻辑很简单,就是通过特殊的心跳命令定时去检查连接是否还在线,记录心跳失败的次数,超过设定阈值就抛出异常。所以分为以下两步:
源码挺好看懂,详细了解可以::point_right: 点这里
构建一个定时任务触发超时的逻辑
 new-timeout
new-timeout 根据 response 处理心跳
处理心跳会在连接上添加一个
Listener,当收到响应时触发。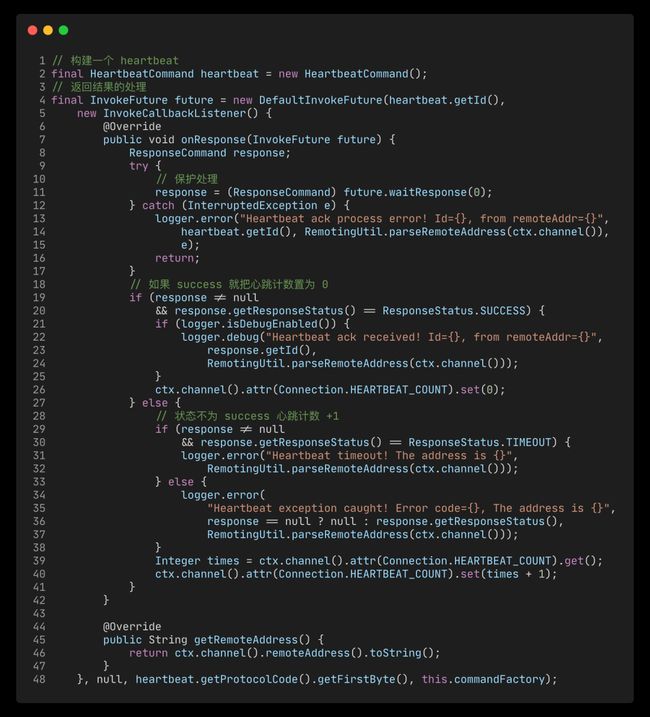 invokeCallbackListener
invokeCallbackListener
实现细节
image.png
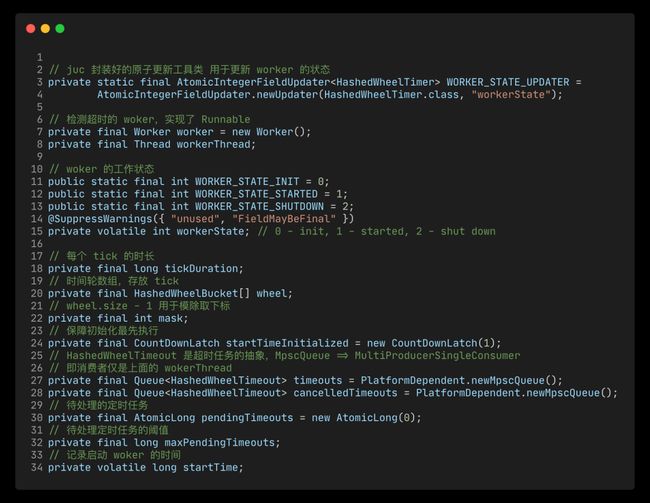
还是需要看下这个图,从图中可以大致看到构造一个时间轮需要的属性。
wheelSize:一个时间轮需要设置多少个 Tick, 默认是 512 个,size 默认会向上取值到最接近的 2 次幂,毕竟位运算计算下标时有奇效。
tickDuration: 每一个 tick 时长的设置。默认是 100 ms。这里如果设置太长可能会积压很多任务在一个 tick 上。
官方建议:不要创建太多 HashedWheelTimer 的实例。时间轮应该是共享的,而不是频繁的创建。并且 HashedWheelTimer 在初始化的时候都会创建一个 worker 线程进行调度,频繁创建也会造成很大的消耗。
