- Hadoop与云原生集成:弹性扩缩容与OSS存储分离架构深度解析
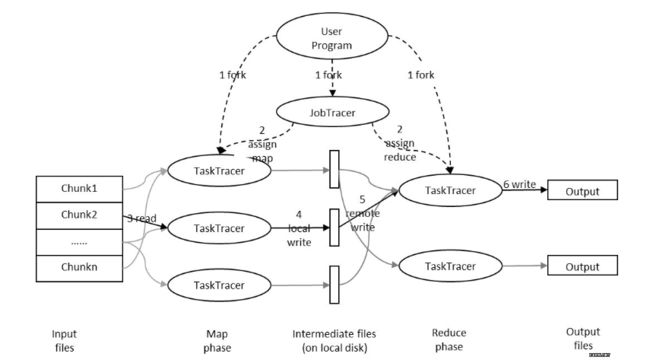
Hadoop与云原生集成的必要性Hadoop在大数据领域的基石地位作为大数据处理领域的奠基性技术,Hadoop自2006年诞生以来已形成包含HDFS、YARN、MapReduce三大核心组件的完整生态体系。根据CSDN技术社区的分析报告,全球超过75%的《财富》500强企业仍在使用Hadoop处理EB级数据,其分布式文件系统HDFS通过数据分片(默认128MB块大小)和三副本存储机制,成功解决了P
- 24.park和unpark方法
卷土重来…
java并发编程java
1.park方法可以暂停线程,线程状态为wait。2.unpark方法可以恢复线程,线程状态为runnable。3.LockSupport的静态方法。4.park和unpark方法调用不分先后,unpark先调用,park后执行也可以恢复线程。publicclassParkDemo{publicstaticvoidmain(String[]args){Threadt1=newThread(()->
- AI Agent开发学习系列 - langchain之Chains的使用(7):用四种处理文档的预制链轻松实现文档对话
alex100
AIAgent学习人工智能langchainprompt语言模型python
在LangChain中,四种文档处理预制链(stuff、refine、mapreduce、mapre-rank)是实现文档问答、摘要等任务的常用高阶工具。它们的核心作用是:将长文档切分为块,分步处理,再整合结果,极大提升大模型处理长文档的能力。stuff直接拼接所有文档内容到prompt,一次性交给大模型处理。适合文档较短、token不超限的场景。refine递进式摘要。先对第一块文档生成初步答案
- Hive简介
文章目录Hive简介Hive特点Hive和RDBMS的对比Hive的架构Hive的数据组织Hive数据类型Hive简介1、Hive由Facebook实现并开源2、是基于Hadoop的一个数据仓库工具3、可以将结构化的数据映射为一张数据库表4、并提供HQL(HiveSQL)查询功能5、底层数据是存储在HDFS上6、Hive的本质是将SQL语句转换为MapReduce任务运行7、使不熟悉MapRedu
- python基于Hadoop的NBA球员大数据分析与可视化系统
目录技术栈介绍具体实现截图系统设计研究方法:设计步骤设计流程核心代码部分展示研究方法详细视频演示试验方案论文大纲源码获取/详细视频演示技术栈介绍Django-SpringBoot-php-Node.js-flask本课题的研究方法和研究步骤基本合理,难度适中,本选题是学生所学专业知识的延续,符合学生专业发展方向,对于提高学生的基本知识和技能以及钻研能力有益。该学生能够在预定时间内完成该课题的设计。
- 大数据技术之集群数据迁移
dfs.namenode.rpc-address.nameservice1.namenode30hadoop104:8020dfs.namenode.rpc-address.nameservice1.namenode37hadoop106:8020dfs.namenode.http-address.nameservice1.namenode30hadoop104:9870dfs.namenode.
