堆和优先队列
什么是优先队列?
- 普通队列:先进先出;后进后出
- 优先队列:出队顺序和入队顺序无关;和优先级相关
| 入队 | 出队(拿出最大元素) | |
|---|---|---|
| 普通线性结构 | O(1) | O(n) |
| 顺序线性结构 | O(n) | O(1) |
| 堆 | O(logn) | O(logn) |
堆的基本结构
二叉堆由一棵完全二叉树来表示其结构,用一个数组来表示,但一个二叉堆需要满足如下性质:
- 二叉堆的父节点的键值总是大于或等于(小于或等于)任何一个子节点的键值
- 当父节点的键值大于或等于(小于或等于)它的每一个子节点的键值时,称为最大堆(最小堆)
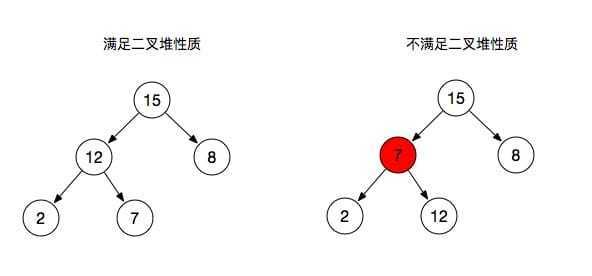
从上图可以看出:
- 左图:父节点总是大于或等于其子节点,所以满足了二叉堆的性质,
- 右图:分支节点7作为2和12的父节点并没有满足其性质(大于或等于子节点)。
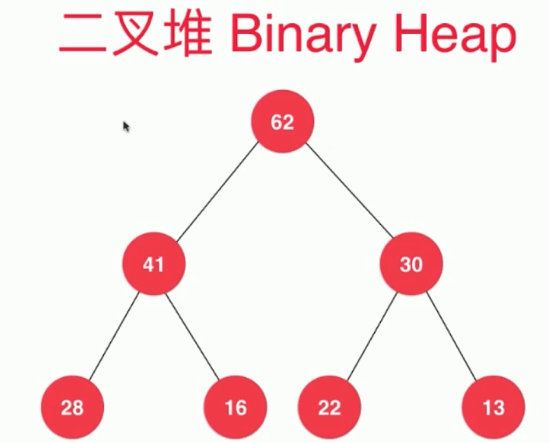
二叉堆的性质
二叉堆的使用对于优先队列的实现相当普遍。二叉堆具有结构性和堆序性:
堆是一棵被完全填满的二叉树,有可能的例外是在底层叶子上,叶子上的元素从左到右填入。这样的树称为完全二叉树。
根据完全二叉树的性质,我们可以使用一个数组来表示而不需要使用链。该数组有一个位置0,可在进行堆的插入操作时避免多次的赋值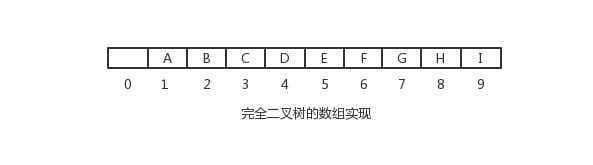
对于数组中任一位置i上的元素,其左儿子在位置2i上,右儿子在左儿子后的节点(2i+1)上,它的父亲则在位置i/2上。因此,这里不需要链就可以很简单的遍历该树。
一个堆结构将由一个(Comparable对象的)数组和一个代表当前堆的大小的整数组成。
堆序性质
在一个堆中,对于每一个节点X,X的父亲中的关键字小于或等于X中的关键字,根节点除外(它没有父亲)。根据堆序性质我们可以很容易的得出最小的元素一定在根上,因此快速找出最小元将会是件非常容易的事,并且只需要花费常数时间。
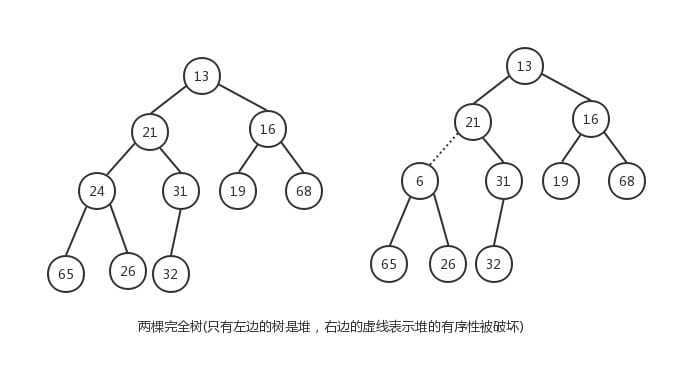
二叉堆的基本实现
public class MaxHeap> {
private Array data;
public MaxHeap(int capacity) {
data = new Array<>(capacity);
}
public MaxHeap() {
data = new Array<>();
}
//返回堆中个数
public int size() {
return data.getSize();
}
//返回堆中是否为空
public boolean isEmpty() {
return data.isEmpty();
}