所以可以看到在 sofa-bolt 中获取实例是通过单例来处理的。

属性
HashedwheelTimer 使用无锁编程的风格来实现了时间轮算法。所以大量使用了 JUC 下的工具类,是学习并发编程的模版案例了。
HashedWheelBucket & HashedWheelTimeout
HashedWheelBucket 用于存储每个 tick 上的超时任务,是个链表结构,有记录头尾节点,通过 bucket 来完成 timeout 的增删改。节点当然就是
HashedWheelTimeout,HashedWheelTimeout记录着前后节点,所以就形成了双端队列。HashedWheelBucket HashedWheelTimeout 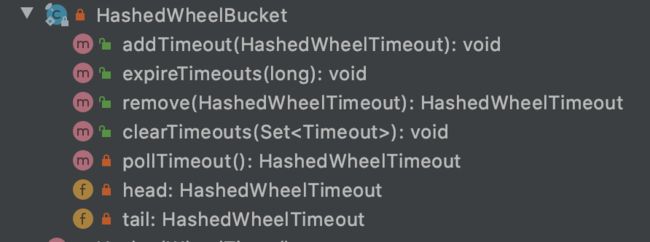
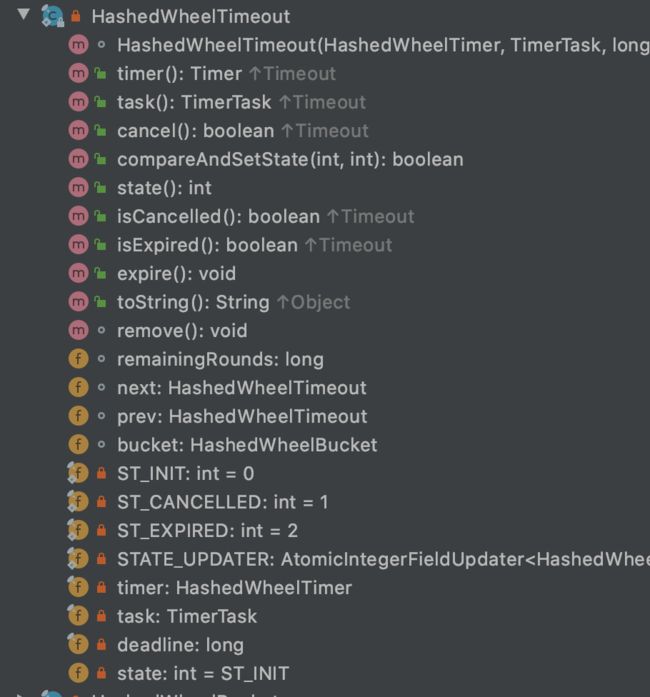
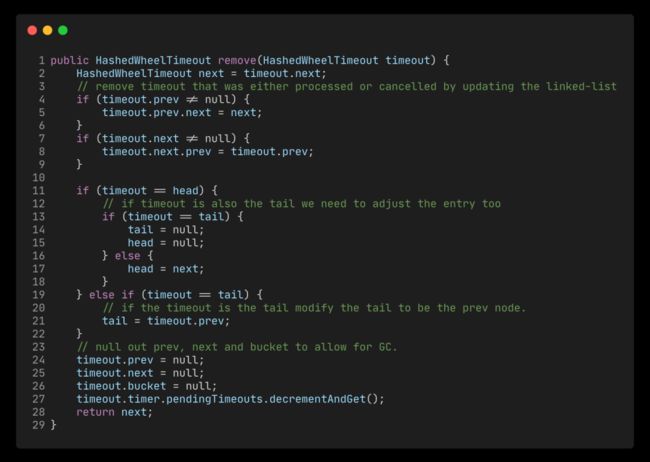
链表还支持支持从中间删除,原因是 HashedWheelTimeout 是中有记录自己是在那个 bucket 里,删除的时候使用自己所属的 bucket 来删除自己(我删我自己?)

Bucket 删除定时任务的逻辑,就是简单的链表删除是不是略显枯燥?