- HIVE(二)
2301_78012738
hive数据仓库
目录访问HIVE的三种方式DDLDML数据操作向表中装载数据数据导出常用函数Like和RLike分组Join排序分区表和分桶表访问HIVE的三种方式启动Hive命令,CtrlC退出客户端,执行测试语句,与sql一致[wyc@hadoop102hive]$bin/hive经验小结:在hive中执行语句报错:ExecutionError,returncode2fromorg.apache.hadoop
- 安全运维的 “五层防护”:构建全方位安全体系
KKKlucifer
安全运维
在数字化运维场景中,异构系统复杂、攻击手段隐蔽等挑战日益突出。保旺达基于“全域纳管-身份认证-行为监测-自动响应-审计溯源”的五层防护架构,融合AI、零信任等技术,构建全链路安全运维体系,以下从技术逻辑与实践落地展开解析:第一层:全域资产纳管——筑牢安全根基挑战云网基础设施包含分布式计算(Hadoop/Spark)、数据流处理(Storm/Flink)等异构组件,通信协议繁杂,传统方案难以全面纳管
- Hive 事务表(ACID)问题梳理
文章目录问题描述分析原因什么是事务表概念事务表和普通内部表的区别相关配置事务表的适用场景注意事项设计原理与实现文件管理格式参考博客问题描述工作中需要使用pyspark读取Hive中的数据,但是发现可以获取metastore,外部表的数据可以读取,内部表数据有些表报错信息是:AnalysisException:org.apache.hadoop.hive.ql.metadata.HiveExcept
- Docker快速构建Hive测试环境
静谧星光
dockerhive容器编程
Docker是一种流行的容器化平台,可以帮助我们快速构建和管理应用程序的环境。在本文中,我们将学习如何使用Docker快速构建Hive测试环境。Hive是一个基于Hadoop的数据仓库基础设施,它提供了一种类似于SQL的查询语言,用于分析和处理大规模数据集。步骤1:安装Docker和DockerCompose首先,我们需要安装Docker和DockerCompose。您可以根据您的操作系统类型,从
- HDFS 伪分布模式搭建与使用全攻略(适合初学者 & 开发测试环境)
huihui450
hdfshadoop大数据
HDFS(HadoopDistributedFileSystem)作为Hadoop生态系统的核心组件,广泛应用于海量数据的分布式存储场景。对于开发者而言,伪分布模式提供了一种低成本、高还原度的学习与测试方式。本文将详细介绍如何在本地搭建并使用HDFS的伪分布模式,包括环境准备、配置过程、常用命令及常见问题排查,帮助你快速入门Hadoop分布式文件系统的实践操作。一、什么是伪分布模式?Hadoop有
- MapReduce学习笔记
1.MapReduce做什么Mapper负责“分”,即把复杂的任务分解为若干个“简单的任务”来处理。Reducer负责对map阶段的结果进行汇总。2.MapReduce工作机制实体一:客户端,用来提交MapReduce作业。实体二:JobTracker,用来协调作业的运行。实体三:TaskTracker,用来处理作业划分后的任务。实体四:HDFS,用来在其它实体间共享作业文件。3.编写MapRed
- MapReduce 学习
chuanauc
mapreduce学习大数据
MapReduce的过程:mapshufflereduce其中,程序员需要实现的内容是:程序员手动实现Map任务的具体逻辑,将数据根据Map代码进行分割,返回(key,value)键值对然后这些(Key,Values)键值对先会被存放到磁盘,然后由MapReduce按照Key,进行排序,排序原则为,将同一个Key的键值对组织到一起,然后将同Key的键值对组,按照Key排序。而后将每个Map节点上找
- 云原生--微服务、CICD、SaaS、PaaS、IaaS
青秋.