//返回完全二叉树的数组表示中,一个索引所表示的元素的父亲节点的索引
private int parent(int index) {
if (index == 0) {
throw new IllegalArgumentException("index-0 doesn't have parent.");
}
return (index - 1) / 2;
}
//返回完全二叉树的数组表示中,一个索引所表示的元素的左孩子节点的索引
private int leftChild(int index) {
return index * 2 + 1;
}
//返回完全二叉树的数组表示中,一个索引所表示的元素的右孩子节点的索引
private int rightChild(int index) {
return index * 2 + 2;
}
} 向二叉堆中添加元素和 Sift Up
添加一个元素我们会在最下一排的左边开始第一个空位进行添加,如果最后一排满了,则会在新的一排进行添加。
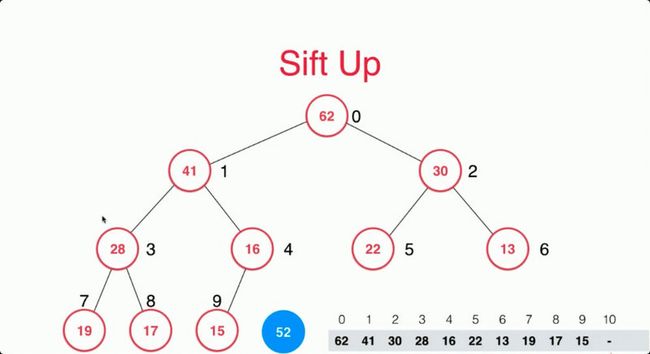
对于数组来说,我们就是在数组索引为10的位置添加52。
但是这个时候52是大于父亲节点16的,打破了堆的性质,这个时候我们需要找到52的父亲节点然后和父亲节点进行判断,如果52大于父亲节点则交换两个位置。
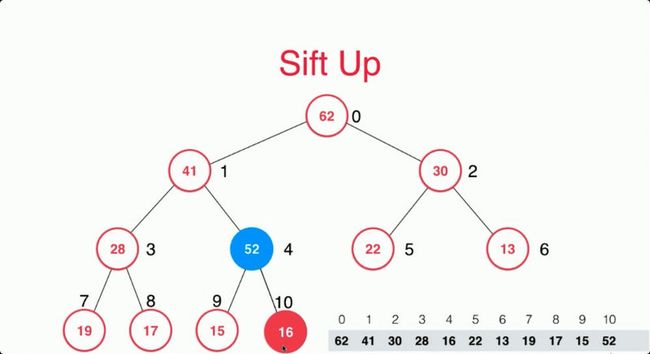
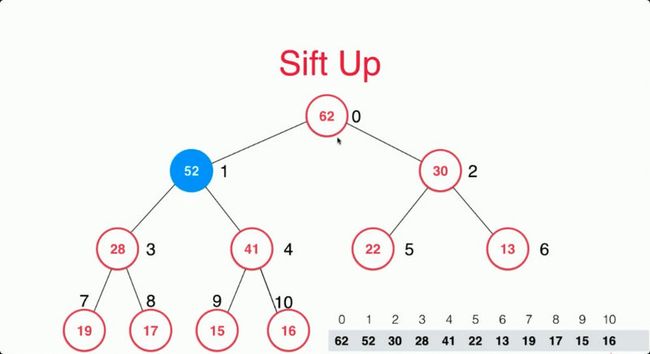
但是这个时候52又大于41节点了,所以我们需要再次交换才可以维持堆的性质。其实我们需要依次判断当前节点的父亲节点就好了。
public void add(E e){
data.addLast(e);
siftUp(data.getSize() - 1);
}
private void siftUp(int index){
while ( index > 0 && data.get(parent(index)).compareTo(data.get(index)) < 0){
//交换当前节点和父亲节点
data.swap(index,parent(index));
//将当前index改为父亲节点的索引然后继续循环
index = parent(index);
}
}
//交换两个元素的位置
public void swap(int i , int j){
if (i < 0 || i>= size || j < 0 || j >= size) {
throw new IllegalArgumentException("Index is Illegal");
}
E t = data[i];
data[i] = data[j];
data[j] = t;
}取出堆中最大元素和 Sift Down
在二叉堆中,堆顶的元素肯定就是最大元素