尽早 Return
 image.png
image.png
如果能看懂这个图的话,就不用往下看了,尽早return,下面都是字看着累。彩色的线是 worker 在运行状态下会循环做的几个操作。
删除存在 cancelledTimeouts 队列中的失效任务
将缓存在 timeouts 队列中的新任务存放到时间轮上
执行该段时间内需要触发的定时任务
构造器
构造就是对上述的未赋值的属性做一些补充。节约篇幅展示一些细节:
构造的时候需要根据设置的 ticksPerWheel 创建对应的一个时间轮 Bucket 数组。用于在每个 tick 中存放对应的超时任务,并且还会把 ticksPerWheel 匹配到最近的 2 次幂上,方便位运算计算下标。
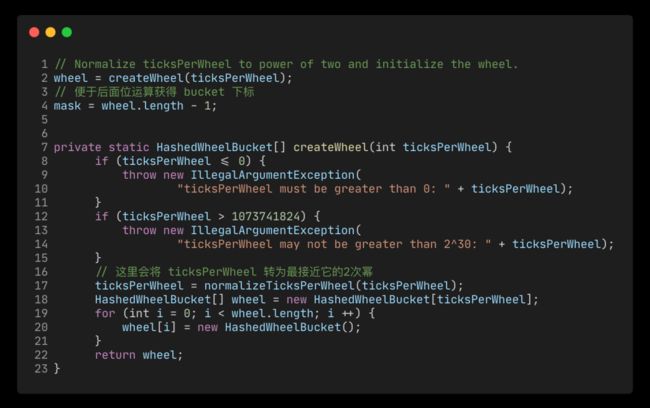 normalizeBucket
normalizeBucket 实例限制,最大 64 个时间轮实例
 instance-limit
instance-limit
创建超时任务
从上述 sofa-bolt 的使用案例中可以看出,一切都是从 newTimeout 开始的,然后就结束了(开箱即用.jpg)...事实上这也就是最核心的逻辑了。看源码的话,省略掉一些参数校验的代码,就剩就十几行。一眼看下去应该也就会好奇start() 里面的逻辑。
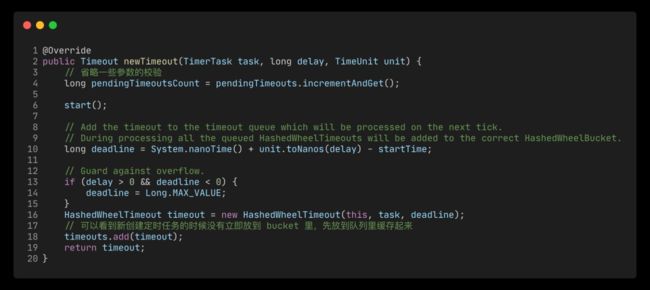 newTimeout
newTimeout
start 方法的逻辑也简单,就是启动 woker 线程。有个需要注意的点是,start方法会使用 startTimeInitialized(countDownLatch) 阻塞等待 startTime 赋值完成,毕竟 startTime 是后续超时比较的依据。
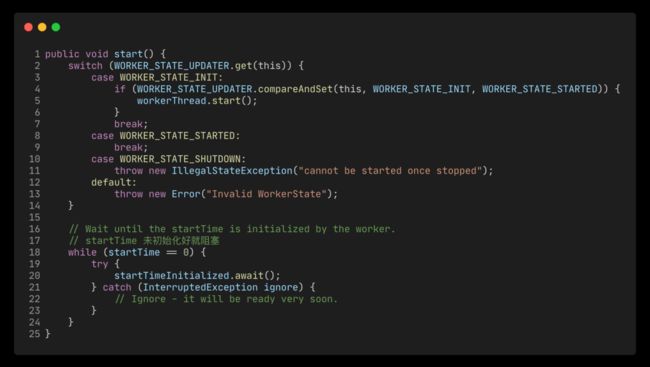 woerkStart
woerkStart
Worker
woker 线程是 HashedWheelTimer 的核心,实现了 Runnable 接口。我们通过 newTimeout 创建的定时任务,并不会直接放到时间轮上,而是缓存起来,当 woker 跑起来之后遍历到哪个 tick 就会把缓存队列里对应的这个 tick 下的定时任务放到 bucket 里,然后执行该 tick 下允许触发定时的 timeout。woker 线程在启动后只要没有被关闭就会不停的扫描下去。
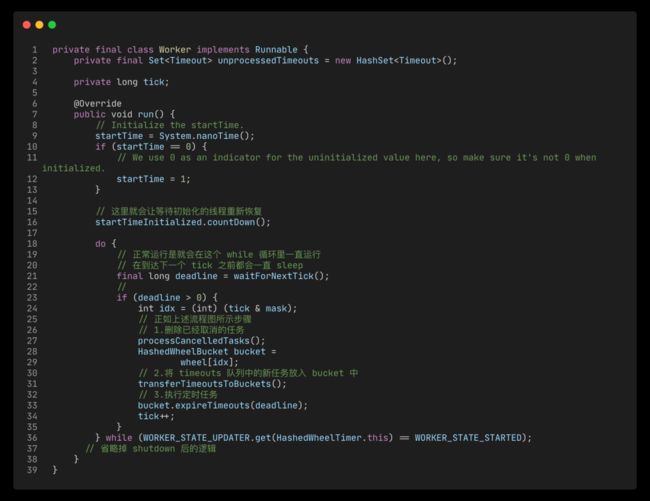 worker-run