云原生docker云原生微服务kubernetesserverlessservice_meshci/cd
往期推荐浅学React和JSX-CSDN博客一文搞懂大数据流式计算引擎Flink【万字详解,史上最全】-CSDN博客一文入门大数据准流式计算引擎Spark【万字详解,全网最新】_大数据spark-CSDN博客目录1.云原生概念和特点2.常见云模式3.云对外提供服务的架构模式3.1IaaS(Infrastructure-as-a-Service)3.2PaaS(Platform-as-a-Servi
- Spark运行架构
EmoGP
Sparkspark架构大数据
Spark框架的核心是一个计算引擎,整体来说,它采用了标准master-slave的结构 如下图所示,它展示了一个Spark执行时的基本结构,图形中的Driver表示master,负责管理整个集群中的作业任务调度,图形中的Executor则是slave,负责实际执行任务。由上图可以看出,对于Spark框架有两个核心组件:DriverSpark驱动器节点,用于执行Spark任务中的main方法,负
- Spark 各种配置项
zhixingheyi_tian
大数据sparkSparkConfsparkjvmjava
/bin/spark-shell--masteryarn--deploy-modeclient/bin/spark-shell--masteryarn--deploy-modeclusterTherearetwodeploymodesthatcanbeusedtolaunchSparkapplicationsonYARN.Inclustermode,theSparkdriverrunsinside
- Spark RDD 及性能调优
Aurora_NeAr
sparkwpfc#
RDDProgrammingRDD核心架构与特性分区(Partitions):数据被切分为多个分区;每个分区在集群节点上独立处理;分区是并行计算的基本单位。计算函数(ComputeFunction):每个分区应用相同的转换函数;惰性执行机制。依赖关系(Dependencies)窄依赖:1个父分区→1个子分区(map、filter)。宽依赖:1个父分区→多个子分区(groupByKey、join)。
- Apache Iceberg数据湖基础
Aurora_NeAr
apache
IntroducingApacheIceberg数据湖的演进与挑战传统数据湖(Hive表格式)的缺陷:分区锁定:查询必须显式指定分区字段(如WHEREdt='2025-07-01')。无原子性:并发写入导致数据覆盖或部分可见。低效元数据:LIST操作扫描全部分区目录(云存储成本高)。Iceberg的革新目标:解耦计算引擎与存储格式(支持Spark/Flink/Trino等);提供ACID事务、模式
- YARN container cpu超核如何解决
fzip
YARN超核
在ApacheHadoopYARN中,ContainerCPU超核(即Container使用的CPU资源超过分配量)是一个常见问题,可能导致集群性能下降或不稳定。以下是解决该问题的详细步骤:1.问题诊断1.1确认超核现象查看YARNWebUI:访问http://:8088,检查Container的CPU使用率是否持续超过分配的vCore数。检查NodeManager日志:查看/var/log/ha
- Hadoop-Mapreduce入门
Hadoop-Mapreduce入门MapReduce介绍mapreduce设计MapReduce编程规范入门案例WordCountMapReduce介绍MapReduce的思想核心是“分而治之”,适用于大量复杂的任务处理场景(大规模数据处理场景)。知识。Map负责“分”,把复杂的任务分解为若干个“简单的任务”来并行处理。可以进行拆分的前提是这些小任务可以并行计算,彼此间几乎没有依赖关系。Redu
- Hadoop MapReduce入门
且行且安~
数据分析进阶之路Linux命令hadoopMapReduce入门
入门简介计算过程分为两个阶段Map和ReduceMap阶段并行处理输入数据Reduce阶段对Map结果进行汇总针对python语言来说:map函数或者reduce函数来说,输出的数据格式为元组tuple一个简单的MapReduce程序只需要指定map()reduce()input()output()剩下的由框架完成。Linux常见命令:-读取文件(文本文件,在Windows下使用记事本打开的文件)
- Hadoop MapReduce 入门
一、Hadoop3.0.4环境准备1.环境要求Java8(Hadoop3.0.4不支持Java11+)单节点或多节点Linux系统(推荐Ubuntu18.04+)至少4GB内存(建议8GB+)50GB以上磁盘空间2.安装Java#安装Java8sudoapt-getinstallopenjdk-8-jdk#验证安装java-version3.下载与安装Hadoop3.0.4#下载Hadoop3.0
