程序性能优化知识框架
1.计算机基础知识
1.1 缓存
1) What is a “cache-friendly” code?
2)计算机缓存Cache以及Cache Line详解
3) 如何看一段代码对缓存的使用情况呢(思考)?
4)内存优化
几个问题:
i) 内存碎片
ii) 多线程使用效率
iii) 各种内存分配策略的内存消耗,比如有的释放不及时可能导致内存消耗过大?
iv) 元数据本身对内存的消耗?
TCMalloc TCMalloc
a) 如何控制内存碎片
一次申请 n 个 page, 使得均分成 size-class 后内存随便的比例小于 12.5%
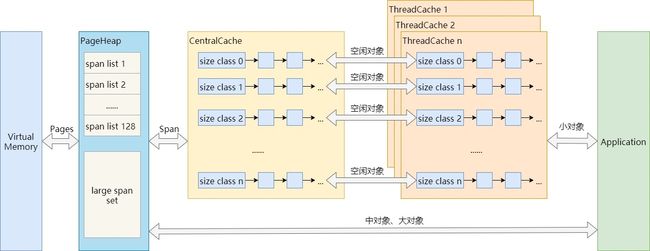
2)TCMalloc的三级缓存机制
ThreadCache, CentralCache, PageHeap
2. 性能优化
2.1. CPU 性能优化
1) 线程的亲和性(Thread Affinity)
Thread Affinity Interface (Linux* and Windows*)
Python CPU affnity
2) MPI 分布式训练
Intel® MPI Library Developer Reference for Linux* OS (Beta)
Introduction to Groups and Communicators
Efficiency computition
Intel MPI developer guide
3) CPU 频率调整
cpupower frequency-info 查看cpu的频率设置信息
cpupower frequency-set -g performance 将CPU频率设置为 performance 模式,这种模式下性能较高,但是比较耗电
powersave模式下CPU以低频运行,性能差但是省电。
3. pytorch
3.1 Tensor
1)PyTorch中的contiguous
2) Pytorch 分发机制
数据类型相关的分发机制
指令集相关的分发机制
3)Pytorch 的多线程管理
a. forward & backward 分别使用两套线程。对于线程的拓扑分布,此时应该保证同一次计算的forward线程和backward线程在同个cpu核上计算,这样才能获得较好的性能。
4)pytorch distributed training
WRITING DISTRIBUTED APPLICATIONS WITH PYTORCH
这个文档介绍了 multinode 的基础,比如 scatter, gather, allreduce等等,对于入门很有帮助。
DISTRIBUTED COMMUNICATION PACKAGE - TORCH.DISTRIBUTED
这个文档则主要介绍 pytorch 提供的 multinode 通信接口,相当于是对上一个文档的 API 介绍
A Gentle Introduction to Multi GPU and Multi Node Distributed Training
DDPDISTRIBUTED DATA PARALLEL
DDP tutorial
model parallel vs data parallel
oneCCL
Intel MPI process PIN
5) pytorch 框架学习教程
PyTorch – Internal Architecture Tour
6) 性能分析
torch.autograd.profiler.profile 是一个上下文管理器,可以帮助统计每个 function 的 C++ kernel的执行时间。如果某个C++kernel的时间没有统计到,你在C++kernel中使用 RECORD_FUNCTION宏来enable profile。 比如要统计is_contiguous函数的时间信息:RECORD_FUNCTION("is_contiguous", std::vector
4. 深度学习
4.1 基础理论
1)Backward and SGD
2)读源码理解 Pytorch 的 autograd 机制
3)pytorch 内部实现机制