python访问hbase数据
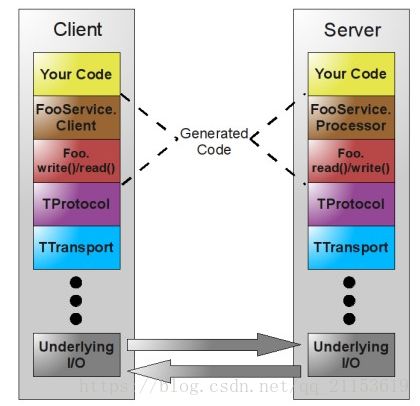
使用Python调用happybase库。thrift 是facebook开发并开源的一个二进制通讯中间件,通过thrift,我们可以用Python来操作Hbase
1、概述
Thrift最初由Facebook开发的,后来提交给了Apache基金会将Thrift作为一个开源项目。当时facebook开发使用它是为了解决系统中各系统间大数据量的传输通信以及系统之间语言环境不同需要跨平台的特性问题。Thrift是一个跨语言的服务部署框架。Thrift通过一个中间语言(IDL, 接口定义语言)来定义RPC的接口和数据类型,然后通过一个编译器生成不同语言的代码(目前支持C++,Java, Python, PHP, Ruby, Erlang, Perl, Haskell, C#, Cocoa, Smalltalk和OCaml),并由生成的代码负责RPC协议层和传输层的实现。
Thrift实际上是实现了C/S模式,通过代码生成工具将接口定义文件生成服务器端和客户端代码(可以为不同语言),从而实现服务端和客户端跨语言的支持。在Thirft描述文件中声明自己的服务,这些服务经过编译后会生成相应语言的代码文件,然后实现服务便可以了。其中protocol(协议层, 定义数据传输格式,可以为二进制或者XML等)和transport(传输层,定义数据传输方式,可以为TCP/IP传输,内存共享或者文件共享等)被用作运行时库。
首先开启Hadoop平台的HadoopMaster的thrift服务,用Xshell连接HadoopMaster,用root用户登录,如果想关闭终端之后,thrift服务继续运行,可以用daemon模式运行
2.安装happybase和thrift
pip install happybase
pip install thrift
3.尝试连接Hbase
import happybase
connection = happybase.Connection('172.8.10.142')
print connection.tables()此时会出现下面的错误:
import happybase报错,ThriftPy does not support generating module with path in protocol 'c'
Traceback (most recent call last):
File "F:\workspace_weiy\PythonDBTest\src\com\siger\hbase\hbasetest.py", line 9, in
import happybase
File "C:\Python27\lib\site-packages\happybase\__init__.py", line 10, in
'Hbase_thrift')
File "C:\Python27\lib\site-packages\thriftpy\parser\__init__.py", line 30, in load
include_dir=include_dir)
File "C:\Python27\lib\site-packages\thriftpy\parser\parser.py", line 496, in parse
url_scheme))
thriftpy.parser.exc.ThriftParserError: ThriftPy does not support generating module with path in protocol 'c'
解决方法:
- 进入如下 你的Python的安装路径下,找到parser.py文件
C:\Python27\Lib\site-packages\thriftpy\parser
打开parser.py文件,找到488行。注释掉原来488行代码,添加
#if url_scheme == '':
if len(url_scheme) <= 1:或者可以修改为
if url_scheme in ('c', ''):如果是报错’d’上面就写’d’,‘f’就写’f’
修改的时候注意py代码缩进
问题原因:
happybase1.0在win下不支持绝对路径
具体原因:happybase要读取Python\Lib\site-packages\happybase\Hbase.thrift,但在Python\Lib\site-packages\thriftpy\parser\parser.py中的487行。path是Hbase.thrift的绝对路径(我的是“F:\SoftWare\Python27\Lib\site-packages\happybase\Hbase.thrift”),但经过urlparse(path).scheme后,url_scheme变成了“c”,(这也就是报错信息中最后的“c”)。根据代码,url_scheme既不为“”,也不包含 (‘http’,’https’),则只能为raise报错。
相关资料:https://github.com/eleme/thriftpy/issues/234
4.happybase的使用
请参考http://happybase.readthedocs.io/en/latest/index.html
在此做一下简单的使用介绍
(1)建立连接
import happybase
connection = happybase.Connection('172.8.10.142')当connection被创建的时候,默认自动与Hbase建立socket连接的。
若不想自动与Hbase建立socket连接,可以将autoconnect参数设置为False
connection = happybase.Connection('172.8.10.142', autoconnect=False)然后手动与Hbase建立socket连接
connection.open()
(2)连接建立好之后查看可以使用的table
print connection.tables()因为还没有创建table,所以返回结果是 []