- 大数据技术之Flink
第1章Flink概述1.1Flink是什么1.2Flink特点1.3FlinkvsSparkStreaming表Flink和Streaming对比FlinkStreaming计算模型流计算微批处理时间语义事件时间、处理时间处理时间窗口多、灵活少、不灵活(窗口必须是批次的整数倍)状态有没有流式SQL有没有1.4Flink的应用场景1.5Flink分层API第2章Flink快速上手2.1创建项目在准备
- 管理大数据存储的十大技巧
weixin_34238633
大数据数据库运维
在1990年,每一台应用服务器都倾向拥有直连式系统(DAS)。SAN的构建则是为了更大的规模和更高的效率提供共享的池存储。Hadoop已经逆转了这一趋势回归DAS。每一个Hadoop集群都拥有自身的——虽然是横向扩展型——直连式存储,这有助于Hadoop管理数据本地化,但也放弃了共享存储的规模和效率。如果你拥有多个实例或Hadoop发行版,那么你就将得到多个横向扩展的存储集群。而我们所遇到的最大挑
- MapReduce数据处理过程2万字保姆级教程
大模型大数据攻城狮
mapreduce大数据yarncdhhadoop大数据面试shuffle
目录1.MapReduce的核心思想:分而治之的艺术2.HadoopMapReduce的架构:从宏观到微观3.WordCount实例:从代码到执行的完整旅程4.源码剖析:Job.submit的魔法5.Map任务的执行:从分片到键值对6.Shuffle阶段:MapReduce的幕后英雄7.Reduce任务的执行:从数据聚合到最终输出8.Combiner的魔法:提前聚合的性能利器9.Partition
- Hadoop核心组件最全介绍
Cachel wood
大数据开发hadoop大数据分布式spark数据库计算机网络
文章目录一、Hadoop核心组件1.HDFS(HadoopDistributedFileSystem)2.YARN(YetAnotherResourceNegotiator)3.MapReduce二、数据存储与管理1.HBase2.Hive3.HCatalog4.Phoenix三、数据处理与计算1.Spark2.Flink3.Tez4.Storm5.Presto6.Impala四、资源调度与集群管
- 数据仓库技术及应用(Hive 产生背景与架构设计,存储模型与数据类型)
娟恋无暇
数据仓库笔记hive
1.Hive产生背景传统Hadoop架构存在的一些问题:MapReduce编程必须掌握Java,门槛较高传统数据库开发、DBA、运维人员学习门槛高HDFS上没有Schema的概念,仅仅是一个纯文本文件Hive的产生:为了让用户从一个现有数据基础架构转移到Hadoop上现有数据基础架构大多基于关系型数据库和SQL查询Facebook诞生了Hive2.Hive是什么官网:https://hive.ap
- 缺少关键的 MapReduce 框架文件
计算圆周率时提醒Hadoop集群缺少关键的MapReduce框架文件mr-framework.tar.gz在http://master:7180/cmf/services/4/status里直接安装再次运行代码:
- 大数据 ETL 工具 Sqoop 深度解析与实战指南
一、Sqoop核心理论与应用场景1.1设计思想与技术定位Sqoop是Apache旗下的开源数据传输工具,核心设计基于MapReduce分布式计算框架,通过并行化的Map任务实现高效的数据批量迁移。其特点包括:批处理特性:基于MapReduce作业实现导入/导出,适合大规模离线数据迁移,不支持实时数据同步。异构数据源连接:支持关系型数据库(如MySQL、Oracle)与Hadoop生态(HDFS、H
- 安装Hadoop集群&入门&源码编译
只年
大数据Hadoophadoop大数据分布式
安装Hadoop集群完全分布式先决条件准备三台机器NameStaticIPDESCbigdata102192.168.1.102DataNode、NodeManager、NameNodebigdata103192.168.1.103DataNode、NodeManager、ResourceManagerbigdata104192.168.1.104DataNode、NodeManager、Seco
- Java常用排序算法/程序员必须掌握的8大排序算法
cugfy
java
分类:
1)插入排序(直接插入排序、希尔排序)
2)交换排序(冒泡排序、快速排序)
3)选择排序(直接选择排序、堆排序)
4)归并排序
5)分配排序(基数排序)
所需辅助空间最多:归并排序
所需辅助空间最少:堆排序
平均速度最快:快速排序
不稳定:快速排序,希尔排序,堆排序。
先来看看8种排序之间的关系:
1.直接插入排序
(1
- 【Spark102】Spark存储模块BlockManager剖析