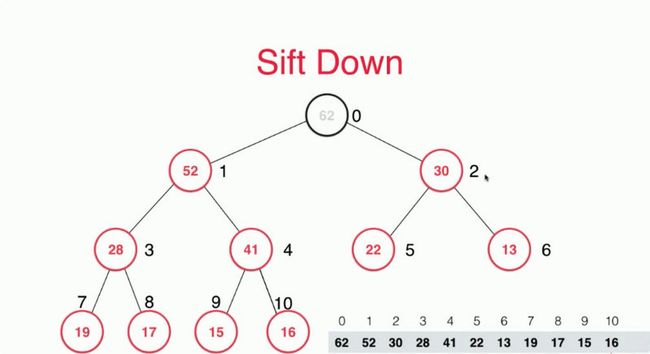
取出后最大元素后,然后我们将最后一个元素给移动到堆顶,也就是16这个元素。
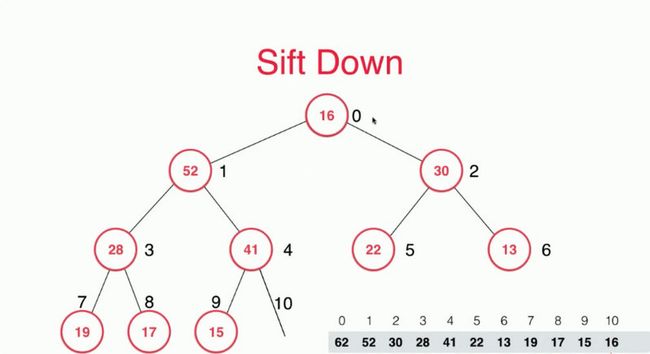
然后我们删除最后一个元素。
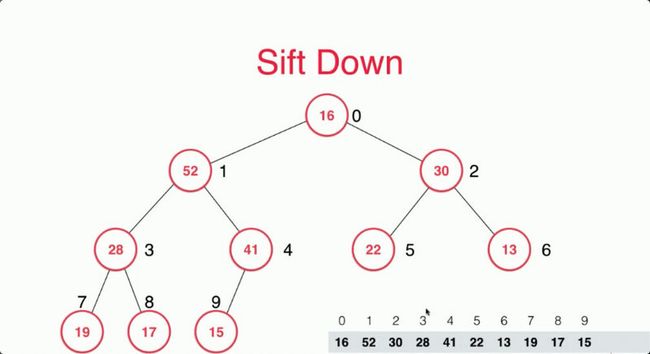
但现在问题来了,堆顶的元素打破了我们固有的性质,我们需要将堆顶的元素和他的子节点进行判断,找到子节点中最大的那个值且比本身还要大的话就进行交换。
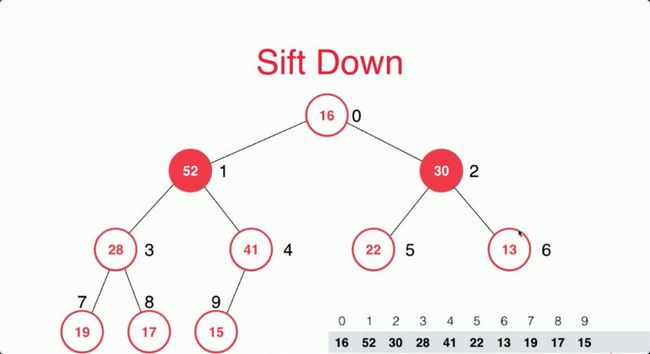
在这个例子中,我们将16和52进行交换,然后再进行子节点判断,找到最大的值且比本身还要大的话就进行交换。
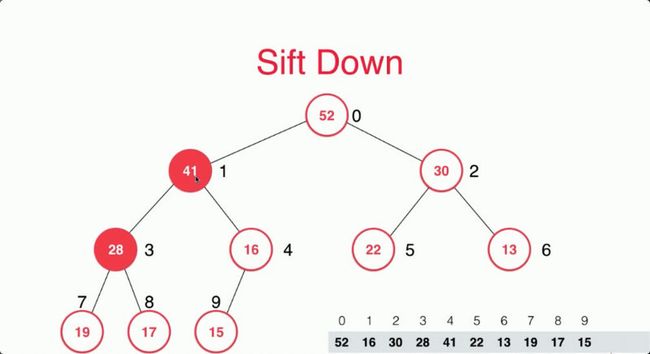
//取出最大元素
public E extractMax() {
E ret = findMax();
data.swap(0, data.getSize() - 1);
data.removeLast();
siftDown(0);
return ret;
}
private void siftDown(int index) {
//如果左孩子小于当前data的长度
while (leftChild(index) < data.getSize()) {
//获得左孩子的索引
int j = leftChild(index);
//j + 1获得右孩子索引 判断左右孩子那个大
if (j + 1 < data.getSize() && data.get(j + 1).compareTo(data.get(j)) > 0) {
//如果右孩子大则将j ++ 指向右孩子
j ++ ;
}
//判断当前索引是否大于j索引,如果大于则break,小于的话则进行交换 然后将index赋为新的节点索引
if (data.get(index).compareTo(data.get(j))>= 0) {
break;
}
data.swap(index,j);
index = j;
}
}
public E findMax() {
if (data.getSize() == 0) {
throw new IllegalArgumentException("Can not findMax when heap is empty.");
}
return data.get(0);
}Heapify和Replace
Replace:取出最大元素后,放入一个新的元素
利用我们现有的代码我们可以先调用extractMax方法,再调用add方法,两次O(logn)的操作。
不过我们可以使用更优的方案,我们直接将堆顶元素替换后直接Sift Down,这样只需要一次O(logn)的操作。