(3)创建一个table
connection.create_table(
'my_table',
{
'cf1': dict(max_versions=10),
'cf2': dict(max_versions=1, block_cache_enabled=False),
'cf3': dict(), # use defaults
}
)此时,我们再通过connection.tables()查看可以使用的table,结果为['my_table']
创建的table即my_table包含3个列族:cf1、cf2、cf3
(4)获取一个table实例
一个table被创建好之后,要想对其进行操作,首先要获取这个table实例
table = connection.table('my_table')
(5)使用table的命名空间
因为一个Hbase会被多个项目共同使用,所以就会导致table的命名冲突,为了解决这个问题,可以在创建table的时候,手动加上项目的名字作为table名字的前缀,例如myproject_xyz。
但是这样做比较麻烦,happybase帮我们做好了工作,我们可以在与Hbase建立连接的时候,通过设置table_prefix参数来实现这个功能
connection = happybase.Connection('172.8.10.142', table_prefix='myproject')此时connection.tables()只会返回包含在该命名空间里的tables,且返回的tables的名字会以简单的形式显示,即不包含前缀。
(6)存储数据:Hbase里 存储的数据都是原始的字节字符串
cloth_data = {'cf1:content': u'牛仔裤', 'cf1:price': '299', 'cf1:rating': '98%'}
hat_data = {'cf1:content': u'鸭舌帽', 'cf1:price': '88', 'cf1:rating': '99%'}
shoe_data = {'cf1:content': u'耐克', 'cf1:price': '988', 'cf1:rating': '100%'}
author_data = {'cf2:name': u'LiuLin', 'cf2:date': '2017-03-09'}
table.put(row='www.test1.com', data=cloth_data)
table.put(row='www.test2.com', data=hat_data)
table.put(row='www.test3.com', data=shoe_data)
table.put(row='www.test4.com', data=author_data)使用put一次只能存储一行数据
如果row key已经存在,则变成了修改数据
(7)更好的存储数据
table.put()方法会立即给Hbase Thrift server发送一条命令。其实这种方法的效率并不高,我们可以使用更高效的table.batch()方法。
# 使用batch一次插入多行数据
bat = table.batch()
bat.put('www.test5.com', {'cf1:price': 999, 'cf2:title': 'Hello Python', 'cf2:length': 34, 'cf3:code': 'A43'})
bat.put('www.test6.com', {'cf1:content': u'剃须刀', 'cf1:price': 168, 'cf1:rating': '97%'})
bat.put('www.test7.com', {'cf3:function': 'print'})
bat.send()
更有用的方法是使用上下文管理器来管理batch,这样就不用手动发送数据了,即不再需要bat.send()
# 使用with来管理batch
with table.batch() as bat:
bat.put('www.test5.com', {'cf1:price': '999', 'cf2:title': 'Hello Python', 'cf2:length': '34', 'cf3:code': 'A43'})
bat.put('www.test6.com', {'cf1:content': u'剃须刀', 'cf1:price': '168', 'cf1:rating': '97%'})
bat.put('www.test7.com', {'cf3:function': 'print'})还可以删除数据
# 在batch中删除数据
with table.batch() as bat:
bat.put('www.test5.com', {'cf1:price': '999', 'cf2:title': 'Hello Python', 'cf2:length': '34', 'cf3:code': 'A43'})
bat.put('www.test6.com', {'cf1:content': u'剃须刀', 'cf1:price': '168', 'cf1:rating': '97%'})
bat.put('www.test7.com', {'cf3:function': 'print'})
bat.delete('www.test1.com')batch将数据保存在内存中,知道数据被send,第一种send数据的方法是显示地发送,即bat.send(),第二种send数据的方法是到达with上下文管理器的结尾自动发送。这样就存在一个问题,万一数据量很大,就会占用太多的内存。所以我们在使用table.batch()的时候要通过batch_size参数来设置batch的大小
# 通过batch_size参数来设置batch的大小
with table.batch(batch_size=10) as bat:
for i in range(16):
bat.put('www.test{}.com'.format(i), {'cf1:price': '{}'.format(i)})