bit1129
manager
Spark围绕着BlockManager构建了存储模块,包括RDD,Shuffle,Broadcast的存储都使用了BlockManager。而BlockManager在实现上是一个针对每个应用的Master/Executor结构,即Driver上BlockManager充当了Master角色,而各个Slave上(具体到应用范围,就是Executor)的BlockManager充当了Slave角色
- linux 查看端口被占用情况详解
daizj
linux端口占用netstatlsof
经常在启动一个程序会碰到端口被占用,这里讲一下怎么查看端口是否被占用,及哪个程序占用,怎么Kill掉已占用端口的程序
1、lsof -i:port
port为端口号
[root@slave /data/spark-1.4.0-bin-cdh4]# lsof -i:8080
COMMAND PID USER FD TY
- Hosts文件使用
周凡杨
hostslocahost
一切都要从localhost说起,经常在tomcat容器起动后,访问页面时输入http://localhost:8088/index.jsp,大家都知道localhost代表本机地址,如果本机IP是10.10.134.21,那就相当于http://10.10.134.21:8088/index.jsp,有时候也会看到http: 127.0.0.1:
- java excel工具
g21121
Java excel
直接上代码,一看就懂,利用的是jxl:
import java.io.File;
import java.io.IOException;
import jxl.Cell;
import jxl.Sheet;
import jxl.Workbook;
import jxl.read.biff.BiffException;
import jxl.write.Label;
import
- web报表工具finereport常用函数的用法总结(数组函数)
老A不折腾
finereportweb报表函数总结
ADD2ARRAY
ADDARRAY(array,insertArray, start):在数组第start个位置插入insertArray中的所有元素,再返回该数组。
示例:
ADDARRAY([3,4, 1, 5, 7], [23, 43, 22], 3)返回[3, 4, 23, 43, 22, 1, 5, 7].
ADDARRAY([3,4, 1, 5, 7], "测试&q
- 游戏服务器网络带宽负载计算
墙头上一根草
服务器
家庭所安装的4M,8M宽带。其中M是指,Mbits/S
其中要提前说明的是:
8bits = 1Byte
即8位等于1字节。我们硬盘大小50G。意思是50*1024M字节,约为 50000多字节。但是网宽是以“位”为单位的,所以,8Mbits就是1M字节。是容积体积的单位。
8Mbits/s后面的S是秒。8Mbits/s意思是 每秒8M位,即每秒1M字节。
我是在计算我们网络流量时想到的
- 我的spring学习笔记2-IoC(反向控制 依赖注入)
aijuans
Spring 3 系列
IoC(反向控制 依赖注入)这是Spring提出来了,这也是Spring一大特色。这里我不用多说,我们看Spring教程就可以了解。当然我们不用Spring也可以用IoC,下面我将介绍不用Spring的IoC。
IoC不是框架,她是java的技术,如今大多数轻量级的容器都会用到IoC技术。这里我就用一个例子来说明:
如:程序中有 Mysql.calss 、Oracle.class 、SqlSe
- 高性能mysql 之 选择存储引擎(一)
annan211
mysqlInnoDBMySQL引擎存储引擎
1 没有特殊情况,应尽可能使用InnoDB存储引擎。 原因:InnoDB 和 MYIsAM 是mysql 最常用、使用最普遍的存储引擎。其中InnoDB是最重要、最广泛的存储引擎。她 被设计用来处理大量的短期事务。短期事务大部分情况下是正常提交的,很少有回滚的情况。InnoDB的性能和自动崩溃 恢复特性使得她在非事务型存储的需求中也非常流行,除非有非常
- UDP网络编程
百合不是茶
UDP编程局域网组播
UDP是基于无连接的,不可靠的传输 与TCP/IP相反
UDP实现私聊,发送方式客户端,接受方式服务器
package netUDP_sc;
import java.net.DatagramPacket;
import java.net.DatagramSocket;
import java.net.Ine
- JQuery对象的val()方法执行结果分析
bijian1013
JavaScriptjsjquery
JavaScript中,如果id对应的标签不存在(同理JAVA中,如果对象不存在),则调用它的方法会报错或抛异常。在实际开发中,发现JQuery在id对应的标签不存在时,调其val()方法不会报错,结果是undefined。