Heapify:将任意数组整理成堆的形状
我们首先需要找到最后一个非叶子节点来进行计算,蓝色的是叶子节点,而红色的就是我们需要操作的非叶子节点。
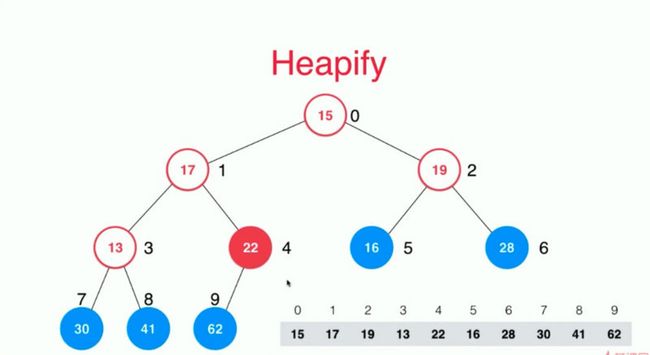
我们从后往前进行Sift Down。但是我们怎么获得到22这个节点的索引呢,其实非常简单,我们只需要拿到最后一个节点的父亲节点就是我们需要操作的第一个非叶子节点的索引。
这个时候我们拿到22进行Sift Down发现62比22要大则进行交换位置。
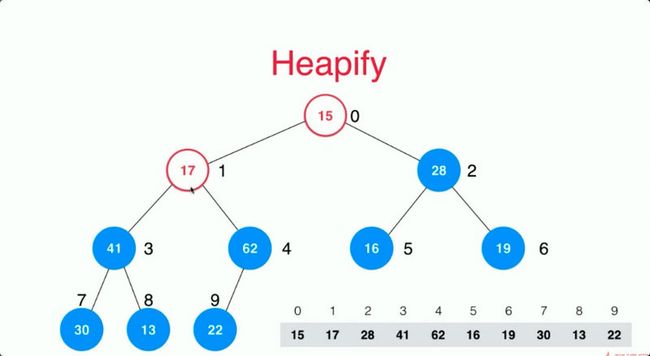
然后我们拿到62的父亲节点进行Sift Down操作,17和62进行交换,然后17又比22小所以17就到了22的位置。
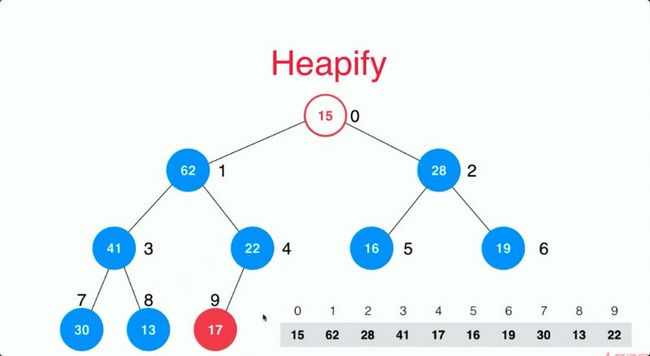
对索引为0的位置进行Sift Down操作即可。
public MaxHeap(E[] arr) {
data = new Array<>(arr);
for (int i = parent(arr.length - 1); i >= 0; i--) {
siftDown(i);
}
}
public Array(E[] arr){
data = (E[]) new Object[arr.length];
for (int i = 0; i < arr.length; i++) {
data[i] = arr[i];
}
size = arr.length;
}基于堆的优先队列
public class PriorityQueue> implements Queue {
private MaxHeap maxHeap;
public PriorityQueue(){
maxHeap = new MaxHeap<>();
}
@Override
public int getSize() {
return maxHeap.size();
}
@Override
public boolean isEmpty() {
return maxHeap.isEmpty();
}
@Override
public void enqueue(E e) {
maxHeap.add(e);
}
@Override
public E dequeue() {
return maxHeap.extractMax();
}
@Override
public E getFront() {
return maxHeap.findMax();
}
} 使用优先队列解决LeetCode 347号问题
- 前 K 个高频元素
给定一个非空的整数数组,返回其中出现频率前 k 高的元素。
示例 1:
输入: nums = [1,1,1,2,2,3], k = 2
输出: [1,2]