worker-run
waitForNextTick
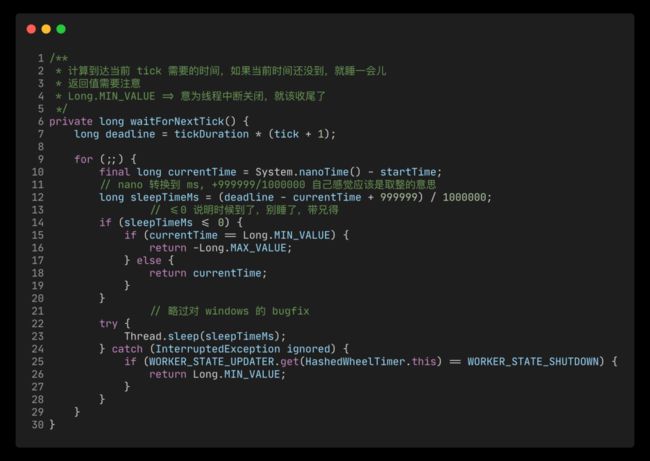 image.png
image.png
向 Bucket 添加定时任务
这里会把缓存在 MpscQueue 中的 Timeout 转移到 bucket 中,计算出正确的 bucketIndex 以及对应的轮数。

执行超时任务
触发超时的逻辑很简单,整个流程是标准的双向链表增删改。需要注意的是,文章开头所说的不同定时任务可能活落到同一个 bucket 上,此时需要根据 remainingRrounds 判断是否在当前 tick 下执行。
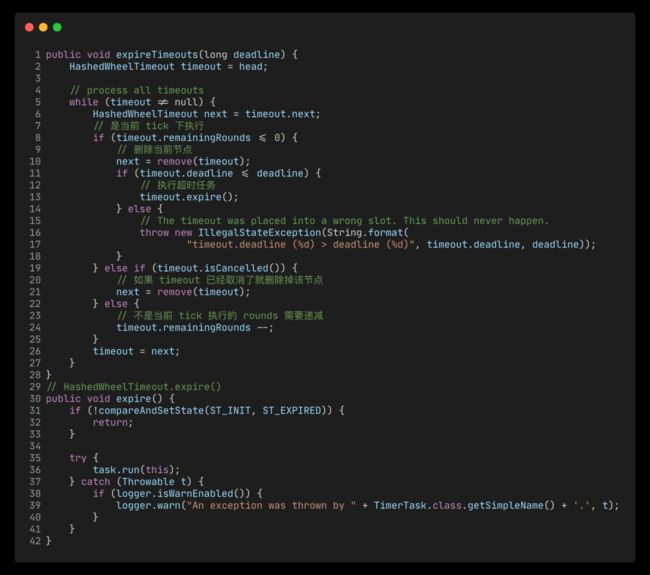 expireTimeouts
expireTimeouts
总结
HashedWheelTimer 加上注释只有 800+ 行代码,代码通俗易懂且精巧,非常值得借鉴学习。文章只介绍了新建定时任务的流程,其实还有取消,终止等等的处理,都是值得一看的。当然还是有些不足的地方:
HashedWheelTimer适合于短平快的业务,由于 worker 是单线程的,耗时过长的定时任务会导致后续的任务阻塞。所以可以看到使用案例基本上都是立即返回的。批量耗时的任务还是应该使用业界流行的定时任务框架。内存占用会比较大。前文有说过在创建定时任务的时候并不会直接放到 bucket 里而是先放到一个
MpscQueue里,当 worker 走到定时任务所在的 tick 时才会将其添加进去。而且 bucket 本身数组 + 链表也会有很大的内存占用。如果任务时间跨度过大,remainingRounds 会特别大,如果期间没有其他的定时任务就会空转很长时间,浪费资源。对此 Kafka 有给出优化的方案:层级时间轮,根据时分秒都设置一个时间轮,粒度细分也更好控制。
参考
定时器的几种实现方式
sofa-bolt 介绍
全文完
以下文章您可能也会感兴趣:
锁优化的简单思路
iOS开发:Archive、ipa 和 App 包瘦身
压力测试必知必会
分布式 Session 之 Spring Session 架构与设计
缓存的那些事
Java 并发编程 -- 线程池源码实战
Lombok Builder 构建器做了哪些事情?
WePY 2.0 新特性
SSL证书的自动化管理
你真的懂 Builder 设计模式吗?论如何实现真正安全的 Builder 模式
我们正在招聘 Java 工程师,欢迎有兴趣的同学投递简历到 [email protected] 。