- http请求测试实例(采用json-lib解析)
bijian1013
jsonhttp
由于fastjson只支持JDK1.5版本,因些对于JDK1.4的项目,可以采用json-lib来解析JSON数据。如下是http请求的另外一种写法,仅供参考。
package com;
import java.util.HashMap;
import java.util.Map;
import
- 【RPC框架Hessian四】Hessian与Spring集成
bit1129
hessian
在【RPC框架Hessian二】Hessian 对象序列化和反序列化一文中介绍了基于Hessian的RPC服务的实现步骤,在那里使用Hessian提供的API完成基于Hessian的RPC服务开发和客户端调用,本文使用Spring对Hessian的集成来实现Hessian的RPC调用。
定义模型、接口和服务器端代码
|---Model
&nb
- 【Mahout三】基于Mahout CBayes算法的20newsgroup流程分析
bit1129
Mahout
1.Mahout环境搭建
1.下载Mahout
http://mirror.bit.edu.cn/apache/mahout/0.10.0/mahout-distribution-0.10.0.tar.gz
2.解压Mahout
3. 配置环境变量
vim /etc/profile
export HADOOP_HOME=/home
- nginx负载tomcat遇非80时的转发问题
ronin47
nginx负载后端容器是tomcat(其它容器如WAS,JBOSS暂没发现这个问题)非80端口,遇到跳转异常问题。解决的思路是:$host:port
详细如下:
该问题是最先发现的,由于之前对nginx不是特别的熟悉所以该问题是个入门级别的:
? 1 2 3 4 5
- java-17-在一个字符串中找到第一个只出现一次的字符
bylijinnan
java
public class FirstShowOnlyOnceElement {
/**Q17.在一个字符串中找到第一个只出现一次的字符。如输入abaccdeff,则输出b
* 1.int[] count:count[i]表示i对应字符出现的次数
* 2.将26个英文字母映射:a-z <--> 0-25
* 3.假设全部字母都是小写
*/
pu
- mongoDB 复制集
开窍的石头
mongodb
mongo的复制集就像mysql的主从数据库,当你往其中的主复制集(primary)写数据的时候,副复制集(secondary)会自动同步主复制集(Primary)的数据,当主复制集挂掉以后其中的一个副复制集会自动成为主复制集。提供服务器的可用性。和防止当机问题
mo
- [宇宙与天文]宇宙时代的经济学
comsci
经济
宇宙尺度的交通工具一般都体型巨大,造价高昂。。。。。
在宇宙中进行航行,近程采用反作用力类型的发动机,需要消耗少量矿石燃料,中远程航行要采用量子或者聚变反应堆发动机,进行超空间跳跃,要消耗大量高纯度水晶体能源
以目前地球上国家的经济发展水平来讲,
- Git忽略文件
Cwind
git
有很多文件不必使用git管理。例如Eclipse或其他IDE生成的项目文件,编译生成的各种目标或临时文件等。使用git status时,会在Untracked files里面看到这些文件列表,在一次需要添加的文件比较多时(使用git add . / git add -u),会把这些所有的未跟踪文件添加进索引。
==== ==== ==== 一些牢骚
- MySQL连接数据库的必须配置
dashuaifu
mysql连接数据库配置
MySQL连接数据库的必须配置
1.driverClass:com.mysql.jdbc.Driver
2.jdbcUrl:jdbc:mysql://localhost:3306/dbname
3.user:username
4.password:password
其中1是驱动名;2是url,这里的‘dbna
- 一生要养成的60个习惯
dcj3sjt126com
习惯
一生要养成的60个习惯
第1篇 让你更受大家欢迎的习惯
1 守时,不准时赴约,让别人等,会失去很多机会。
如何做到:
①该起床时就起床,
②养成任何事情都提前15分钟的习惯。
③带本可以随时阅读的书,如果早了就拿出来读读。
④有条理,生活没条理最容易耽误时间。
⑤提前计划:将重要和不重要的事情岔开。
⑥今天就准备好明天要穿的衣服。
⑦按时睡觉,这会让按时起床更容易。
2 注重
- [介绍]Yii 是什么
dcj3sjt126com
PHPyii2
Yii 是一个高性能,基于组件的 PHP 框架,用于快速开发现代 Web 应用程序。名字 Yii (读作 易)在中文里有“极致简单与不断演变”两重含义,也可看作 Yes It Is! 的缩写。
Yii 最适合做什么?