(8)扫描一个table里的数据
# 全局扫描一个table
for key, value in table.scan():
print key, value结果如下:

这种全局扫描一个表格其实代价是很大的,尤其是当数据量很大的时候。我们可以通过设置开始的row key 或结束的row key或者同时设置开始和结束的row key来进行局部查询
# 通过row_start参数来设置开始扫描的row key
for key, value in table.scan(row_start='www.test2.com'):
print key, value# 通过row_stop参数来设置结束扫描的row key
for key, value in table.scan(row_stop='www.test3.com'):
print key, value# 通过row_start和row_stop参数来设置开始和结束扫描的row key
for key, value in table.scan(row_start='www.test2.com', row_stop='www.test3.com'):
print key, value另外,还可以通过设置row key的前缀来进行局部扫描
# 通过row_prefix参数来设置需要扫描的row key
for key, value in table.scan(row_prefix='www.test'):
print key, value
(9)检索数据
# 检索一行数据
row = table.row('www.test4.com')
print row直接返回该row key的值(以字典的形式),结果为:
{'cf2:name': 'LiuLin', 'cf2:date': '2017-03-09'}
# 检索多行数据
rows = table.rows(['www.test1.com', 'www.test4.com'])
print rows返回的是一个list,list的一个元素是一个tuple,tuple的第一个元素是row key,第二个元素是row key的值
如果想使检索多行数据即table.rows()返回的结果是一个字典,可以这样处理
# 检索多行数据,返回字典
rows_dict = dict(table.rows(['www.test1.com', 'www.test4.com']))
print rows_dict如果想使table.rows()返回的结果是一个有序字典,即OrderedDict,可以这样处理
# 检索多行数据,返回有序字典
from collection import OrderedDict
rows_ordered_dict = OrderedDict(table.rows(['www.test1.com', 'www.test4.com']))
print rows_ordered_dict
(10)更好地检索数据
# 通过指定列族来检索数据
row = table.row('www.test1.com', columns=['cf1'])
print row# 通过指定列族中的列来检索数据
row = table.row('www.test1.com', columns=['cf1:price', 'cf1:rating'])
print row
print row['cf1:price']在Hbase里,每一个cell都有一个时间戳timestamp,可以通过时间戳来检索数据
# 通过指定时间戳来检索数据,时间戳必须是整数
row = table.row('www.test1.com', timestamp=1536565689624)
print row默认情况下,返回的数据并不会包含时间戳,如果你想获取时间戳,这样就可以了
# 在返回的数据里面包含时间戳
row = table.row(row='www.test1.com', columns=['cf1:rating', 'cf1:price'], include_timestamp=True)
print row对于同一个单元的值,Hbase存储了多个版本,在创建表的时候可以通过max_versions参数来设置一个列族的最大版本号,如果想检索某一cell所有的版本,可以这样
# 检索某一个cell所有的版本
cells = table.cells(b'www.test1.com', column='cf1:price')
print cells也可以通过version参数来指定需要检索的前n个版本,如下
# 通过设置version参数来检索前n个版本
cells = table.cells(b'www.test1.com', column='cf1:price', versions=3)
print cells
(11)删除数据
# 删除一整行数据
table.delete('www.test4.com')# 删除一个列族的数据
table.delete('www.test2.com', columns=['cf1'])# 删除一个列族中几个列的数据
table.delete('www.test2.com', columns=['cf1:name', 'cf1:price'])
(12)使用连接池
Hbase自带有线程安全的连接池,踏允许多个线程共享和重用已经打开的连接。这对于多线程的应用是非常有用的。当一个线程申请一个连接,它将获得一个租赁凭证,在此期间,这个线程单独享有这个连接。当这个线程使用完该连接之后,它将该连接归还给连接池以便其他的线程可以使用
# 创建连接,通过参数size来设置连接池中连接的个数
pool = happybase.ConnectionPool(size=3, host='172.8.10.142', table_prefix='myProject')# 获取连接
with pool.connection() as connection:
print connection.tables()转自:https://my.oschina.net/wolfoxliu/blog/856175