示例 2:输入: nums = [1], k = 1
输出: [1]提示:
你可以假设给定的 k 总是合理的,且 1 ≤ k ≤ 数组中不相同的元素的个数。
你的算法的时间复杂度必须优于 O(n log n) , n 是数组的大小。
题目数据保证答案唯一,换句话说,数组中前 k 个高频元素的集合是唯一的。
你可以按任意顺序返回答案。
/**
* leetcode 347
*/
public class Solution {
public List topKFrequent(int[] nums, int k) {
//创建一个treeMap来记录nums数组中出现的频次
TreeMap map = new TreeMap<>();
for (int num : nums) {
if (map.containsKey(num)) {
map.put(num, map.get(num) + 1);
} else {
map.put(num, 1);
}
}
PriorityQueue priorityQueue = new PriorityQueue<>();
for (Integer key : map.keySet()) {
//如果当前优先队列小于频次则添加进去
if (priorityQueue.getSize() < k) {
priorityQueue.enqueue(new Freq(key, map.get(key)));
//如果频次已满,并且取出当前的频次大于在优先队列中堆顶的频次
} else if (map.get(key) > priorityQueue.getFront().freq) {
//出队堆顶值
priorityQueue.dequeue();
//入队当前key和频次
priorityQueue.enqueue(new Freq(key, map.get(key)));
}
}
List res = new LinkedList<>();
while (!priorityQueue.isEmpty()) {
//依次出队key放入List
res.add(priorityQueue.dequeue().e);
}
return res;
}
private class Freq implements Comparable {
private int e, freq;
public Freq(int e, int freq) {
this.e = e;
this.freq = freq;
}
@Override
public int compareTo(Freq o) {
//将最小元素放在最大堆的堆顶
if (this.freq < o.freq) {
return 1;
} else if (this.freq > o.freq) {
return -1;
}
return 0;
}
}
}