Yii 是一个通用的 Web 编程框架,即可以用于开发各种用 PHP 构建的 Web 应用。因为基于组件的框架结构和设计精巧的缓存支持,它特别适合开发大型应
- Linux SSH常用总结
eksliang
linux sshSSHD
转载请出自出处:http://eksliang.iteye.com/blog/2186931 一、连接到远程主机
格式:
ssh name@remoteserver
例如:
ssh
[email protected]
二、连接到远程主机指定的端口
格式:
ssh name@remoteserver -p 22
例如:
ssh i
- 快速上传头像到服务端工具类FaceUtil
gundumw100
android
快速迭代用
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOExceptio
- jQuery入门之怎么使用
ini
JavaScripthtmljqueryWebcss
jQuery的强大我何问起(个人主页:hovertree.com)就不用多说了,那么怎么使用jQuery呢?
首先,下载jquery。下载地址:http://hovertree.com/hvtart/bjae/b8627323101a4994.htm,一个是压缩版本,一个是未压缩版本,如果在开发测试阶段,可以使用未压缩版本,实际应用一般使用压缩版本(min)。然后就在页面上引用。
- 带filter的hbase查询优化
kane_xie
查询优化hbaseRandomRowFilter
问题描述
hbase scan数据缓慢,server端出现LeaseException。hbase写入缓慢。
问题原因
直接原因是: hbase client端每次和regionserver交互的时候,都会在服务器端生成一个Lease,Lease的有效期由参数hbase.regionserver.lease.period确定。如果hbase scan需
- java设计模式-单例模式
men4661273
java单例枚举反射IOC
单例模式1,饿汉模式
//饿汉式单例类.在类初始化时,已经自行实例化
public class Singleton1 {
//私有的默认构造函数
private Singleton1() {}
//已经自行实例化
private static final Singleton1 singl
- mongodb 查询某一天所有信息的3种方法,根据日期查询
qiaolevip
每天进步一点点学习永无止境mongodb纵观千象
// mongodb的查询真让人难以琢磨,就查询单天信息,都需要花费一番功夫才行。
// 第一种方式:
coll.aggregate([
{$project:{sendDate: {$substr: ['$sendTime', 0, 10]}, sendTime: 1, content:1}},
{$match:{sendDate: '2015-
- 二维数组转换成JSON
tangqi609567707
java二维数组json
原文出处:http://blog.csdn.net/springsen/article/details/7833596
public class Demo {
public static void main(String[] args) { String[][] blogL
- erlang supervisor
wudixiaotie
erlang
定义supervisor时,如果是监控celuesimple_one_for_one则删除children的时候就用supervisor:terminate_child (SupModuleName, ChildPid),如果shutdown策略选择的是brutal_kill,那么supervisor会调用exit(ChildPid, kill),这样的话如果Child的behavior是gen_